Parrot Mind: Towards Explaining the Complex Task Reasoning of Pretrained Large Language Models with Template-Content Structure
2310.05452
0
0

Abstract
The pre-trained large language models (LLMs) have shown their extraordinary capacity to solve reasoning tasks, even on tasks that require a complex process involving multiple sub-steps. However, given the vast possible generation space of all the tasks, how the pretrained model learns the reasoning ability remains an open question. We firstly propose that an intrinsic structural constraint on the generated sequence of language-based reasoning -- we called it template-content structure (T-C structure) -- is the key to explain why LLMs can solve a large number of complex reasoning problems with limited training data by showing this structure can reduce the possible space from exponential level to linear level. Furthermore, by generalizing this structure to the hierarchical case, we demonstrate that models can achieve task composition, further reducing the space needed to learn from linear to logarithmic, thereby effectively learning on complex reasoning involving multiple steps. We provide both examples and formal theory of our T-C structure. We also experimentally validate the existence of the T-C structure in some current LLMs and its effectiveness for reasoning.
Create account to get full access
Overview
- Explores how large language models (LLMs) use "template-content structure" to reason about complex tasks
- Proposes a causal model to explain this reasoning process
- Shows how the model can approximate any causal function, providing a theoretical foundation
Plain English Explanation
This paper examines how large language models (LLMs) like GPT-3 are able to reason about and solve complex tasks. The key insight is that these models use a "template-content structure" - they break down the problem into a high-level template or schema, and then fill in the details with specific content.
For example, to answer a question about writing a business plan, the model might first identify the overall template (introduction, market analysis, financial projections, etc.), and then populate each section with relevant information. This allows the model to tackle complex, multi-step problems in a structured way.
The paper then proposes a causal model to explain this reasoning process. It shows that this template-content structure can approximate any causal function, providing a strong theoretical foundation. In other words, the model can capture a wide range of real-world relationships and scenarios, which helps explain the impressive capabilities of LLMs.
This work has important implications for understanding how large language models work "under the hood", and could inform the development of even more powerful AI systems. By shedding light on the core reasoning mechanisms of LLMs, it may be possible to enhance their general capabilities, as explored in related research on enhancing general agent capabilities with low-parameter LLMs.
Technical Explanation
The paper introduces a causal model to explain the complex task reasoning of large language models. The key insight is that these models use a "template-content structure" to break down and solve problems.
Specifically, the model posits that LLMs first identify a high-level template or schema for the task, which provides a structured framework. They then fill in the details of this template with relevant content, allowing them to reason about and complete the overall task.
To formalize this, the paper proposes a causal model where the template acts as a latent variable that mediates the relationship between the input and output. It then proves a "universal approximation theorem", showing that this template-content structure can approximate any causal function.
This provides a strong theoretical foundation for understanding the impressive reasoning capabilities of large language models, as explored in related work on evaluating reasoning behavior, helping large language models, and unlocking the potential of LLMs.
Critical Analysis
The paper provides a compelling theoretical framework for understanding the complex task reasoning of large language models. By proposing a causal model with a template-content structure, it offers a principled explanation for how LLMs are able to tackle multi-step problems in a structured way.
That said, the paper does not address some potential limitations or areas for further research. For example, it's unclear how well this model would scale to extremely complex tasks or domains with highly uncertain or ambiguous relationships. Additionally, the paper does not explore how the template-content structure might interact with other key architectural components of LLMs, such as attention mechanisms, as discussed in related work on attention-driven reasoning.
Further empirical validation and testing of the causal model on a wider range of tasks and datasets would also help strengthen the claims made in the paper. Exploring how this framework could be used to enhance the general capabilities of language models, as in research on low-parameter LLMs, would also be a valuable next step.
Conclusion
This paper presents an intriguing theoretical framework for understanding the complex task reasoning of large language models. By proposing a causal model with a template-content structure, it offers a principled explanation for how LLMs are able to break down and solve multi-step problems in a structured way.
The universal approximation theorem demonstrated in the paper provides a strong theoretical foundation, suggesting that this template-content approach can capture a wide range of real-world causal relationships. This work has important implications for advancing our understanding of large language models and informing the development of even more capable AI systems in the future.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
On the Empirical Complexity of Reasoning and Planning in LLMs
Liwei Kang, Zirui Zhao, David Hsu, Wee Sun Lee
0
0
Chain-of-thought (CoT), tree-of-thought (ToT), and related techniques work surprisingly well in practice for some complex reasoning tasks with Large Language Models (LLMs), but why? This work seeks the underlying reasons by conducting experimental case studies and linking the performance benefits to well-established sample and computational complexity principles in machine learning. We experimented with 6 reasoning tasks, ranging from grade school math, air travel planning, ..., to Blocksworld. The results suggest that (i) both CoT and ToT benefit significantly from task decomposition, which breaks a complex reasoning task into a sequence of steps with low sample complexity and explicitly outlines the reasoning structure, and (ii) for computationally hard reasoning tasks, the more sophisticated tree structure of ToT outperforms the linear structure of CoT. These findings provide useful guidelines for the use of LLM in solving reasoning tasks in practice.
