Stabilizing Sharpness-aware Minimization Through A Simple Renormalization Strategy

0
Sign in to get full access
Overview
- The paper presents a simple renormalization strategy to stabilize Sharpness-Aware Minimization (SAM), a technique that aims to improve the generalization performance of deep neural networks.
- SAM optimizes the model parameters to minimize both the loss function and the sensitivity of the loss to small perturbations in the parameters, which can lead to improved generalization.
- However, the original SAM algorithm can be unstable and sensitive to hyperparameter settings, which this paper addresses.
Plain English Explanation
The paper focuses on a technique called Sharpness-Aware Minimization (SAM), which is designed to help deep neural networks generalize better.
Typically, when training a neural network, the goal is to minimize the loss function on the training data. However, this can sometimes lead to a model that is "overfitted" to the training data and doesn't perform well on new, unseen data.
SAM tries to address this by not only minimizing the loss function, but also minimizing the "sharpness" of the loss function. The sharpness refers to how quickly the loss function changes around the current parameter values. A loss function with low sharpness means the model is less sensitive to small changes in the parameters, which can lead to better generalization.
While SAM is a promising approach, the original algorithm can be unstable and sensitive to the choice of hyperparameters (the settings you have to choose when training the model). This paper proposes a simple modification to the SAM algorithm, called "Stabilizing Sharpness-Aware Minimization Through A Simple Renormalization Strategy", that helps make the algorithm more stable and less sensitive to hyperparameter settings.
Technical Explanation
The paper introduces a simple modification to the Sharpness-Aware Minimization (SAM) algorithm to improve its stability and robustness to hyperparameter settings.
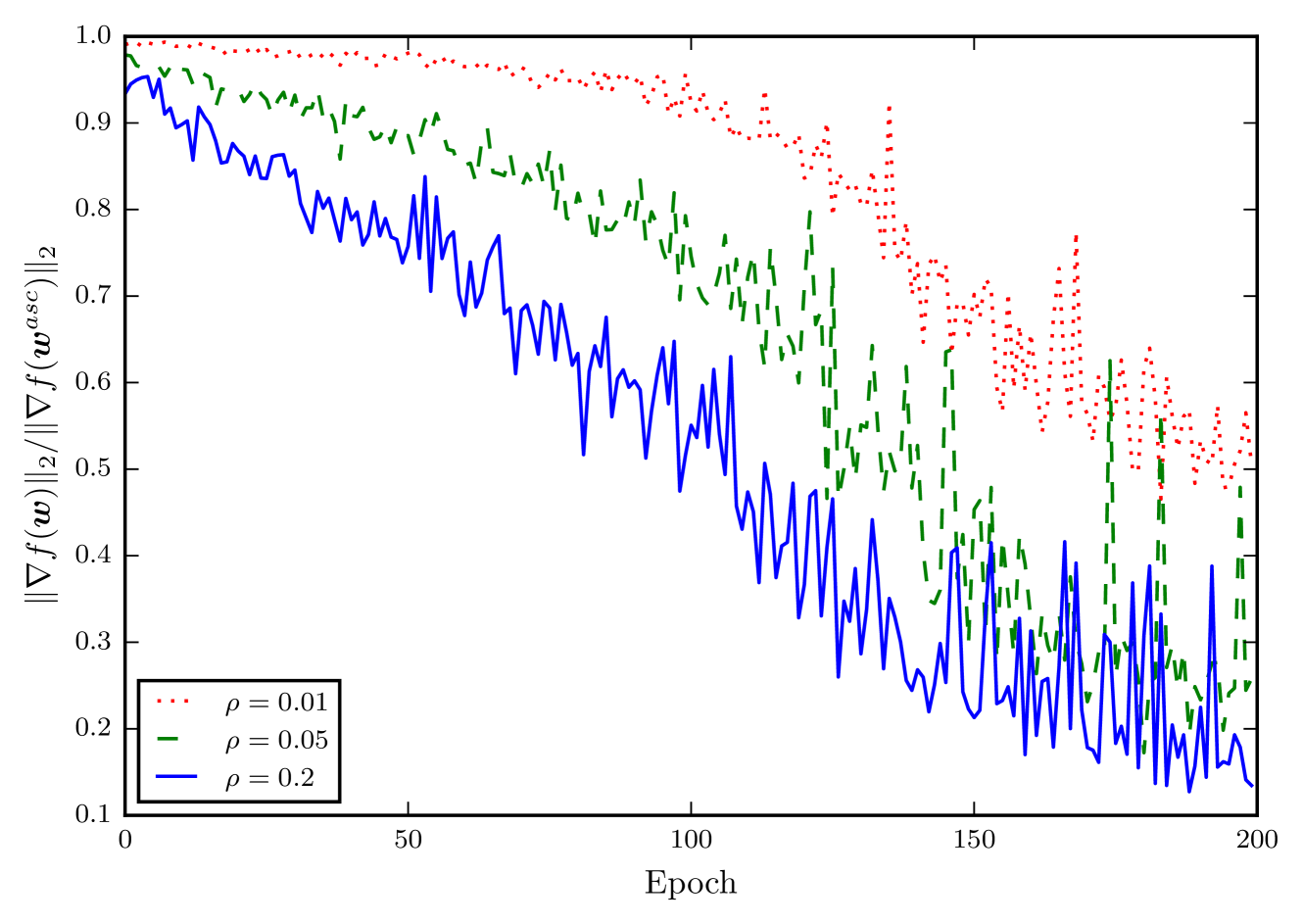
The key idea is to apply a simple renormalization step to the perturbation vector used in the SAM algorithm. Specifically, the authors propose normalizing the perturbation vector by its L2 norm before applying it to the model parameters. This helps ensure that the perturbation magnitude remains within a reasonable range, even as the training progresses and the model parameters change.
