SPOT: Self-Training with Patch-Order Permutation for Object-Centric Learning with Autoregressive Transformers

0
Sign in to get full access
Introduction
The paper introduces SPOT, a dual-stage strategy to enhance unsupervised object-centric learning using slot-based auto-encoders for complex real-world images. The key advancements are:
-
Improving slot generation through self-training: A self-training scheme distills slot-based attention masks from the decoder to the encoder, enhancing the encoding of object-specific information into slots.
-
Enhanced autoregressive decoders with sequence permutations: Sequence permutations alter the prediction order of the autoregressive transformer decoder, amplifying the role of slot vectors in the reconstruction process and providing a more robust supervisory signal for object-centric learning.
The combined SPOT framework outperforms previous slot-based autoencoder methods in unsupervised object segmentation, especially for complex real-world images. The self-training improves the encoder's precision in generating object-specific slots, while the sequence permutations enhance the decoder's ability to utilize these slots during reconstruction.
Related work
The paper discusses unsupervised object-centric learning, which aims to decompose multi-object scenes into meaningful object representations. Previous approaches used auto-encoding frameworks with slot-attention bottlenecks, but struggled with complex real-world scenes. Some methods focused on improving the encoder's slot-attention module, while others explored designing better decoders or utilizing self-supervised pre-trained features.
Video data, motion, depth, and text have also been incorporated into object-centric models. Contrastive frameworks have been explored for pre-training representations. Autoregressive transformer decoders, successful in natural language processing, have proven effective for object-centric learning in handling complex scenes, as seen in SLATE and STEVE. However, these decoders face training stability challenges and tend to overly rely on past ground-truth tokens.
The paper proposes a simple patch-order permutation strategy to address this issue. It also introduces self-training, a widely used technique in semi-supervised learning and domain adaptation, to the domain of unsupervised object-centric learning, demonstrating its effectiveness in this context.
Method
The paper proposes SPOT, a two-stage training method to improve object-centric representation learning using slot attention. The key components are:
-
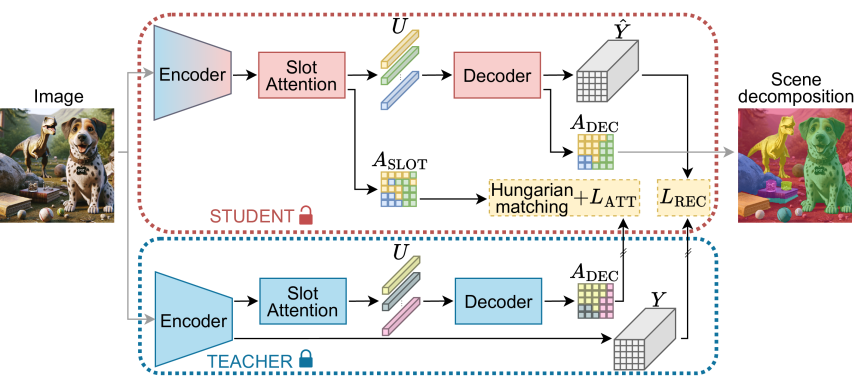
Self-training via slot-attention distillation: This involves training a student model by distilling attention masks from the decoder of a pre-trained teacher model to the slot attention module of the student. This guides the student's encoder to generate better object-centric slot representations.
-
Autoregressive transformer decoder with sequence permutations: The standard autoregressive transformer decoder predicts patches in a fixed order (left-to-right, top-to-bottom), leading to a weaker supervisory signal for earlier tokens. SPOT introduces randomly sampled sequence permutations during training to make the decoder predict patches in different orders, providing a more uniform learning signal across tokens.
The two techniques are complementary - permutations improve the teacher model in the first stage, and self-training helps stabilize fine-tuning of the image encoder in the second stage. Extensive ablation studies validate the performance gains from each component on object detection/segmentation benchmarks.
Experiments
The paper describes the experimental setup and evaluation for the proposed SPOT (Sequence-Permutation Object Transformer) method for unsupervised object-centric representation learning.
The key points are:
- Datasets used are MS COCO 2017, PASCAL VOC 2012, MOVi-C, and MOVi-E.
- Evaluation metrics are mean Best Overlap at instance (mBOi) and class (mBOc) levels, Foreground Adjusted Rand Index (FG-ARI), and mean Intersection over Union (mIoU).
- Implementation details like the optimizer, batch size, number of training epochs, and model architecture are provided.
The paper analyzes the impact of the proposed sequence permutation technique during training and the self-training loss. Sequence permutation improves instance segmentation metrics, especially when combined with self-training. Self-training stabilizes training and enables fine-tuning of the pre-trained image encoder.
The SPOT method outperforms previous unsupervised object-centric approaches across datasets, particularly on the challenging COCO dataset. The paper also explores different pre-trained encoders like DINO, MoCo-v3, and MAE, with DINO performing best overall.
Qualitative results demonstrate that SPOT mitigates over-segmentation issues while preserving detailed object segmentation.
Conclusion
The provided text is a conclusion section that summarizes the key contributions of a research paper titled "SPOT". The paper proposes an unsupervised object-centric learning method for real-world images that enhances slot-based auto-encoders through two strategies.
The first strategy is a self-training scheme that uses decoder-generated attention masks to improve slot attention in the encoder. The second strategy is a novel patch-order permutation technique for autoregressive transformers, which boosts the decoder's performance without additional training cost.
The combination of these two strategies enables SPOT to achieve state-of-the-art results in real-world object-centric learning. The authors suggest that the sequence permutation decoding technique might be beneficial for other computer vision tasks employing autoregressive decoders.
The acknowledgments section mentions that the research was supported by the Hellenic Foundation for Research and Innovation, the General Secretariat of Research and Innovation, and the RAMONES and iToBos EU Horizon 2020 projects. The authors also thank NVIDIA for the donation of GPU hardware.
Appendix A Discussion about FG-ARI unreliability

