SRL: Scaling Distributed Reinforcement Learning to Over Ten Thousand Cores

0

Sign in to get full access
Overview
- This paper presents SRL (Scaling Distributed Reinforcement Learning), a system that can scale distributed reinforcement learning to over 10,000 cores.
- Reinforcement learning (RL) is a powerful machine learning technique, but scaling RL to large-scale distributed systems has been challenging.
- SRL addresses this challenge by introducing novel algorithms and system designs to enable efficient distributed RL.
Plain English Explanation
SRL: Scaling Distributed Reinforcement Learning to Over Ten Thousand Cores is a research paper that describes a system called SRL that can run reinforcement learning (RL) algorithms on a very large number of computer processors, over 10,000. RL is a way of training AI systems by rewarding them when they do the right thing, and punishing them when they do the wrong thing. This allows the AI to learn complex tasks on its own. However, scaling RL to use a huge number of processors has been very challenging in the past.
The SRL system introduces new algorithms and system designs to make distributed RL much more efficient and scalable. By distributing the RL workload across thousands of processors, SRL can solve complex problems much faster than a single computer could. This opens up the possibility of using RL to tackle problems that were previously too computationally intensive, such as optimizing power grid operations or scheduling manufacturing processes.
The key innovations in SRL include new ways of efficiently sharing data and coordinating the work of all those processors. This allows the RL algorithm to learn quickly even when running on a massive distributed system. SRL also includes techniques to make the RL training more robust and stable, which is important when scaling to such a large scale.
Technical Explanation
SRL: Scaling Distributed Reinforcement Learning to Over Ten Thousand Cores presents a system called SRL that can scale distributed reinforcement learning (RL) to over 10,000 CPU cores. The authors introduce several novel algorithms and system designs to enable efficient large-scale distributed RL.
The key innovations in SRL include:
-
Hierarchical Parameter Server: SRL uses a multi-level parameter server architecture to efficiently share parameters and gradients across thousands of workers. This hierarchical design reduces communication overhead and improves scalability.
-
Decentralized Critic Update: Rather than a centralized critic update, SRL uses a decentralized approach where each worker maintains its own local critic network. This reduces bottlenecks and improves training stability.
-
Temporal Difference Compensation: SRL incorporates a novel temporal difference compensation mechanism to mitigate the effects of staleness in the gradients due to the distributed architecture.
-
Variance Reduction Techniques: SRL employs several variance reduction techniques, such as adaptive clipping and layer-wise normalization, to stabilize the RL training process at scale.
The authors evaluate SRL on several benchmarks, including OpenAI RLHF, Mujoco, and Atari environments. They demonstrate that SRL can scale to over 10,000 CPU cores while maintaining high sample efficiency and performance, outperforming previous distributed RL approaches.
Critical Analysis
The SRL paper presents an impressive system that can scale distributed RL to an unprecedented level. However, the authors do acknowledge some potential limitations and areas for future work:
-
Hardware Dependence: The current SRL implementation relies on specialized hardware, such as high-speed interconnects, which may limit its applicability in more resource-constrained environments.
-
Complexity and Overhead: The hierarchical parameter server and other SRL components add complexity and communication overhead, which could impact performance on certain problem domains or hardware configurations.
-
Generalization and Robustness: While SRL demonstrates strong performance on the evaluated benchmarks, further research is needed to assess its generalization capabilities and robustness to different problem settings and environments.
-
Energy Efficiency: The high-scale distributed nature of SRL raises questions about its energy efficiency, which is an important consideration for real-world deployments, especially in domains like power grid optimization.
Despite these potential limitations, the SRL system represents a significant advancement in the field of large-scale distributed RL. The authors' innovative algorithms and system designs open up new possibilities for applying RL to tackle complex, computationally intensive problems that were previously intractable.
Conclusion
The SRL paper presents a groundbreaking system that can scale distributed reinforcement learning to over 10,000 CPU cores. By introducing novel algorithms and system designs, the authors have addressed many of the challenges that have historically limited the scalability of RL.
The ability to harness the power of massive distributed systems for RL has far-reaching implications. It enables the use of RL in applications that were previously too computationally demanding, such as optimizing power grid operations, scheduling manufacturing processes, and training more advanced AI agents. As the field of RL continues to evolve, systems like SRL will play a crucial role in unlocking the full potential of this powerful machine learning technique.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
SRL: Scaling Distributed Reinforcement Learning to Over Ten Thousand Cores
Zhiyu Mei, Wei Fu, Jiaxuan Gao, Guangju Wang, Huanchen Zhang, Yi Wu
The ever-growing complexity of reinforcement learning (RL) tasks demands a distributed system to efficiently generate and process a massive amount of data. However, existing open-source libraries suffer from various limitations, which impede their practical use in challenging scenarios where large-scale training is necessary. In this paper, we present a novel abstraction on the dataflows of RL training, which unifies diverse RL training applications into a general framework. Following this abstraction, we develop a scalable, efficient, and extensible distributed RL system called ReaLlyScalableRL, which allows efficient and massively parallelized training and easy development of customized algorithms. Our evaluation shows that SRL outperforms existing academic libraries, reaching at most 21x higher training throughput in a distributed setting. On learning performance, beyond performing and scaling well on common RL benchmarks with different RL algorithms, SRL can reproduce the same solution in the challenging hide-and-seek environment as reported by OpenAI with up to 5x speedup in wall-clock time. Notably, SRL is the first in the academic community to perform RL experiments at a large scale with over 15k CPU cores. SRL source code is available at: https://github.com/openpsi-project/srl .
Read more6/24/2024

