State-Compute Replication: Parallelizing High-Speed Stateful Packet Processing
2309.14647
2
0
⚙️
Abstract
With the slowdown of Moore's law, CPU-oriented packet processing in software will be significantly outpaced by emerging line speeds of network interface cards (NICs). Single-core packet-processing throughput has saturated. We consider the problem of high-speed packet processing with multiple CPU cores. The key challenge is state--memory that multiple packets must read and update. The prevailing method to scale throughput with multiple cores involves state sharding, processing all packets that update the same state, i.e., flow, at the same core. However, given the heavy-tailed nature of realistic flow size distributions, this method will be untenable in the near future, since total throughput is severely limited by single core performance. This paper introduces state-compute replication, a principle to scale the throughput of a single stateful flow across multiple cores using replication. Our design leverages a packet history sequencer running on a NIC or top-of-the-rack switch to enable multiple cores to update state without explicit synchronization. Our experiments with realistic data center and wide-area Internet traces shows that state-compute replication can scale total packet-processing throughput linearly with cores, deterministically and independent of flow size distributions, across a range of realistic packet-processing programs.
Create account to get full access
Overview
- The paper discusses the challenge of high-speed packet processing using multiple CPU cores as network interface card (NIC) speeds outpace single-core packet-processing throughput.
- The traditional approach of state sharding, where packets that update the same state are processed on the same core, is limited by single-core performance and the heavy-tailed nature of realistic flow size distributions.
- The paper introduces a new principle called "state-compute replication" to scale the throughput of a single stateful flow across multiple cores using replication.
Plain English Explanation
As network speeds continue to increase, traditional CPU-based packet processing is struggling to keep up. The paper explores a solution to this problem by using multiple CPU cores to process packets in parallel. The key challenge is managing the shared state, or memory, that multiple packets need to read and update.
The prevailing approach has been to assign all packets that update the same state, such as a particular network flow, to the same core. However, this method is becoming increasingly problematic due to the fact that in reality, the size of network flows follows a heavy-tailed distribution, meaning there are a few very large flows and many small ones. As a result, the throughput of the entire system is limited by the performance of the single core handling the largest flows.
To address this issue, the paper introduces a new concept called "state-compute replication." The idea is to allow multiple cores to update the state for a single flow simultaneously, without the need for explicit synchronization. This is achieved by using a "packet history sequencer" running on the NIC or a top-of-the-rack switch, which coordinates the updates across the cores.
Through experiments with realistic data center and internet traffic traces, the researchers demonstrate that state-compute replication can scale the total packet-processing throughput linearly with the number of cores, regardless of the flow size distribution. This represents a significant improvement over the existing state sharding approach.
Technical Explanation
The paper proposes a new principle called "state-compute replication" to address the challenge of high-speed packet processing using multiple CPU cores. The key idea is to enable multiple cores to update the state for a single stateful flow without the need for explicit synchronization.
This is achieved by leveraging a "packet history sequencer" running on a NIC or top-of-the-rack switch. The sequencer maintains a history of packet updates and coordinates the state updates across the multiple cores. This allows the cores to work independently on the same flow, scaling the throughput linearly with the number of cores.
The researchers evaluated their approach using realistic data center and wide-area internet traffic traces, covering a range of packet-processing programs. The results show that state-compute replication can scale the total packet-processing throughput deterministically and independently of the flow size distribution, a significant improvement over the traditional state sharding method.
Critical Analysis
The paper presents a promising solution to the growing challenge of high-speed packet processing in the face of increasing NIC speeds and the limitations of single-core performance. The state-compute replication approach addresses the key bottleneck of state management, which has been a major obstacle to scaling packet processing with multiple cores.
One potential limitation of the proposed approach is the reliance on a dedicated packet history sequencer running on the NIC or a top-of-the-rack switch. This additional hardware component may introduce complexity and cost that could be a barrier to adoption in some scenarios. It would be interesting to explore alternative designs that could achieve similar benefits without requiring specialized hardware.
Additionally, the paper's evaluation is based on realistic traffic traces, which is a strength. However, it would be valuable to further stress-test the approach under more extreme conditions, such as highly skewed flow size distributions or sudden traffic spikes, to better understand its robustness and potential failure modes.
