Stepwise Regression and Pre-trained Edge for Robust Stereo Matching
2406.06953
0
0

Abstract
Due to the difficulty in obtaining real samples and ground truth, the generalization performance and the fine-tuned performance are critical for the feasibility of stereo matching methods in real-world applications. However, the presence of substantial disparity distributions and density variations across different datasets presents significant challenges for the generalization and fine-tuning of the model. In this paper, we propose a novel stereo matching method, called SR-Stereo, which mitigates the distributional differences across different datasets by predicting the disparity clips and uses a loss weight related to the regression target scale to improve the accuracy of the disparity clips. Moreover, this stepwise regression architecture can be easily extended to existing iteration-based methods to improve the performance without changing the structure. In addition, to mitigate the edge blurring of the fine-tuned model on sparse ground truth, we propose Domain Adaptation Based on Pre-trained Edges (DAPE). Specifically, we use the predicted disparity and RGB image to estimate the edge map of the target domain image. The edge map is filtered to generate edge map background pseudo-labels, which together with the sparse ground truth disparity on the target domain are used as a supervision to jointly fine-tune the pre-trained stereo matching model. These proposed methods are extensively evaluated on SceneFlow, KITTI, Middbury 2014 and ETH3D. The SR-Stereo achieves competitive disparity estimation performance and state-of-the-art cross-domain generalisation performance. Meanwhile, the proposed DAPE significantly improves the disparity estimation performance of fine-tuned models, especially in the textureless and detail regions.
Create account to get full access
Introduction
Stereo matching is a fundamental computer vision task that involves estimating depth information from a pair of images captured from different viewpoints. However, traditional stereo matching algorithms often struggle with challenges such as occlusions, reflections, and textureless regions. This paper proposes a novel approach to improve the robustness of stereo matching by combining stepwise regression and pre-trained edge information.
Related Work
Stereo matching has been an active area of research, with various methods proposed to address the challenges. One approach is SyntStereo2Real, which uses a synthetic-to-real domain adaptation technique to improve performance on real-world data. Another method, Distill-Then-Prune, focuses on efficient stereo matching by distilling knowledge from a larger model and then pruning the network. Additionally, RethinkingIterativeStereo proposes a diffusion-based approach to iterative stereo matching, while RobustMVS addresses the problem of multi-view stereo reconstruction in a single domain. Finally, AdaptiveLearningMVS introduces an adaptive learning framework for multi-view stereo reconstruction.
Plain English Explanation
This paper presents a new way to make stereo matching, the process of estimating depth from two camera views, more robust and reliable. Traditional methods often struggle with challenging scenarios like objects that block the view, shiny surfaces, or areas with little texture.
The key idea is to combine two techniques: stepwise regression and pre-trained edge information. Stepwise regression is a statistical method that helps identify the most important factors influencing the depth estimates. By focusing on the critical factors, the algorithm can produce more accurate results, even in difficult situations.
Additionally, the researchers use pre-trained edge information, which is data about the edges and boundaries in the images, to further improve the stereo matching. This edge data acts as a guide, helping the algorithm differentiate between important depth cues and distractions.
By combining these two approaches, the paper demonstrates significant improvements in the robustness and accuracy of stereo matching, making it more reliable for real-world applications like autonomous vehicles, 3D reconstruction, and virtual/augmented reality.
Technical Explanation
The paper proposes a novel stereo matching framework that leverages stepwise regression and pre-trained edge information to improve robustness. The key components are:
-
Stepwise Regression: The authors use stepwise regression to identify the most important factors influencing the stereo matching performance. This helps the model focus on the critical features and discard less relevant ones, improving its ability to handle challenging scenarios.
-
Pre-trained Edge Information: The researchers incorporate pre-trained edge information, which provides valuable cues about the boundaries and structures in the images. This edge data is used to guide the stereo matching process, helping the model distinguish between meaningful depth information and distractions.
