Synchronized Video Storytelling: Generating Video Narrations with Structured Storyline
2405.14040
0
0
🌿
Abstract
Video storytelling is engaging multimedia content that utilizes video and its accompanying narration to attract the audience, where a key challenge is creating narrations for recorded visual scenes. Previous studies on dense video captioning and video story generation have made some progress. However, in practical applications, we typically require synchronized narrations for ongoing visual scenes. In this work, we introduce a new task of Synchronized Video Storytelling, which aims to generate synchronous and informative narrations for videos. These narrations, associated with each video clip, should relate to the visual content, integrate relevant knowledge, and have an appropriate word count corresponding to the clip's duration. Specifically, a structured storyline is beneficial to guide the generation process, ensuring coherence and integrity. To support the exploration of this task, we introduce a new benchmark dataset E-SyncVidStory with rich annotations. Since existing Multimodal LLMs are not effective in addressing this task in one-shot or few-shot settings, we propose a framework named VideoNarrator that can generate a storyline for input videos and simultaneously generate narrations with the guidance of the generated or predefined storyline. We further introduce a set of evaluation metrics to thoroughly assess the generation. Both automatic and human evaluations validate the effectiveness of our approach. Our dataset, codes, and evaluations will be released.
Create account to get full access
Overview
- This paper introduces a new task called Synchronized Video Storytelling, which aims to generate synchronized and informative narrations for videos.
- The goal is to create narrations that relate to the visual content, integrate relevant knowledge, and have a word count that matches the duration of each video clip.
- A structured storyline is seen as beneficial to guide the generation process and ensure coherence and integrity.
- To support this task, the authors introduce a new benchmark dataset called E-SyncVidStory with rich annotations.
- Existing Multimodal Large Language Models (LLMs) are not effective in addressing this task in one-shot or few-shot settings, so the authors propose a framework called VideoNarrator to generate storylines and narrations.
- The paper also introduces a set of evaluation metrics to thoroughly assess the generation.
Plain English Explanation
The paper focuses on a new way to create engaging multimedia content using video storytelling. This involves using video and narration together to capture the audience's attention. One key challenge is generating narrations that seamlessly match the visuals on screen.
Previous research on dense video captioning and video story generation has made progress, but the authors identify a need for narrations that are closely synchronized with the ongoing visual scenes.
To address this, the paper introduces a new task called "Synchronized Video Storytelling." The goal is to create narrations that are informative, related to the visuals, and have the right length to match each video clip. The authors believe a structured storyline can help guide the narration generation to ensure it is coherent and consistent.
To support this new task, the researchers created a dataset called E-SyncVidStory with detailed annotations. They also propose a framework called VideoNarrator that can generate both storylines and narrations for input videos. Additionally, they developed evaluation metrics to assess the quality of the generated content.
Technical Explanation
The paper introduces the task of Synchronized Video Storytelling, which aims to generate synchronized and informative narrations for videos. These narrations should relate to the visual content, integrate relevant knowledge, and have a word count that matches the duration of each video clip.
To guide the narration generation process and ensure coherence and integrity, the authors suggest that a structured storyline can be beneficial. They introduce a new benchmark dataset called E-SyncVidStory, which contains rich annotations to support the exploration of this task.
The authors note that existing Multimodal Large Language Models (LLMs) are not effective in addressing this task in one-shot or few-shot settings. To address this, they propose a framework called VideoNarrator that can generate a storyline for input videos and simultaneously generate narrations with the guidance of the generated or predefined storyline.
The paper also introduces a set of evaluation metrics to thoroughly assess the generated narrations. These metrics cover aspects such as language-guided self-supervised video summarization and enhancing video summarization with context awareness.
Critical Analysis
The paper presents a novel and valuable task in the field of video storytelling, addressing the challenge of generating synchronized and informative narrations. The authors' approach of using a structured storyline to guide the narration generation is a promising direction, as it can help ensure the coherence and integrity of the final output.
However, the paper does not provide a detailed discussion of the limitations or potential issues with the proposed framework. For example, it would be useful to understand the performance of the VideoNarrator model compared to human-generated narrations, as well as the potential biases or errors that could arise in the generated content.
Additionally, the paper could benefit from a more thorough analysis of the E-SyncVidStory dataset, including any biases or limitations in the data that could impact the model's performance. It would also be interesting to see how the framework performs on diverse types of video content beyond the specific dataset used in the study.
Overall, the paper presents an important step forward in the field of video storytelling, but there are opportunities for further research and critical evaluation of the proposed approach.
Conclusion
This paper introduces a new task called Synchronized Video Storytelling, which aims to generate synchronized and informative narrations for videos. The authors propose a framework called VideoNarrator to address this task, along with a new benchmark dataset called E-SyncVidStory.
The key contribution of this work is the recognition of the need for narrations that are closely aligned with the visual content, both in terms of relevance and duration. By incorporating a structured storyline to guide the narration generation, the authors aim to improve the coherence and integrity of the final video storytelling experience.