Overall, the state-compute replication principle represents a significant advancement in the field of high-speed packet processing and is likely to have important implications for the design of future network infrastructure and data center architectures. Further research and refinement of the approach could lead to even more practical and scalable solutions.
Conclusion
The paper introduces a novel "state-compute replication" principle to address the challenge of high-speed packet processing in the face of increasing NIC speeds and the limitations of single-core CPU performance. By leveraging a packet history sequencer to coordinate state updates across multiple cores, the approach can scale the total packet-processing throughput linearly, overcoming the shortcomings of traditional state sharding methods.
The experimental results using realistic traffic traces demonstrate the effectiveness of this approach, which could have significant implications for the design of future network infrastructure and data center architectures. While the reliance on specialized hardware may be a potential limitation, the state-compute replication principle represents an important step forward in the quest to keep up with the ever-increasing demands on network throughput and performance.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
Flow Optimization at Inter-Datacenter Networks for Application Run-time Acceleration
Berta Serracanta, Alberto Rodriguez-Natal, Fabio Maino, Albert Cabellos
0
0
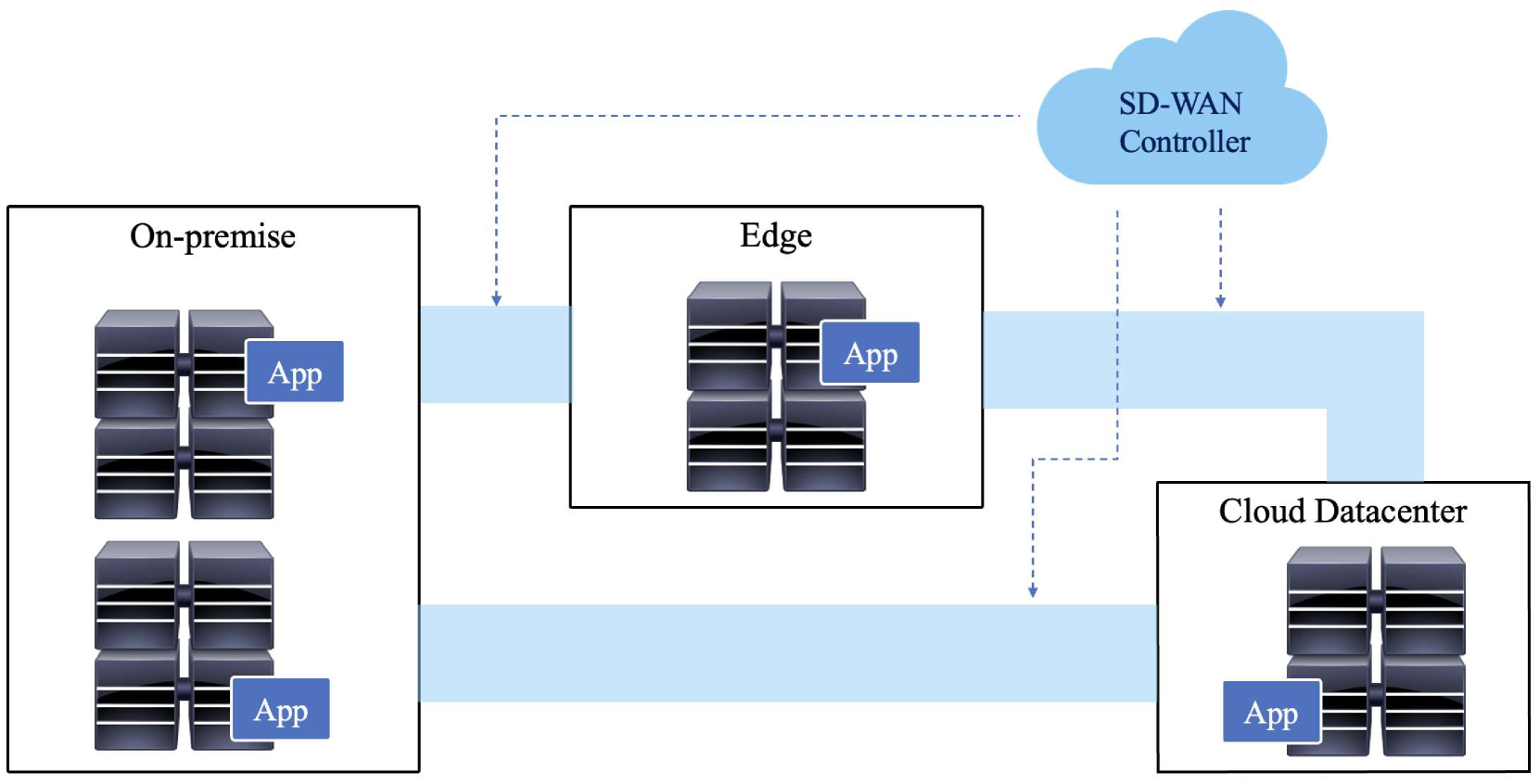
In the present-day, distributed applications are commonly spread across multiple datacenters, reaching out to edge and fog computing locations. The transition away from single datacenter hosting is driven by capacity constraints in datacenters and the adoption of hybrid deployment strategies, combining on-premise and public cloud facilities. However, the performance of such applications is often limited by extended Flow Completion Times (FCT) for short flows due to queuing behind bursts of packets