The authors demonstrate the effectiveness of their approach through extensive experiments on various image classification tasks and language modeling tasks. They show that their modified SAM algorithm, called "Stabilizing Sharpness-Aware Minimization Through A Simple Renormalization Strategy", outperforms the original SAM algorithm in terms of both stability and generalization performance.
The authors also provide theoretical insights into why the renormalization step helps stabilize the SAM algorithm. They show that the renormalization step reduces the variance of the gradient updates, leading to more stable and consistent optimization.
Critical Analysis
The paper presents a simple yet effective modification to the Sharpness-Aware Minimization (SAM) algorithm, which addresses a key limitation of the original algorithm – its instability and sensitivity to hyperparameter settings.
One potential limitation of the paper is that it does not explore the impact of the renormalization strategy on the overall training time and computational overhead. While the authors demonstrate improved stability and generalization performance, it would be helpful to understand the trade-offs in terms of training efficiency.
Additionally, the paper focuses on a specific set of image classification and language modeling tasks. It would be interesting to see how the proposed approach performs on a wider range of tasks and domains, particularly in areas where the original SAM algorithm has been shown to be effective, such as natural language processing and graph neural networks.
Overall, the paper makes a valuable contribution to the literature on sharpness-aware optimization, and the proposed renormalization strategy could be a useful tool for researchers and practitioners looking to improve the robustness and performance of their deep learning models.
Conclusion
The paper introduces a simple renormalization strategy to stabilize the Sharpness-Aware Minimization (SAM) algorithm, a technique for improving the generalization performance of deep neural networks. The authors show that their modified SAM algorithm, called "Stabilizing Sharpness-Aware Minimization Through A Simple Renormalization Strategy", outperforms the original SAM algorithm in terms of both stability and generalization performance across a range of image classification and language modeling tasks.
The key contribution of the paper is the introduction of a simple normalization step that helps ensure the perturbation magnitude used in the SAM algorithm remains within a reasonable range, leading to more stable and consistent optimization. The authors provide both empirical and theoretical insights into why this renormalization strategy is effective.