The paper highlights the limitations of the Foreground-Adjusted Rand Index (FG-ARI) metric, which has been commonly used to evaluate predicted object masks against ground-truth segmentation. Several recent works have raised concerns about the reliability of FG-ARI, criticizing it for favoring either over-segmentation or under-segmentation. Additionally, FG-ARI ignores background pixels, making it unable to assess a model's effectiveness in object segmentation accurately.
The authors demonstrate the unreliability of FG-ARI by achieving the highest score of 49.9 on the Pascal dataset by trivially assigning all pixels to a single slot-mask. This highlights the metric's limitations, particularly in datasets with scenes featuring few or single objects.
Furthermore, the paper compares the qualitative results of SPOT (the proposed method) with an autoregressive transformer decoder and an MLP-based decoder. While the standard SPOT setup outperforms the MLP decoder in mBO, mBOc, and mIoU metrics, the MLP decoder achieves a higher FG-ARI score. However, the qualitative results indicate that the MLP decoder is inferior, exhibiting notable over-segmentation and incorrect object grouping.
These observations emphasize the inadequacy of FG-ARI in measuring the segmentation quality of predicted object masks. The authors recommend that unsupervised object-centric methods should place greater reliance on mBO and mIoU metrics instead of FG-ARI.
Appendix B Additional experimental results
The paper presents a comprehensive comparison of the proposed SPOT method with prior object-centric methods across multiple datasets. SPOT outperforms other methods on metrics like mean Intersection over Union (mIoU), mean Best Overlap for instances (mBOi), and mean Best Overlap for categories (mBOc) across most datasets.
The ablation studies on the MOVi-C dataset demonstrate that self-training and sequence permutations enhance SPOT's performance, improving the mBOi by 2 points. The analysis on image encoder training stability reveals that fine-tuning the image encoder without self-training can lead to training collapse, but the issue is mitigated by using trainable initial slots and bi-level optimization. However, self-training not only boosts performance significantly but also stabilizes the training process.
The paper also presents an analysis of SPOT's performance across different instance sizes on the COCO dataset. SPOT performs optimally when instances occupy between 20% and 80% of the input image area. Performance declines for smaller instances, which is expected due to the coarse resolution of the ViT encoders used.
Visual examples are provided for SPOT's results on large, medium, and small instance sizes. The method performs well on large and medium instances but struggles with smaller ones, often grouping them together or considering them part of the background.
Appendix C Implementation details
The provided text describes implementation details of the SPOT (Slot Attention for Predictive Transformers) models used in the paper.
For the MLP decoder, a spatial broadcast mechanism expands each slot into tokens corresponding to image patches. Learnable positional information is added, and the tokens are processed by a 4-layer MLP to produce the reconstruction and an alpha map attention for each slot. The final reconstruction combines the individual slot reconstructions weighted by the alpha maps.
The SPOT models use the ViT-B/16 encoder initialized with DINO weights by default. The autoregressive transformer decoder has 4 blocks with 6 attention heads each. The MLP decoder uses 2048 hidden layer size. 3 iterations are used in the slot attention module with slot dimension 256 and MLP hidden dimension 1024.
The paper explores parallel decoding percentages of 25%, 50%, and 100%, finding 25% parallel decoding works best.
Details are provided for dataset preprocessing and evaluation metrics used on COCO, PASCAL VOC, MOVi-C, and MOVi-E datasets. The number of slots and n-block mask generation approach is described for each dataset.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
SPOT: Self-Training with Patch-Order Permutation for Object-Centric Learning with Autoregressive Transformers
Ioannis Kakogeorgiou, Spyros Gidaris, Konstantinos Karantzalos, Nikos Komodakis
Unsupervised object-centric learning aims to decompose scenes into interpretable object entities, termed slots. Slot-based auto-encoders stand out as a prominent method for this task. Within them, crucial aspects include guiding the encoder to generate object-specific slots and ensuring the decoder utilizes them during reconstruction. This work introduces two novel techniques, (i) an attention-based self-training approach, which distills superior slot-based attention masks from the decoder to the encoder, enhancing object segmentation, and (ii) an innovative patch-order permutation strategy for autoregressive transformers that strengthens the role of slot vectors in reconstruction. The effectiveness of these strategies is showcased experimentally. The combined approach significantly surpasses prior slot-based autoencoder methods in unsupervised object segmentation, especially with complex real-world images. We provide the implementation code at https://github.com/gkakogeorgiou/spot .
Read more4/8/2024

