Rethinking Iterative Stereo Matching from Diffusion Bridge Model Perspective
2404.09051
0
0

Abstract
Recently, iteration-based stereo matching has shown great potential. However, these models optimize the disparity map using RNN variants. The discrete optimization process poses a challenge of information loss, which restricts the level of detail that can be expressed in the generated disparity map. In order to address these issues, we propose a novel training approach that incorporates diffusion models into the iterative optimization process. We designed a Time-based Gated Recurrent Unit (T-GRU) to correlate temporal and disparity outputs. Unlike standard recurrent units, we employ Agent Attention to generate more expressive features. We also designed an attention-based context network to capture a large amount of contextual information. Experiments on several public benchmarks show that we have achieved competitive stereo matching performance. Our model ranks first in the Scene Flow dataset, achieving over a 7% improvement compared to competing methods, and requires only 8 iterations to achieve state-of-the-art results.
Create account to get full access
Overview
- Iterative stereo matching is a technique used in computer vision to estimate depth from stereo image pairs.
- This paper proposes a new perspective on iterative stereo matching, drawing insights from diffusion bridge models - a type of generative AI model.
- The authors explore how diffusion models can be used to improve the performance and stability of iterative stereo matching algorithms.
Plain English Explanation
Stereo matching is the process of using two slightly offset images, like the views from your two eyes, to estimate the depth or 3D structure of a scene. Traditionally, this has been done through an iterative process - making a guess at the depth, checking how well it matches the images, and then refining the guess over many iterations.
This paper looks at stereo matching from a different angle, drawing inspiration from a type of AI model called a diffusion bridge. Diffusion models are a powerful way to generate new images by gradually adding and then removing "noise" to an image. The authors propose that this diffusion process could also help make iterative stereo matching more effective and stable.
By rethinking the stereo matching problem through the lens of diffusion models, the researchers hope to develop new algorithms that can better estimate depth from stereo image pairs. This could have applications in fields like robotics, augmented reality, and computational photography.
Technical Explanation
The paper explores the connections between iterative stereo matching and diffusion bridge models. Diffusion bridge models are a type of generative AI model that generate new images by gradually adding and then removing noise. The authors hypothesize that this diffusion process could be leveraged to make iterative stereo matching more robust and effective.
The key idea is to cast the stereo matching problem as a diffusion process, where the algorithm starts with a noisy depth estimate and gradually refines it over multiple iterations, similar to how diffusion models generate images. The authors propose several architectural modifications to existing stereo matching networks to incorporate this diffusion-inspired approach.
Through experiments on standard stereo matching benchmarks, the authors demonstrate that their diffusion-based stereo matching model can outperform previous state-of-the-art approaches in terms of accuracy and stability. They also analyze the inner workings of their model, showing how the diffusion process helps the algorithm converge to accurate depth estimates.
Critical Analysis
The paper presents a novel and interesting perspective on iterative stereo matching by drawing connections to the emerging field of diffusion models. The authors make a compelling case for how the principles of diffusion can be applied to improve the performance and robustness of stereo matching algorithms.
One potential limitation of the work is that it focuses primarily on benchmarks and does not explore real-world applications in depth. It would be valuable to see how the proposed diffusion-based stereo matching approach performs in practical scenarios, such as in robotics or augmented reality systems.
Additionally, the paper does not delve into the computational complexity of the diffusion-based approach compared to traditional iterative stereo matching. As the number of diffusion steps increases, the computational cost may also rise, which could be a consideration for real-time or resource-constrained applications.
Further research could also explore integrating the diffusion-based stereo matching approach with other techniques, such as edge-aware generative adversarial networks or diffusion-based registration models, to address additional challenges in depth estimation and scene understanding.
Conclusion
This paper presents a novel perspective on iterative stereo matching by drawing insights from the emerging field of diffusion bridge models. The authors demonstrate how the principles of diffusion can be used to improve the performance and stability of stereo matching algorithms, opening up new avenues for research and applications in computer vision.