While the paper focuses on a specific set of tasks, the proposed approach could have broader implications for the development of more robust and generalization-friendly deep learning models, particularly in domains where the original SAM algorithm has shown promise.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Stabilizing Sharpness-aware Minimization Through A Simple Renormalization Strategy
Chengli Tan, Jiangshe Zhang, Junmin Liu, Yicheng Wang, Yunda Hao
Recently, sharpness-aware minimization (SAM) has attracted much attention because of its surprising effectiveness in improving generalization performance. However, compared to stochastic gradient descent (SGD), it is more prone to getting stuck at the saddle points, which as a result may lead to performance degradation. To address this issue, we propose a simple renormalization strategy, dubbed Stable SAM (SSAM), so that the gradient norm of the descent step maintains the same as that of the ascent step. Our strategy is easy to implement and flexible enough to integrate with SAM and its variants, almost at no computational cost. With elementary tools from convex optimization and learning theory, we also conduct a theoretical analysis of sharpness-aware training, revealing that compared to SGD, the effectiveness of SAM is only assured in a limited regime of learning rate. In contrast, we show how SSAM extends this regime of learning rate and then it can consistently perform better than SAM with the minor modification. Finally, we demonstrate the improved performance of SSAM on several representative data sets and tasks.
Read more9/11/2024

0
Sharpness-Aware Minimization Enhances Feature Quality via Balanced Learning
Jacob Mitchell Springer, Vaishnavh Nagarajan, Aditi Raghunathan
Sharpness-Aware Minimization (SAM) has emerged as a promising alternative optimizer to stochastic gradient descent (SGD). The originally-proposed motivation behind SAM was to bias neural networks towards flatter minima that are believed to generalize better. However, recent studies have shown conflicting evidence on the relationship between flatness and generalization, suggesting that flatness does fully explain SAM's success. Sidestepping this debate, we identify an orthogonal effect of SAM that is beneficial out-of-distribution: we argue that SAM implicitly balances the quality of diverse features. SAM achieves this effect by adaptively suppressing well-learned features which gives remaining features opportunity to be learned. We show that this mechanism is beneficial in datasets that contain redundant or spurious features where SGD falls for the simplicity bias and would not otherwise learn all available features. Our insights are supported by experiments on real data: we demonstrate that SAM improves the quality of features in datasets containing redundant or spurious features, including CelebA, Waterbirds, CIFAR-MNIST, and DomainBed.
Read more6/3/2024

0
Efficient Sharpness-Aware Minimization for Molecular Graph Transformer Models
Yili Wang, Kaixiong Zhou, Ninghao Liu, Ying Wang, Xin Wang
Sharpness-aware minimization (SAM) has received increasing attention in computer vision since it can effectively eliminate the sharp local minima from the training trajectory and mitigate generalization degradation. However, SAM requires two sequential gradient computations during the optimization of each step: one to obtain the perturbation gradient and the other to obtain the updating gradient. Compared with the base optimizer (e.g., Adam), SAM doubles the time overhead due to the additional perturbation gradient. By dissecting the theory of SAM and observing the training gradient of the molecular graph transformer, we propose a new algorithm named GraphSAM, which reduces the training cost of SAM and improves the generalization performance of graph transformer models. There are two key factors that contribute to this result: (i) textit{gradient approximation}: we use the updating gradient of the previous step to approximate the perturbation gradient at the intermediate steps smoothly (textbf{increases efficiency}); (ii) textit{loss landscape approximation}: we theoretically prove that the loss landscape of GraphSAM is limited to a small range centered on the expected loss of SAM (textbf{guarantees generalization performance}). The extensive experiments on six datasets with different tasks demonstrate the superiority of GraphSAM, especially in optimizing the model update process. The code is in:https://github.com/YL-wang/GraphSAM/tree/graphsam
Read more6/21/2024

0
Sharpness-Aware Minimization and the Edge of Stability
Philip M. Long, Peter L. Bartlett
Recent experiments have shown that, often, when training a neural network with gradient descent (GD) with a step size $eta$, the operator norm of the Hessian of the loss grows until it approximately reaches $2/eta$, after which it fluctuates around this value. The quantity $2/eta$ has been called the edge of stability based on consideration of a local quadratic approximation of the loss. We perform a similar calculation to arrive at an edge of stability for Sharpness-Aware Minimization (SAM), a variant of GD which has been shown to improve its generalization. Unlike the case for GD, the resulting SAM-edge depends on the norm of the gradient. Using three deep learning training tasks, we see empirically that SAM operates on the edge of stability identified by this analysis.
Read more4/10/2024