from concurrent long flows. To address this challenge, we propose a solution to prioritize short flows over long flows in the Software-Defined Wide-Area Network (SD-WAN) interconnecting the distributed computing platforms. Our solution utilizes eBPF to segregate short and long flows, transmitting them over separate tunnels with the same properties. By effectively mitigating queuing delays, we consistently achieve a 1.5 times reduction in FCT for short flows, resulting in improved application response times. The proposed solution works with encrypted traffic and is application-agnostic, making it deployable in diverse distributed environments without modifying the applications themselves. Our testbed evaluation demonstrates the effectiveness of our approach in accelerating the run-time of distributed applications, providing valuable insights for optimizing multi-datacenter and edge deployments.
6/19/2024

Feasibility of State Space Models for Network Traffic Generation
Andrew Chu, Xi Jiang, Shinan Liu, Arjun Bhagoji, Francesco Bronzino, Paul Schmitt, Nick Feamster
0
0
Many problems in computer networking rely on parsing collections of network traces (e.g., traffic prioritization, intrusion detection). Unfortunately, the availability and utility of these collections is limited due to privacy concerns, data staleness, and low representativeness. While methods for generating data to augment collections exist, they often fall short in replicating the quality of real-world traffic In this paper, we i) survey the evolution of traffic simulators/generators and ii) propose the use of state-space models, specifically Mamba, for packet-level, synthetic network trace generation by modeling it as an unsupervised sequence generation problem. Early evaluation shows that state-space models can generate synthetic network traffic with higher statistical similarity to real traffic than the state-of-the-art. Our approach thus has the potential to reliably generate realistic, informative synthetic network traces for downstream tasks.
