Story Generation from Visual Inputs: Techniques, Related Tasks, and Challenges
2406.02748
0
0

Abstract
Creating engaging narratives from visual data is crucial for automated digital media consumption, assistive technologies, and interactive entertainment. This survey covers methodologies used in the generation of these narratives, focusing on their principles, strengths, and limitations. The survey also covers tasks related to automatic story generation, such as image and video captioning, and visual question answering, as well as story generation without visual inputs. These tasks share common challenges with visual story generation and have served as inspiration for the techniques used in the field. We analyze the main datasets and evaluation metrics, providing a critical perspective on their limitations.
Create account to get full access
Overview
- This paper discusses the task of story generation from visual inputs, which involves generating textual narratives based on images or other visual stimuli.
- It covers the key techniques and approaches used in this field, as well as related tasks like image captioning and visual question answering.
- The paper also outlines the major challenges and open research questions in this area.
Plain English Explanation
The paper focuses on a topic called visual story generation. This is the process of taking an image or other visual input and automatically generating a written story or narrative about what is depicted.
For example, you could show the system an image of a family picnicking in a park, and it would generate a short story describing the scene - what the people are doing, the mood and setting, and so on. This is a challenging task that combines skills in image understanding, natural language processing, and text generation.
The paper discusses the key techniques and approaches used to tackle visual story generation, as well as related tasks like image captioning and visual question answering. It also outlines the major challenges and open research questions in this field, such as generating more coherent and creative stories, handling complex visual scenes, and enabling interactive storytelling.
Technical Explanation
The paper provides a comprehensive overview of the state-of-the-art in visual story generation. It begins by defining the task and highlighting the key challenges, such as generating cohesive narratives that are grounded in visual context, and capturing subjective and abstract elements of a scene.
The authors then survey the techniques used in visual story generation, which often involve neural network architectures that combine computer vision and natural language processing. These include encoder-decoder models, attention mechanisms, and reinforcement learning-based approaches.
The paper also covers related tasks like image captioning and visual question answering, which share some underlying capabilities with visual story generation. It discusses how techniques and insights from these tasks can be leveraged to advance story generation.
Finally, the authors outline the major challenges in this field, such as generating coherent, diverse, and creative stories, handling complex visual scenes, and enabling interactive storytelling. They suggest potential directions for future research to address these issues.
Critical Analysis
The paper provides a thorough and well-structured overview of the visual story generation field. It does a commendable job of covering the key techniques, related tasks, and challenges in a clear and comprehensive manner.
However, the paper also acknowledges some of the limitations of current approaches. For example, it notes that existing models struggle to capture the rich semantics and nuances of human-generated stories, and often produce narratives that lack coherence and creativity.
Additionally, the paper does not delve deeply into the ethical implications of this technology, such as the potential for bias, privacy concerns, or the impact on human storytelling and creative expression. These are important considerations that could warrant further discussion.
Overall, the paper provides a solid foundation for understanding the state of visual story generation research, but there is still much work to be done to realize the full potential of this technology while addressing its limitations and ethical considerations.
Conclusion
This paper offers a comprehensive overview of the field of visual story generation, which involves using computer vision and natural language processing techniques to automatically generate textual narratives based on visual inputs.
The authors survey the key techniques and approaches used in this area, as well as related tasks like image captioning and visual question answering. They also outline the major challenges, including generating coherent and creative stories, handling complex visual scenes, and enabling interactive storytelling.
While current models have made significant progress, the paper acknowledges that there is still much room for improvement in terms of capturing the nuances and semantics of human-generated stories. Addressing these limitations and considering the ethical implications of this technology will be important areas for future research in this field.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🤖
ID.8: Co-Creating Visual Stories with Generative AI
Victor Nikhil Antony, Chien-Ming Huang
0
0
Storytelling is an integral part of human culture and significantly impacts cognitive and socio-emotional development and connection. Despite the importance of interactive visual storytelling, the process of creating such content requires specialized skills and is labor-intensive. This paper introduces ID.8, an open-source system designed for the co-creation of visual stories with generative AI. We focus on enabling an inclusive storytelling experience by simplifying the content creation process and allowing for customization. Our user evaluation confirms a generally positive user experience in domains such as enjoyment and exploration, while highlighting areas for improvement, particularly in immersiveness, alignment, and partnership between the user and the AI system. Overall, our findings indicate promising possibilities for empowering people to create visual stories with generative AI. This work contributes a novel content authoring system, ID.8, and insights into the challenges and potential of using generative AI for multimedia content creation.
6/4/2024
🖼️
Human Image Generation: A Comprehensive Survey
Zhen Jia, Zhang Zhang, Liang Wang, Tieniu Tan
0
0
Image and video synthesis has become a blooming topic in computer vision and machine learning communities along with the developments of deep generative models, due to its great academic and application value. Many researchers have been devoted to synthesizing high-fidelity human images as one of the most commonly seen object categories in daily lives, where a large number of studies are performed based on various models, task settings and applications. Thus, it is necessary to give a comprehensive overview on these variant methods on human image generation. In this paper, we divide human image generation techniques into three paradigms, i.e., data-driven methods, knowledge-guided methods and hybrid methods. For each paradigm, the most representative models and the corresponding variants are presented, where the advantages and characteristics of different methods are summarized in terms of model architectures. Besides, the main public human image datasets and evaluation metrics in the literature are summarized. Furthermore, due to the wide application potentials, the typical downstream usages of synthesized human images are covered. Finally, the challenges and potential opportunities of human image generation are discussed to shed light on future research.