The diffusion-based approach proposed in this work has the potential to enhance depth estimation in a wide range of domains, from robotic navigation to augmented reality. As the field of diffusion models continues to progress, we can expect to see more innovative applications that leverage these powerful generative techniques to tackle complex computer vision problems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
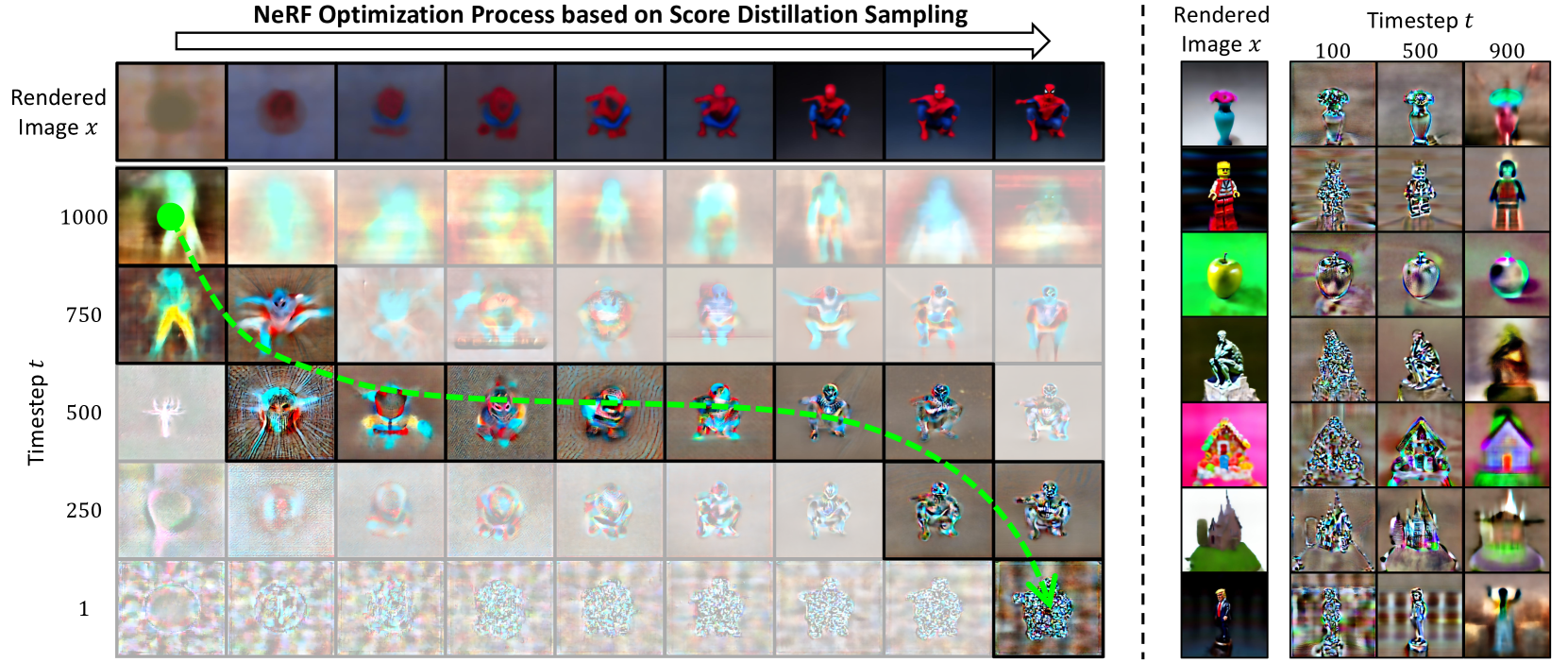
DreamTime: An Improved Optimization Strategy for Diffusion-Guided 3D Generation
Yukun Huang, Jianan Wang, Yukai Shi, Boshi Tang, Xianbiao Qi, Lei Zhang
0
0
Text-to-image diffusion models pre-trained on billions of image-text pairs have recently enabled 3D content creation by optimizing a randomly initialized differentiable 3D representation with score distillation. However, the optimization process suffers slow convergence and the resultant 3D models often exhibit two limitations: (a) quality concerns such as missing attributes and distorted shape and texture; (b) extremely low diversity comparing to text-guided image synthesis. In this paper, we show that the conflict between the 3D optimization process and uniform timestep sampling in score distillation is the main reason for these limitations. To resolve this conflict, we propose to prioritize timestep sampling with monotonically non-increasing functions, which aligns the 3D optimization process with the sampling process of diffusion model. Extensive experiments show that our simple redesign significantly improves 3D content creation with faster convergence, better quality and diversity.
5/7/2024

StereoDiffusion: Training-Free Stereo Image Generation Using Latent Diffusion Models
Lezhong Wang, Jeppe Revall Frisvad, Mark Bo Jensen, Siavash Arjomand Bigdeli
0
0
The demand for stereo images increases as manufacturers launch more XR devices. To meet this demand, we introduce StereoDiffusion, a method that, unlike traditional inpainting pipelines, is trainning free, remarkably straightforward to use, and it seamlessly integrates into the original Stable Diffusion model. Our method modifies the latent variable to provide an end-to-end, lightweight capability for fast generation of stereo image pairs, without the need for fine-tuning model weights or any post-processing of images. Using the original input to generate a left image and estimate a disparity map for it, we generate the latent vector for the right image through Stereo Pixel Shift operations, complemented by Symmetric Pixel Shift Masking Denoise and Self-Attention Layers Modification methods to align the right-side image with the left-side image. Moreover, our proposed method maintains a high standard of image quality throughout the stereo generation process, achieving state-of-the-art scores in various quantitative evaluations.