6/6/2024
Quantum Circuit Switching with One-Way Repeaters in Star Networks
'Alvaro G. I~nesta, Hyeongrak Choi, Dirk Englund, Stephanie Wehner
0
0
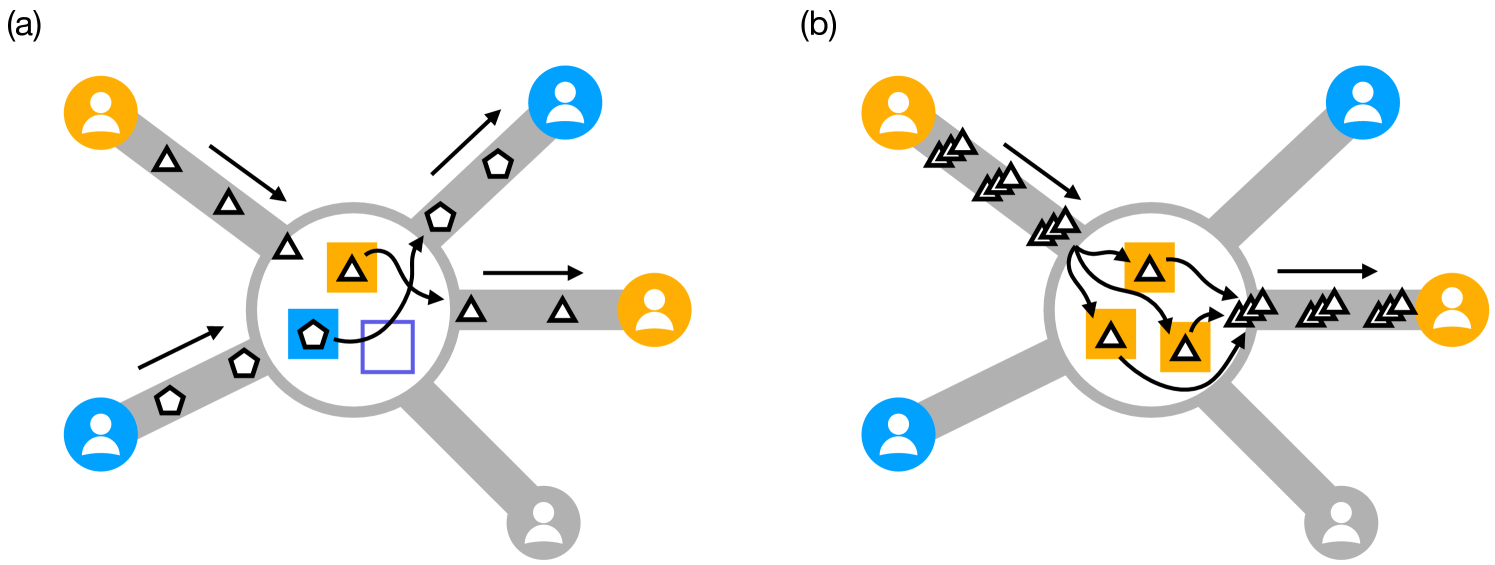
Distributing quantum states reliably among distant locations is a key challenge in the field of quantum networks. One-way quantum networks address this by using one-way communication and quantum error correction. Here, we analyze quantum circuit switching as a protocol to distribute quantum states in one-way quantum networks. In quantum circuit switching, pairs of users can request the delivery of multiple quantum states from one user to the other. After waiting for approval from the network, the states can be distributed either sequentially, forwarding one at a time along a path of quantum repeaters, or in parallel, sending batches of quantum states from repeater to repeater. Since repeaters can only forward a finite number of quantum states at a time, a pivotal question arises: is it advantageous to send them sequentially (allowing for multiple requests simultaneously) or in parallel (reducing processing time but handling only one request at a time)? We compare both approaches in a quantum network with a star topology. Using tools from queuing theory, we show that requests are met at a higher rate when packets are distributed in parallel, although sequential distribution can generally provide service to a larger number of users simultaneously. We also show that using a large number of quantum repeaters to combat channel losses limits the maximum distance between users, as each repeater introduces additional processing delays. These findings provide insight into the design of protocols for distributing quantum states in one-way quantum networks.
