Struc-Bench: Are Large Language Models Really Good at Generating Complex Structured Data?
2309.08963
0
0
💬
Abstract
Despite the remarkable capabilities of Large Language Models (LLMs) like GPT-4, producing complex, structured tabular data remains challenging. Our study assesses LLMs' proficiency in structuring tables and introduces a novel fine-tuning method, cognizant of data structures, to bolster their performance. We unveil Struc-Bench, a comprehensive benchmark featuring prominent LLMs (GPT-NeoX-20B, GPT-3.5, GPT-4, and Vicuna), which spans text tables, HTML, and LaTeX formats. Our proposed FormatCoT aids in crafting format-specific instructions from the intended outputs to populate this benchmark. Addressing the gap in task-centered evaluation, we propose two innovative metrics, P-Score (Prompting Score) and H-Score (Heuristical Score), to more accurately gauge LLM performance. Our experiments show that applying our structure-aware fine-tuning to LLaMA-7B leads to substantial performance gains, outshining its LLM counterparts across most measures. In-depth error analysis and creating an ability map across six dimensions -- coverage, formatting, reasoning, comprehension, pragmatics, and hallucination -- highlight areas for future enhancements and suggest forthcoming research trajectories. Our code and models can be found at https://github.com/gersteinlab/Struc-Bench.
Create account to get full access
Overview
- This study explores the challenges of using Large Language Models (LLMs) like GPT-4 to generate complex, structured tabular data.
- The researchers introduce a novel fine-tuning method, cognizant of data structures, to improve LLMs' performance in this task.
- They present Struc-Bench, a comprehensive benchmark for evaluating LLMs' abilities in structuring tables across different formats (text, HTML, and LaTeX).
- The study also proposes two new metrics, P-Score (Prompting Score) and H-Score (Heuristical Score), to better assess LLM performance in this context.
- The researchers find that applying their structure-aware fine-tuning to LLaMA-7B leads to substantial performance gains, outshining other LLM counterparts.
Plain English Explanation
Large language models (LLMs) like GPT-4 are incredibly capable, but they still struggle to produce complex, structured data like tables. This study aims to address this challenge by introducing a new way to fine-tune LLMs to be better at creating tables.
The researchers created a comprehensive benchmark called Struc-Bench, which tests how well LLMs can structure tables in different formats, like plain text, HTML, and LaTeX. They also came up with two new ways to measure how well the models perform, called P-Score and H-Score.
By applying their special fine-tuning method to the LLaMA-7B model, the researchers found that it significantly outperformed other LLMs at the table-structuring task. They also did a deep analysis of the models' strengths and weaknesses, which could help guide future improvements in this area.
Technical Explanation
The researchers designed a study to assess the proficiency of large language models (LLMs) in structuring complex tabular data. They introduced a novel fine-tuning method that incorporates an understanding of data structures to enhance the LLMs' performance in this task.
To evaluate the LLMs, the researchers developed Struc-Bench, a comprehensive benchmark that spans text tables, HTML, and LaTeX formats. This benchmark was populated using a technique called FormatCoT, which helps craft format-specific instructions from the intended outputs.
To more accurately gauge the LLMs' performance, the researchers proposed two innovative metrics: P-Score (Prompting Score) and H-Score (Heuristical Score). These metrics were designed to address the gap in task-centered evaluation.
The experiments revealed that applying the researchers' structure-aware fine-tuning to the LLaMA-7B model led to substantial performance gains, outshining other LLM counterparts across most measures. The researchers also conducted an in-depth error analysis and created an ability map across six dimensions (coverage, formatting, reasoning, comprehension, pragmatics, and hallucination) to highlight areas for future enhancements and suggest forthcoming research trajectories.
Critical Analysis
The researchers acknowledge that while LLMs have made remarkable progress, producing complex, structured tabular data remains a challenging task. Their study proposes a novel fine-tuning approach and introduces a comprehensive benchmark, Struc-Bench, to address this gap.
One potential limitation of the study is the scope of the benchmark, which may not capture the full breadth of real-world table structures and formatting requirements. Additionally, the researchers' fine-tuning method may not be as broadly applicable as desired, as it relies on a specific understanding of data structures.