0
New!A Scalable and Parallelizable Digital Twin Framework for Sustainable Sim2Real Transition of Multi-Agent Reinforcement Learning Systems
Chinmay Vilas Samak, Tanmay Vilas Samak, Venkat Krovi
Multi-agent reinforcement learning (MARL) systems usually require significantly long training times due to their inherent complexity. Furthermore, deploying them in the real world demands a feature-rich environment along with multiple embodied agents, which may not be feasible due to budget or space limitations, not to mention energy consumption and safety issues. This work tries to address these pain points by presenting a sustainable digital twin framework capable of accelerating MARL training by selectively scaling parallelized workloads on-demand, and transferring the trained policies from simulation to reality using minimal hardware resources. The applicability of the proposed digital twin framework is highlighted through two representative use cases, which cover cooperative as well as competitive classes of MARL problems. We study the effect of agent and environment parallelization on training time and that of systematic domain randomization on zero-shot sim2real transfer across both the case studies. Results indicate up to 76.3% reduction in training time with the proposed parallelization scheme and as low as 2.9% sim2real gap using the suggested deployment method.
Read more9/17/2024

0
OpenRLHF: An Easy-to-use, Scalable and High-performance RLHF Framework
Jian Hu, Xibin Wu, Weixun Wang, Xianyu, Dehao Zhang, Yu Cao
As large language models (LLMs) continue to grow by scaling laws, reinforcement learning from human feedback (RLHF) has gained significant attention due to its outstanding performance. However, unlike pretraining or fine-tuning a single model, scaling reinforcement learning from human feedback (RLHF) for training large language models poses coordination challenges across four models. We present OpenRLHF, an open-source framework enabling efficient RLHF scaling. Unlike existing RLHF frameworks that co-locate four models on the same GPUs, OpenRLHF re-designs scheduling for the models beyond 70B parameters using Ray, vLLM, and DeepSpeed, leveraging improved resource utilization and diverse training approaches. Integrating seamlessly with Hugging Face, OpenRLHF provides an out-of-the-box solution with optimized algorithms and launch scripts, which ensures user-friendliness. OpenRLHF implements RLHF, DPO, rejection sampling, and other alignment techniques. Empowering state-of-the-art LLM development, OpenRLHF's code is available at url{https://github.com/OpenRLHF/OpenRLHF}.
Read more7/18/2024
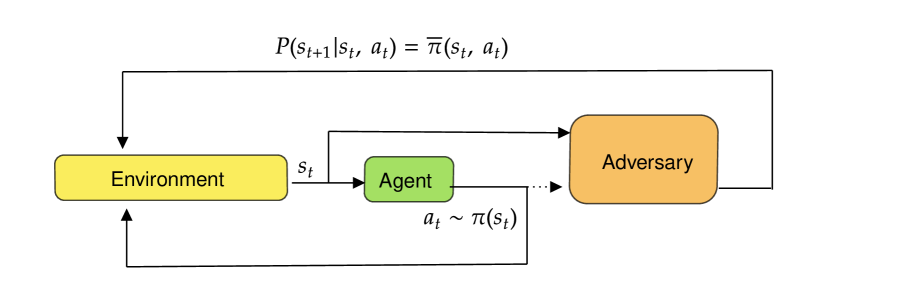
0
RRLS : Robust Reinforcement Learning Suite
Adil Zouitine, David Bertoin, Pierre Clavier, Matthieu Geist, Emmanuel Rachelson
Robust reinforcement learning is the problem of learning control policies that provide optimal worst-case performance against a span of adversarial environments. It is a crucial ingredient for deploying algorithms in real-world scenarios with prevalent environmental uncertainties and has been a long-standing object of attention in the community, without a standardized set of benchmarks. This contribution endeavors to fill this gap. We introduce the Robust Reinforcement Learning Suite (RRLS), a benchmark suite based on Mujoco environments. RRLS provides six continuous control tasks with two types of uncertainty sets for training and evaluation. Our benchmark aims to standardize robust reinforcement learning tasks, facilitating reproducible and comparable experiments, in particular those from recent state-of-the-art contributions, for which we demonstrate the use of RRLS. It is also designed to be easily expandable to new environments. The source code is available at href{https://github.com/SuReLI/RRLS}{https://github.com/SuReLI/RRLS}.
Read more6/13/2024