The development of this new task and the supporting dataset and evaluation metrics represent an important step forward in the field of video storytelling. The findings and insights from this research could have significant implications for a wide range of multimedia applications, from educational content to entertainment and beyond.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Multilingual Synopses of Movie Narratives: A Dataset for Story Understanding
Yidan Sun, Jianfei Yu, Boyang Li
0
0
Story video-text alignment, a core task in computational story understanding, aims to align video clips with corresponding sentences in their descriptions. However, progress on the task has been held back by the scarcity of manually annotated video-text correspondence and the heavy concentration on English narrations of Hollywood movies. To address these issues, in this paper, we construct a large-scale multilingual video story dataset named Multilingual Synopses of Movie Narratives (M-SYMON), containing 13,166 movie summary videos from 7 languages, as well as manual annotation of fine-grained video-text correspondences for 101.5 hours of video. Training on the human annotated data from SyMoN outperforms the SOTA methods by 15.7 and 16.2 percentage points on Clip Accuracy and Sentence IoU scores, respectively, demonstrating the effectiveness of the annotations. As benchmarks for future research, we create 6 baseline approaches with different multilingual training strategies, compare their performance in both intra-lingual and cross-lingual setups, exemplifying the challenges of multilingual video-text alignment.
6/21/2024

Movie101v2: Improved Movie Narration Benchmark
Zihao Yue, Yepeng Zhang, Ziheng Wang, Qin Jin
0
0
Automatic movie narration targets at creating video-aligned plot descriptions to assist visually impaired audiences. It differs from standard video captioning in that it requires not only describing key visual details but also inferring the plots developed across multiple movie shots, thus posing unique and ongoing challenges. To advance the development of automatic movie narrating systems, we first revisit the limitations of existing datasets and develop a large-scale, bilingual movie narration dataset, Movie101v2. Second, taking into account the essential difficulties in achieving applicable movie narration, we break the long-term goal into three progressive stages and tentatively focus on the initial stages featuring understanding within individual clips. We also introduce a new narration assessment to align with our staged task goals. Third, using our new dataset, we baseline several leading large vision-language models, including GPT-4V, and conduct in-depth investigations into the challenges current models face for movie narration generation. Our findings reveal that achieving applicable movie narration generation is a fascinating goal that requires thorough research.
4/23/2024
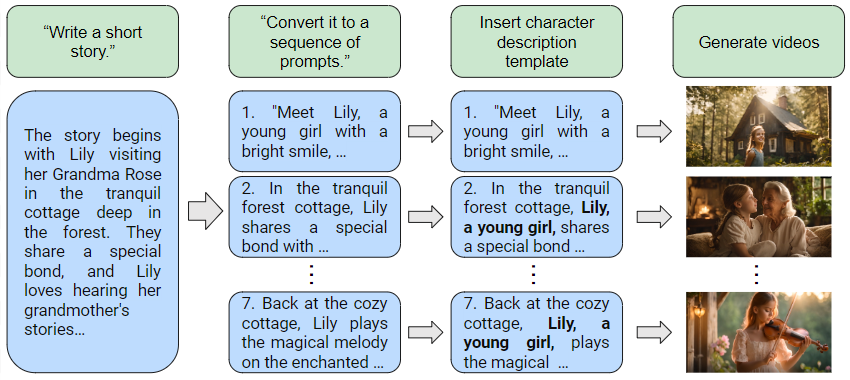
The Lost Melody: Empirical Observations on Text-to-Video Generation From A Storytelling Perspective
Andrew Shin, Yusuke Mori, Kunitake Kaneko
0
0
Text-to-video generation task has witnessed a notable progress, with the generated outcomes reflecting the text prompts with high fidelity and impressive visual qualities. However, current text-to-video generation models are invariably focused on conveying the visual elements of a single scene, and have so far been indifferent to another important potential of the medium, namely a storytelling. In this paper, we examine text-to-video generation from a storytelling perspective, which has been hardly investigated, and make empirical remarks that spotlight the limitations of current text-to-video generation scheme. We also propose an evaluation framework for storytelling aspects of videos, and discuss the potential future directions.
5/15/2024

NarrativeBridge: Enhancing Video Captioning with Causal-Temporal Narrative
Asmar Nadeem, Faegheh Sardari, Robert Dawes, Syed Sameed Husain, Adrian Hilton, Armin Mustafa
0
0
Existing video captioning benchmarks and models lack coherent representations of causal-temporal narrative, which is sequences of events linked through cause and effect, unfolding over time and driven by characters or agents. This lack of narrative restricts models' ability to generate text descriptions that capture the causal and temporal dynamics inherent in video content. To address this gap, we propose NarrativeBridge, an approach comprising of: (1) a novel Causal-Temporal Narrative (CTN) captions benchmark generated using a large language model and few-shot prompting, explicitly encoding cause-effect temporal relationships in video descriptions, evaluated automatically to ensure caption quality and relevance; and (2) a dedicated Cause-Effect Network (CEN) architecture with separate encoders for capturing cause and effect dynamics independently, enabling effective learning and generation of captions with causal-temporal narrative. Extensive experiments demonstrate that CEN is more accurate in articulating the causal and temporal aspects of video content than the second best model (GIT): 17.88 and 17.44 CIDEr on the MSVD and MSR-VTT datasets, respectively. The proposed framework understands and generates nuanced text descriptions with intricate causal-temporal narrative structures present in videos, addressing a critical limitation in video captioning. For project details, visit https://narrativebridge.github.io/.
6/11/2024