Further research could explore more generalized approaches to imbuing LLMs with the ability to handle complex, structured data, beyond the table-generation task. Integrating TableLLaMA or other specialized table-focused models could also be a promising direction.
It would be valuable to see the researchers' FormatCoT technique applied to a wider range of tasks and formats beyond tables, to assess its broader applicability and robustness.
Conclusion
This study takes an important step in addressing the challenge of using LLMs for generating complex, structured tabular data. By introducing a novel fine-tuning method, the Struc-Bench benchmark, and new performance metrics, the researchers have made valuable contributions to the field.
The findings suggest that structure-aware fine-tuning can significantly improve LLMs' table-generation capabilities, outperforming their counterparts. This work paves the way for further research into enhancing LLMs' abilities to handle structured data, with potential applications in data analysis, report generation, and other domains that rely on well-organized information.
As language models continue to evolve, the insights and techniques presented in this study could inform the development of more versatile and capable AI systems that can seamlessly work with both text and structured data.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

StructBench: An Autogenerated Benchmark for Evaluating Large Language Model's Ability in Structure-Rich Text Understanding
Zhouhong Gu, Haoning Ye, Zeyang Zhou, Hongwei Feng, Yanghua Xiao
0
0
Given the substantial volumes of structured data held by many companies, enabling Large Language Models (LLMs) to directly understand structured text in non-structured forms could significantly enhance their capabilities across various business scenarios. To this end, we propose evaluation data generation method for assessing LLM's ability in understanding the structure-rich text, which generates structured data of controllable complexity based on manually crafted question templates and generation rules. Building on this generation method, we introduce StructBench, a benchmark comprising 6,032 questions across 8 different structured languages and 29 specific tasks. Furthermore, considering human proficiency in rule-based tasks, we also present StructBench-Hard, which includes 3,016 questions designed to further examine the gap between LLMs and human performance. Results indicate that the best-performing LLM currently achieve an accuracy of 65.0% on StructBench-Hard, while human accuracy reaches up to 95.7%. Moreover, while fine-tuning using StructBench can enhance existing LLMs' understanding of all structured languages, it does not necessarily improve performance across all task types. The benchmark and generation codes are open sourced in https://github.com/MikeGu721/StructBench
6/18/2024

StructLM: Towards Building Generalist Models for Structured Knowledge Grounding
Alex Zhuang, Ge Zhang, Tianyu Zheng, Xinrun Du, Junjie Wang, Weiming Ren, Stephen W. Huang, Jie Fu, Xiang Yue, Wenhu Chen
0
0
Structured data sources, such as tables, graphs, and databases, are ubiquitous knowledge sources. Despite the demonstrated capabilities of large language models (LLMs) on plain text, their proficiency in interpreting and utilizing structured data remains limited. Our investigation reveals a notable deficiency in LLMs' ability to process structured data, e.g., ChatGPT lags behind state-of-the-art (SoTA) model by an average of 35%. To augment the Structured Knowledge Grounding (SKG) capabilities in LLMs, we have developed a comprehensive instruction tuning dataset comprising 1.1 million examples. Utilizing this dataset, we train a series of models, referred to as StructLM, based on the Mistral and the CodeLlama model family, ranging from 7B to 34B parameters. Our StructLM series surpasses task-specific models on 16 out of 18 evaluated datasets and establishes new SoTA performance on 8 SKG tasks. Furthermore, StructLM demonstrates strong generalization across 6 novel held-out SKG tasks, outperforming TableLlama by an average of 35% and Flan-UL2 20B by an average of 10%. Contrary to expectations, we observe that scaling model size offers marginal benefits, with StructLM-34B showing only slight improvements over StructLM-7B. This suggests that structured knowledge grounding is still a challenging task and requires more innovative design to push to a new level.