The proposed framework is evaluated on several standard stereo matching benchmarks, and the results demonstrate significant improvements in robustness and accuracy compared to state-of-the-art methods. The authors also conduct ablation studies to analyze the individual contributions of the stepwise regression and edge-aware components.
Critical Analysis
The paper presents a well-designed and thorough study, with a clear rationale for the proposed approach and comprehensive experiments to validate its effectiveness. The authors have identified an important problem in stereo matching and have proposed a practical solution that combines statistical and domain-specific techniques.
One potential limitation of the work is that it may not generalize as well to highly complex or diverse scenes, as the stepwise regression and pre-trained edge information may not capture all the relevant factors in such cases. Additionally, the reliance on pre-trained edge data could make the approach less flexible, as it may require retraining or fine-tuning the edge detection model for different domains.
Further research could explore ways to make the framework more adaptable, such as by incorporating online edge learning or unsupervised edge extraction methods. Investigating the scalability of the approach to larger and more diverse datasets would also be valuable.
Conclusion
This paper presents a novel stereo matching framework that combines stepwise regression and pre-trained edge information to improve the robustness of depth estimation. By focusing on the critical factors through stepwise regression and leveraging edge-aware guidance, the proposed method demonstrates significant improvements in handling challenging scenarios such as occlusions, reflections, and textureless regions.
The techniques introduced in this work have the potential to enhance a wide range of computer vision applications that rely on accurate depth information, such as autonomous vehicles, 3D reconstruction, and virtual/augmented reality. The authors have made a valuable contribution to the field of stereo matching, and their findings could inspire further research in the direction of robust and adaptive depth estimation.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

SyntStereo2Real: Edge-Aware GAN for Remote Sensing Image-to-Image Translation while Maintaining Stereo Constraint
Vasudha Venkatesan, Daniel Panangian, Mario Fuentes Reyes, Ksenia Bittner
0
0
In the field of remote sensing, the scarcity of stereo-matched and particularly lack of accurate ground truth data often hinders the training of deep neural networks. The use of synthetically generated images as an alternative, alleviates this problem but suffers from the problem of domain generalization. Unifying the capabilities of image-to-image translation and stereo-matching presents an effective solution to address the issue of domain generalization. Current methods involve combining two networks, an unpaired image-to-image translation network and a stereo-matching network, while jointly optimizing them. We propose an edge-aware GAN-based network that effectively tackles both tasks simultaneously. We obtain edge maps of input images from the Sobel operator and use it as an additional input to the encoder in the generator to enforce geometric consistency during translation. We additionally include a warping loss calculated from the translated images to maintain the stereo consistency. We demonstrate that our model produces qualitatively and quantitatively superior results than existing models, and its applicability extends to diverse domains, including autonomous driving.
4/16/2024

Distill-then-prune: An Efficient Compression Framework for Real-time Stereo Matching Network on Edge Devices
Baiyu Pan, Jichao Jiao, Jianxing Pang, Jun Cheng
0
0
In recent years, numerous real-time stereo matching methods have been introduced, but they often lack accuracy. These methods attempt to improve accuracy by introducing new modules or integrating traditional methods. However, the improvements are only modest. In this paper, we propose a novel strategy by incorporating knowledge distillation and model pruning to overcome the inherent trade-off between speed and accuracy. As a result, we obtained a model that maintains real-time performance while delivering high accuracy on edge devices. Our proposed method involves three key steps. Firstly, we review state-of-the-art methods and design our lightweight model by removing redundant modules from those efficient models through a comparison of their contributions. Next, we leverage the efficient model as the teacher to distill knowledge into the lightweight model. Finally, we systematically prune the lightweight model to obtain the final model. Through extensive experiments conducted on two widely-used benchmarks, Sceneflow and KITTI, we perform ablation studies to analyze the effectiveness of each module and present our state-of-the-art results.
