Static Generation of Efficient OpenMP Offload Data Mappings

0

Sign in to get full access
Overview
- This paper presents a static approach for generating efficient data mappings for OpenMP offload directives, which are used to run code on accelerator devices like GPUs.
- The authors propose a new compiler-based technique to automatically generate the necessary data transfer commands between the CPU and GPU memory, optimizing performance.
- The approach aims to reduce the overhead associated with manual data mapping and improve the productivity of programming heterogeneous systems with OpenMP.
Plain English Explanation
The paper discusses a way to make it easier to use OpenMP, a popular programming tool, to run code on powerful GPU (graphics processing unit) accelerators. When you want to run a piece of code on a GPU, you need to carefully manage the data - you have to explicitly copy data from the main computer memory to the GPU memory, and then copy the results back. This data copying process can be time-consuming and error-prone, especially for complex programs.
The researchers developed a new compiler-based technique that can automatically generate the necessary data transfer commands. This means programmers don't have to manually figure out how to move the data back and forth - the compiler does it for them, optimizing the performance. The goal is to reduce the overhead of using GPUs and make it easier for programmers to take advantage of these powerful accelerators when writing their code.
By automating the data mapping process, the approach aims to improve the productivity of programming heterogeneous systems (systems with both CPUs and GPUs) using OpenMP. This could make it simpler for a wider range of developers to harness the power of GPUs in their applications.
Technical Explanation
The paper presents a static, compiler-driven approach for generating efficient data mappings to support OpenMP offload directives. OpenMP offload directives allow programmers to mark sections of code to be executed on an accelerator device, such as a GPU. However, manually managing the data transfers between the host (CPU) and the device (GPU) memory can be complex and error-prone.
The authors propose a new compiler-based technique that automatically generates the necessary data transfer commands. The key idea is to perform a static analysis of the OpenMP offload regions and use this information to determine the optimal data mappings. The compiler first identifies the data that needs to be transferred and then generates efficient data movement commands, considering factors like data reuse and data padding.
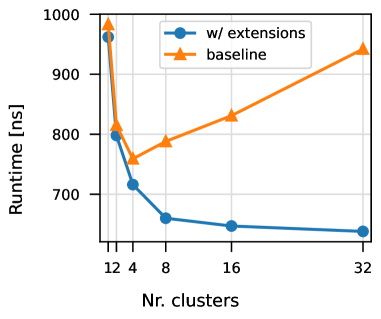
The researchers implemented their approach in the LLVM compiler infrastructure and evaluated it on a set of OpenMP offload benchmarks. The results show that their technique can achieve significant performance improvements over manually specified data mappings, with speedups ranging from 1.2x to 4.3x. The benefits are especially pronounced for more complex applications with irregular memory access patterns.
Critical Analysis
The paper presents a compelling approach for improving the productivity and performance of programming heterogeneous systems using OpenMP. By automating the data mapping process, the proposed technique addresses a key challenge in leveraging accelerators like GPUs.
One potential limitation is that the static analysis approach may not be able to capture all the dynamic behavior of the program, especially for highly irregular or data-dependent control flow. The authors acknowledge this and suggest combining their technique with runtime adaptation strategies as an area for future work.
Additionally, the evaluation is focused on a relatively small set of benchmarks, and it would be valuable to see how the approach scales to larger, more complex real-world applications. Further research could also explore the generalization of the technique to other programming models or accelerator architectures beyond OpenMP and GPUs.
Overall, the paper makes a strong contribution by demonstrating the potential of compiler-driven techniques to simplify the use of heterogeneous hardware and bridge the gap between high-level programming models and efficient low-level implementations.
Conclusion
This paper presents a novel static approach for generating efficient data mappings to support OpenMP offload directives. By automatically determining the necessary data transfers between the host and device memory, the proposed technique can significantly improve the performance and productivity of programming heterogeneous systems.
The key innovation is the compiler-driven analysis that leverages the structure of the OpenMP offload regions to generate optimized data movement commands. The evaluation results show that this approach can achieve substantial speedups compared to manual data mapping, particularly for more complex applications.
The work highlights the importance of addressing the data management challenges in heterogeneous programming and demonstrates the potential for compiler-based techniques to simplify the use of accelerators like GPUs. As the complexity of modern hardware continues to grow, approaches like the one presented in this paper will become increasingly crucial for enabling a wider range of developers to harness the power of these powerful computing resources.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Static Generation of Efficient OpenMP Offload Data Mappings
Luke Marzen, Akash Dutta, Ali Jannesari
Increasing heterogeneity in HPC architectures and compiler advancements have led to OpenMP being frequently used to enable computations on heterogeneous devices. However, the efficient movement of data on heterogeneous computing platforms is crucial for achieving high utilization. Programmers must explicitly map data between the host and connected accelerator devices to achieve efficient data movement. Ensuring efficient data transfer requires programmers to reason about complex data flow. This can be a laborious and error-prone process since the programmer must keep a mental model of data validity and lifetime spanning multiple data environments. We present a static analysis tool, OMPDart (OpenMP Data Reduction Tool), for OpenMP programs that models data dependencies between host and device regions and applies source code transformations to achieve efficient data transfer. Our evaluations on nine HPC benchmarks demonstrate that OMPDart is capable of generating effective data mapping constructs that substantially reduce data transfer between host and device.
Read more9/10/2024
0
Optimizing Offload Performance in Heterogeneous MPSoCs
Luca Colagrande, Luca Benini
Heterogeneous multi-core architectures combine a few host cores, optimized for single-thread performance, with many small energy-efficient accelerator cores for data-parallel processing, on a single chip. Offloading a computation to the many-core acceleration fabric introduces a communication and synchronization cost which reduces the speedup attainable on the accelerator, particularly for small and fine-grained parallel tasks. We demonstrate that by co-designing the hardware and offload routines, we can increase the speedup of an offloaded DAXPY kernel by as much as 47.9%. Furthermore, we show that it is possible to accurately model the runtime of an offloaded application, accounting for the offload overheads, with as low as 1% MAPE error, enabling optimal offload decisions under offload execution time constraints.
Read more4/3/2024