5/30/2024
Queue-aware Network Control Algorithm with a High Quantum Computing Readiness-Evaluated in Discrete-time Flow Simulator for Fat-Pipe Networks
Arthur Witt
0
0
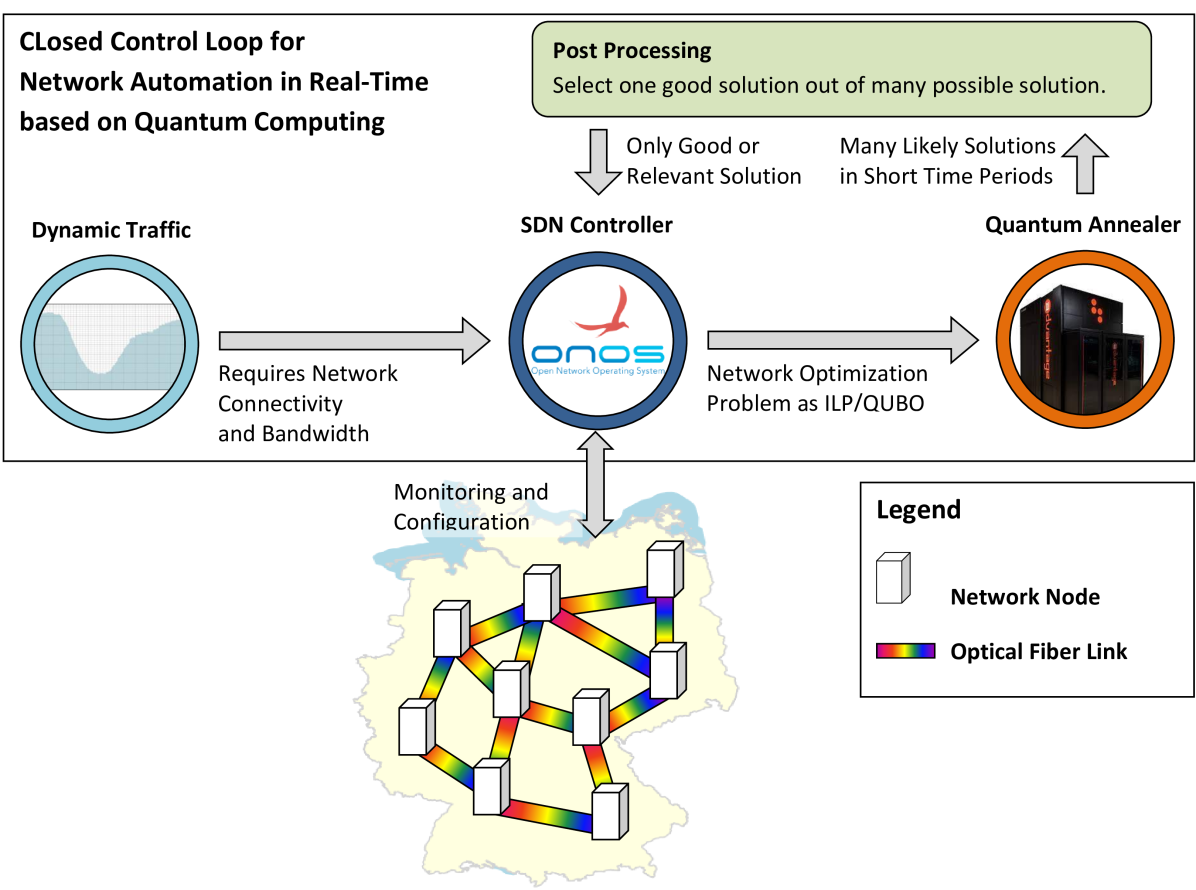
The emerging technology of quantum computing has the potential to change the way how problems will be solved in the future. This work presents a centralized network control algorithm executable on already existing quantum computer which are based on the principle of quantum annealing like the D-Wave Advantage. We introduce a resource reoccupation algorithm for traffic engineering in wide-area networks. The proposed optimization algorithm changes traffic steering and resource allocation in case of overloaded transceivers. Settings of active components like fiber amplifiers and transceivers are not changed for the reason of stability. This algorithm is beneficial in situations when the network traffic is fluctuating in time scales of seconds or spontaneous bursts occur. Further, we developed a discrete-time flow simulator to study the algorithm's performance in wide-area networks. Our network simulator considers backlog and loss modeling of buffered transmission lines. Concurring flows are handled equally in case of a backlog. This work provides an ILP-based network configuring algorithm that is applicable on quantum annealing computers. We showcase, that traffic losses can be reduced significantly by a factor of 2 if a resource reoccupation algorithm is applied in a network with bursty traffic. As resources are used more efficiently by reoccupation in heavy load situations, overprovisioning of networks can be reduced. Thus, this new form of network operation leads toward a zero-margin network. We show that our newly introduced network simulator enables analyses of short-time effects like buffering within fat-pipe networks. As the calculation of network configurations in real-sized networks is typically time-consuming, quantum computing can enable the proposed network configuration algorithm for application in real-sized wide-area networks.
5/21/2024