5/21/2024

Rethinking Iterative Stereo Matching from Diffusion Bridge Model Perspective
Yuguang Shi
0
0
Recently, iteration-based stereo matching has shown great potential. However, these models optimize the disparity map using RNN variants. The discrete optimization process poses a challenge of information loss, which restricts the level of detail that can be expressed in the generated disparity map. In order to address these issues, we propose a novel training approach that incorporates diffusion models into the iterative optimization process. We designed a Time-based Gated Recurrent Unit (T-GRU) to correlate temporal and disparity outputs. Unlike standard recurrent units, we employ Agent Attention to generate more expressive features. We also designed an attention-based context network to capture a large amount of contextual information. Experiments on several public benchmarks show that we have achieved competitive stereo matching performance. Our model ranks first in the Scene Flow dataset, achieving over a 7% improvement compared to competing methods, and requires only 8 iterations to achieve state-of-the-art results.
4/16/2024
RobustMVS: Single Domain Generalized Deep Multi-view Stereo
Hongbin Xu, Weitao Chen, Baigui Sun, Xuansong Xie, Wenxiong Kang
0
0
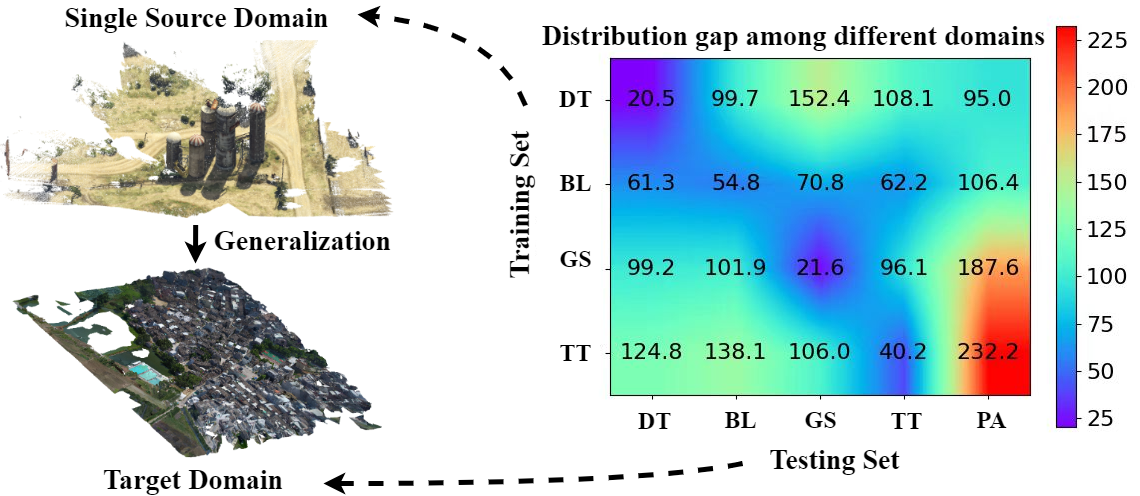
Despite the impressive performance of Multi-view Stereo (MVS) approaches given plenty of training samples, the performance degradation when generalizing to unseen domains has not been clearly explored yet. In this work, we focus on the domain generalization problem in MVS. To evaluate the generalization results, we build a novel MVS domain generalization benchmark including synthetic and real-world datasets. In contrast to conventional domain generalization benchmarks, we consider a more realistic but challenging scenario, where only one source domain is available for training. The MVS problem can be analogized back to the feature matching task, and maintaining robust feature consistency among views is an important factor for improving generalization performance. To address the domain generalization problem in MVS, we propose a novel MVS framework, namely RobustMVS. A DepthClustering-guided Whitening (DCW) loss is further introduced to preserve the feature consistency among different views, which decorrelates multi-view features from viewpoint-specific style information based on geometric priors from depth maps. The experimental results further show that our method achieves superior performance on the domain generalization benchmark.
5/16/2024