0
Masked Multi-Query Slot Attention for Unsupervised Object Discovery
Rishav Pramanik, Jos'e-Fabian Villa-V'asquez, Marco Pedersoli
Unsupervised object discovery is becoming an essential line of research for tackling recognition problems that require decomposing an image into entities, such as semantic segmentation and object detection. Recently, object-centric methods that leverage self-supervision have gained popularity, due to their simplicity and adaptability to different settings and conditions. However, those methods do not exploit effective techniques already employed in modern self-supervised approaches. In this work, we consider an object-centric approach in which DINO ViT features are reconstructed via a set of queried representations called slots. Based on that, we propose a masking scheme on input features that selectively disregards the background regions, inducing our model to focus more on salient objects during the reconstruction phase. Moreover, we extend the slot attention to a multi-query approach, allowing the model to learn multiple sets of slots, producing more stable masks. During training, these multiple sets of slots are learned independently while, at test time, these sets are merged through Hungarian matching to obtain the final slots. Our experimental results and ablations on the PASCAL-VOC 2012 dataset show the importance of each component and highlight how their combination consistently improves object localization. Our source code is available at: https://github.com/rishavpramanik/maskedmultiqueryslot
Read more5/1/2024

0
Adaptive Slot Attention: Object Discovery with Dynamic Slot Number
Ke Fan, Zechen Bai, Tianjun Xiao, Tong He, Max Horn, Yanwei Fu, Francesco Locatello, Zheng Zhang
Object-centric learning (OCL) extracts the representation of objects with slots, offering an exceptional blend of flexibility and interpretability for abstracting low-level perceptual features. A widely adopted method within OCL is slot attention, which utilizes attention mechanisms to iteratively refine slot representations. However, a major drawback of most object-centric models, including slot attention, is their reliance on predefining the number of slots. This not only necessitates prior knowledge of the dataset but also overlooks the inherent variability in the number of objects present in each instance. To overcome this fundamental limitation, we present a novel complexity-aware object auto-encoder framework. Within this framework, we introduce an adaptive slot attention (AdaSlot) mechanism that dynamically determines the optimal number of slots based on the content of the data. This is achieved by proposing a discrete slot sampling module that is responsible for selecting an appropriate number of slots from a candidate list. Furthermore, we introduce a masked slot decoder that suppresses unselected slots during the decoding process. Our framework, tested extensively on object discovery tasks with various datasets, shows performance matching or exceeding top fixed-slot models. Moreover, our analysis substantiates that our method exhibits the capability to dynamically adapt the slot number according to each instance's complexity, offering the potential for further exploration in slot attention research. Project will be available at https://kfan21.github.io/AdaSlot/
Read more6/14/2024

0
Identifiable Object-Centric Representation Learning via Probabilistic Slot Attention
Avinash Kori, Francesco Locatello, Ainkaran Santhirasekaram, Francesca Toni, Ben Glocker, Fabio De Sousa Ribeiro
Learning modular object-centric representations is crucial for systematic generalization. Existing methods show promising object-binding capabilities empirically, but theoretical identifiability guarantees remain relatively underdeveloped. Understanding when object-centric representations can theoretically be identified is crucial for scaling slot-based methods to high-dimensional images with correctness guarantees. To that end, we propose a probabilistic slot-attention algorithm that imposes an aggregate mixture prior over object-centric slot representations, thereby providing slot identifiability guarantees without supervision, up to an equivalence relation. We provide empirical verification of our theoretical identifiability result using both simple 2-dimensional data and high-resolution imaging datasets.
Read more6/12/2024