6/4/2024
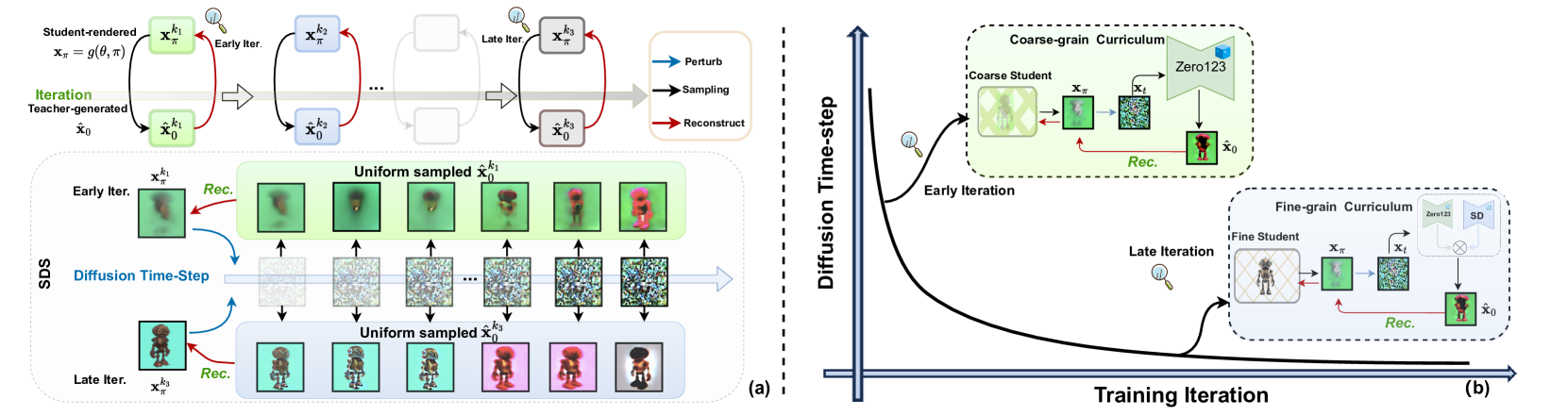
Diffusion Time-step Curriculum for One Image to 3D Generation
Xuanyu Yi, Zike Wu, Qingshan Xu, Pan Zhou, Joo-Hwee Lim, Hanwang Zhang
0
0
Score distillation sampling~(SDS) has been widely adopted to overcome the absence of unseen views in reconstructing 3D objects from a textbf{single} image. It leverages pre-trained 2D diffusion models as teacher to guide the reconstruction of student 3D models. Despite their remarkable success, SDS-based methods often encounter geometric artifacts and texture saturation. We find out the crux is the overlooked indiscriminate treatment of diffusion time-steps during optimization: it unreasonably treats the student-teacher knowledge distillation to be equal at all time-steps and thus entangles coarse-grained and fine-grained modeling. Therefore, we propose the Diffusion Time-step Curriculum one-image-to-3D pipeline (DTC123), which involves both the teacher and student models collaborating with the time-step curriculum in a coarse-to-fine manner. Extensive experiments on NeRF4, RealFusion15, GSO and Level50 benchmark demonstrate that DTC123 can produce multi-view consistent, high-quality, and diverse 3D assets. Codes and more generation demos will be released in https://github.com/yxymessi/DTC123.
5/6/2024

4Diffusion: Multi-view Video Diffusion Model for 4D Generation
Haiyu Zhang, Xinyuan Chen, Yaohui Wang, Xihui Liu, Yunhong Wang, Yu Qiao
0
0
Current 4D generation methods have achieved noteworthy efficacy with the aid of advanced diffusion generative models. However, these methods lack multi-view spatial-temporal modeling and encounter challenges in integrating diverse prior knowledge from multiple diffusion models, resulting in inconsistent temporal appearance and flickers. In this paper, we propose a novel 4D generation pipeline, namely 4Diffusion aimed at generating spatial-temporally consistent 4D content from a monocular video. We first design a unified diffusion model tailored for multi-view video generation by incorporating a learnable motion module into a frozen 3D-aware diffusion model to capture multi-view spatial-temporal correlations. After training on a curated dataset, our diffusion model acquires reasonable temporal consistency and inherently preserves the generalizability and spatial consistency of the 3D-aware diffusion model. Subsequently, we propose 4D-aware Score Distillation Sampling loss, which is based on our multi-view video diffusion model, to optimize 4D representation parameterized by dynamic NeRF. This aims to eliminate discrepancies arising from multiple diffusion models, allowing for generating spatial-temporally consistent 4D content. Moreover, we devise an anchor loss to enhance the appearance details and facilitate the learning of dynamic NeRF. Extensive qualitative and quantitative experiments demonstrate that our method achieves superior performance compared to previous methods.
6/3/2024