0
Towards a Scalable and Efficient PGAS-based Distributed OpenMP
Baodi Shan, Mauricio Araya-Polo, Barbara Chapman
MPI+X has been the de facto standard for distributed memory parallel programming. It is widely used primarily as an explicit two-sided communication model, which often leads to complex and error-prone code. Alternatively, PGAS model utilizes efficient one-sided communication and more intuitive communication primitives. In this paper, we present a novel approach that integrates PGAS concepts into the OpenMP programming model, leveraging the LLVM compiler infrastructure and the GASNet-EX communication library. Our model addresses the complexity associated with traditional MPI+OpenMP programming models while ensuring excellent performance and scalability. We evaluate our approach using a set of micro-benchmarks and application kernels on two distinct platforms: Ookami from Stony Brook University and NERSC Perlmutter. The results demonstrate that DiOMP achieves superior bandwidth and lower latency compared to MPI+OpenMP, up to 25% higher bandwidth and down to 45% on latency. DiOMP offers a promising alternative to the traditional MPI+OpenMP hybrid programming model, towards providing a more productive and efficient way to develop high-performance parallel applications for distributed memory systems.
Read more9/5/2024
🛠️
0
OMP-Engineer: Bridging Syntax Analysis and In-Context Learning for Efficient Automated OpenMP Parallelization
Weidong Wang, Haoran Zhu
In advancing parallel programming, particularly with OpenMP, the shift towards NLP-based methods marks a significant innovation beyond traditional S2S tools like Autopar and Cetus. These NLP approaches train on extensive datasets of examples to efficiently generate optimized parallel code, streamlining the development process. This method's strength lies in its ability to swiftly produce parallelized code that runs efficiently. However, this reliance on NLP models, without direct code analysis, can introduce inaccuracies, as these models might not fully grasp the nuanced semantics of the code they parallelize. We build OMP-Engineer, which balances the efficiency and scalability of NLP models with the accuracy and reliability of traditional methods, aiming to enhance the performance of automating parallelization while navigating its inherent challenges.
Read more5/7/2024