5/27/2024
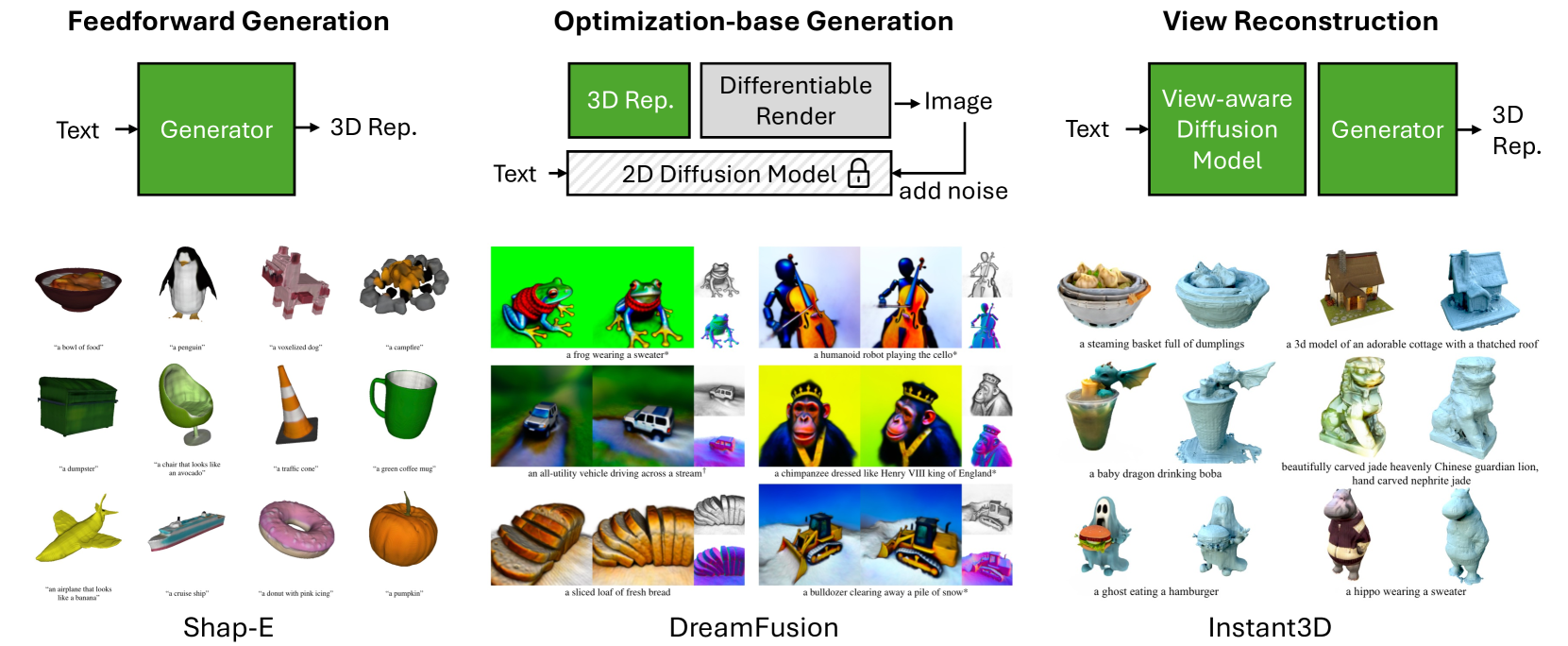
A Survey On Text-to-3D Contents Generation In The Wild
Chenhan Jiang
0
0
3D content creation plays a vital role in various applications, such as gaming, robotics simulation, and virtual reality. However, the process is labor-intensive and time-consuming, requiring skilled designers to invest considerable effort in creating a single 3D asset. To address this challenge, text-to-3D generation technologies have emerged as a promising solution for automating 3D creation. Leveraging the success of large vision language models, these techniques aim to generate 3D content based on textual descriptions. Despite recent advancements in this area, existing solutions still face significant limitations in terms of generation quality and efficiency. In this survey, we conduct an in-depth investigation of the latest text-to-3D creation methods. We provide a comprehensive background on text-to-3D creation, including discussions on datasets employed in training and evaluation metrics used to assess the quality of generated 3D models. Then, we delve into the various 3D representations that serve as the foundation for the 3D generation process. Furthermore, we present a thorough comparison of the rapidly growing literature on generative pipelines, categorizing them into feedforward generators, optimization-based generation, and view reconstruction approaches. By examining the strengths and weaknesses of these methods, we aim to shed light on their respective capabilities and limitations. Lastly, we point out several promising avenues for future research. With this survey, we hope to inspire researchers further to explore the potential of open-vocabulary text-conditioned 3D content creation.
5/16/2024

Text Generation: A Systematic Literature Review of Tasks, Evaluation, and Challenges
Jonas Becker, Jan Philip Wahle, Bela Gipp, Terry Ruas
0
0
Text generation has become more accessible than ever, and the increasing interest in these systems, especially those using large language models, has spurred an increasing number of related publications. We provide a systematic literature review comprising 244 selected papers between 2017 and 2024. This review categorizes works in text generation into five main tasks: open-ended text generation, summarization, translation, paraphrasing, and question answering. For each task, we review their relevant characteristics, sub-tasks, and specific challenges (e.g., missing datasets for multi-document summarization, coherence in story generation, and complex reasoning for question answering). Additionally, we assess current approaches for evaluating text generation systems and ascertain problems with current metrics. Our investigation shows nine prominent challenges common to all tasks and sub-tasks in recent text generation publications: bias, reasoning, hallucinations, misuse, privacy, interpretability, transparency, datasets, and computing. We provide a detailed analysis of these challenges, their potential solutions, and which gaps still require further engagement from the community. This systematic literature review targets two main audiences: early career researchers in natural language processing looking for an overview of the field and promising research directions, as well as experienced researchers seeking a detailed view of tasks, evaluation methodologies, open challenges, and recent mitigation strategies.
5/27/2024