4/24/2024
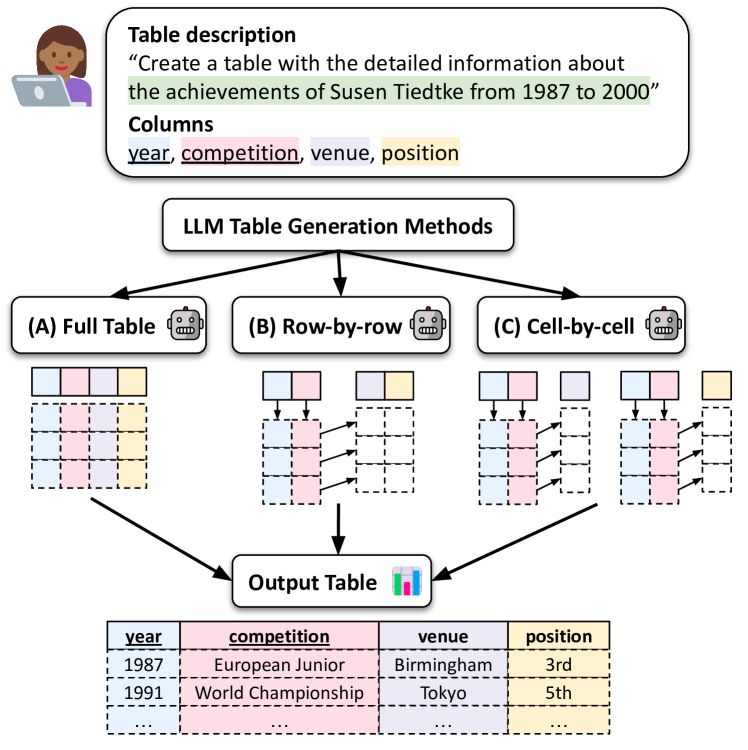
Generating Tables from the Parametric Knowledge of Language Models
Yevgeni Berkovitch, Oren Glickman, Amit Somech, Tomer Wolfson
0
0
We explore generating factual and accurate tables from the parametric knowledge of large language models (LLMs). While LLMs have demonstrated impressive capabilities in recreating knowledge bases and generating free-form text, we focus on generating structured tabular data, which is crucial in domains like finance and healthcare. We examine the table generation abilities of four state-of-the-art LLMs: GPT-3.5, GPT-4, Llama2-13B, and Llama2-70B, using three prompting methods for table generation: (a) full-table, (b) row-by-row; (c) cell-by-cell. For evaluation, we introduce a novel benchmark, WikiTabGen which contains 100 curated Wikipedia tables. Tables are further processed to ensure their factual correctness and manually annotated with short natural language descriptions. Our findings reveal that table generation remains a challenge, with GPT-4 reaching the highest accuracy at 19.6%. Our detailed analysis sheds light on how various table properties, such as size, table popularity, and numerical content, influence generation performance. This work highlights the unique challenges in LLM-based table generation and provides a solid evaluation framework for future research. Our code, prompts and data are all publicly available: https://github.com/analysis-bots/WikiTabGen
6/18/2024
💬
Unleashing the Potential of Large Language Models for Predictive Tabular Tasks in Data Science
Yazheng Yang, Yuqi Wang, Sankalok Sen, Lei Li, Qi Liu
0
0
In the domain of data science, the predictive tasks of classification, regression, and imputation of missing values are commonly encountered challenges associated with tabular data. This research endeavors to apply Large Language Models (LLMs) towards addressing these predictive tasks. Despite their proficiency in comprehending natural language, LLMs fall short in dealing with structured tabular data. This limitation stems from their lacking exposure to the intricacies of tabular data during their foundational training. Our research aims to mitigate this gap by compiling a comprehensive corpus of tables annotated with instructions and executing large-scale training of Llama-2 on this enriched dataset. Furthermore, we investigate the practical application of applying the trained model to zero-shot prediction, few-shot prediction, and in-context learning scenarios. Through extensive experiments, our methodology has shown significant improvements over existing benchmarks. These advancements highlight the efficacy of tailoring LLM training to solve table-related problems in data science, thereby establishing a new benchmark in the utilization of LLMs for enhancing tabular intelligence.
4/9/2024