6/19/2024
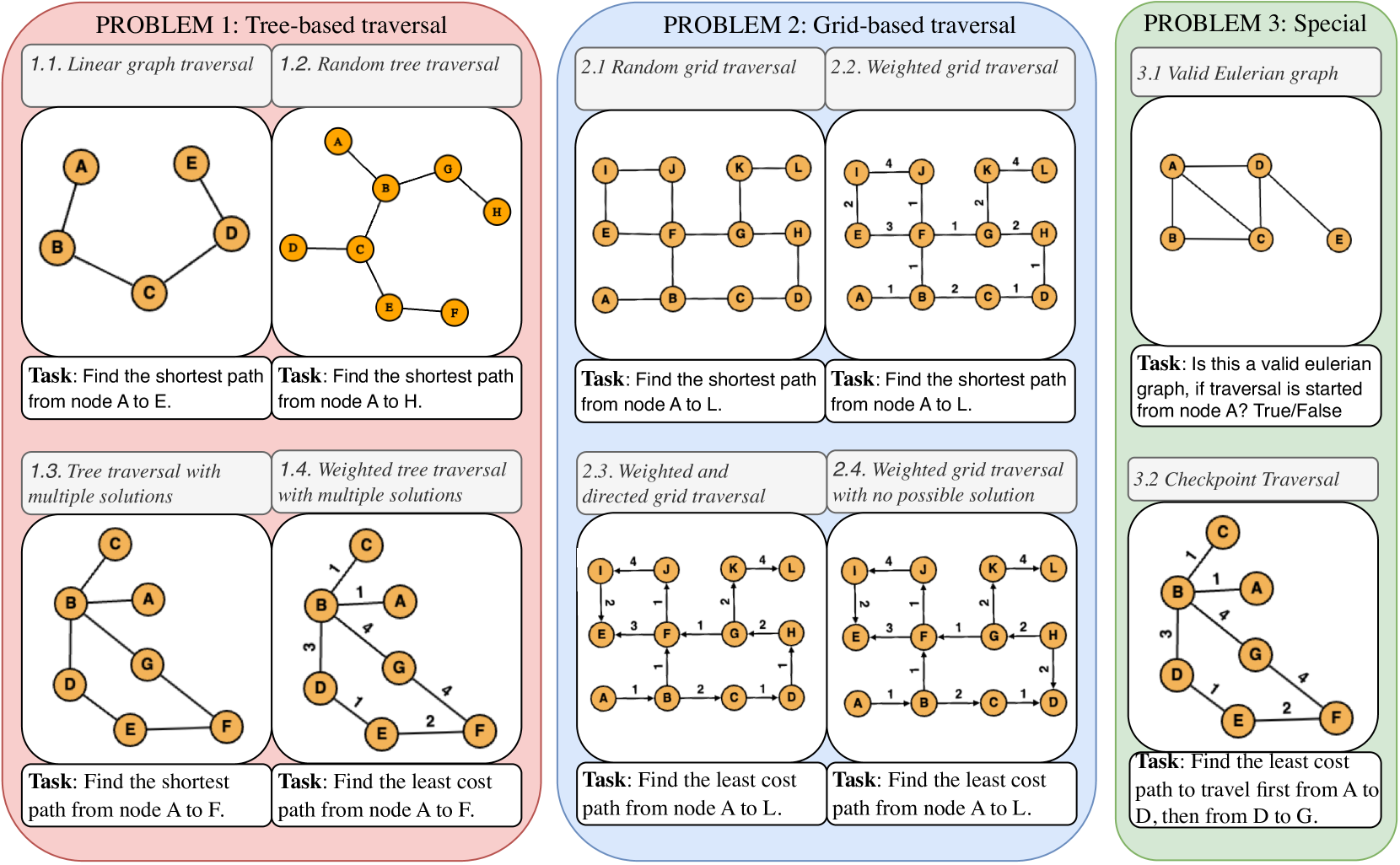
Can LLMs perform structured graph reasoning?
Palaash Agrawal, Shavak Vasania, Cheston Tan
0
0
Pretrained Large Language Models (LLMs) have demonstrated various reasoning capabilities through language-based prompts alone, particularly in unstructured task settings (tasks purely based on language semantics). However, LLMs often struggle with structured tasks, because of the inherent incompatibility of input representation. Reducing structured tasks to uni-dimensional language semantics often renders the problem trivial. Keeping the trade-off between LLM compatibility and structure complexity in mind, we design various graph reasoning tasks as a proxy to semi-structured tasks in this paper, in order to test the ability to navigate through representations beyond plain text in various LLMs. Particularly, we design 10 distinct problems of graph traversal, each representing increasing levels of complexity, and benchmark 5 different instruct-finetuned LLMs (GPT-4, GPT-3.5, Claude-2, Llama-2 and Palm-2) on the aforementioned tasks. Further, we analyse the performance of models across various settings such as varying sizes of graphs as well as different forms of k-shot prompting. We highlight various limitations, biases and properties of LLMs through this benchmarking process, such as an inverse relation to the average degrees of freedom of traversal per node in graphs, the overall negative impact of k-shot prompting on graph reasoning tasks, and a positive response bias which prevents LLMs from identifying the absence of a valid solution. Finally, we introduce a new prompting technique specially designed for graph traversal tasks (PathCompare), which demonstrates a notable increase in the performance of LLMs in comparison to standard prompting techniques such as Chain-of-Thought (CoT).
4/19/2024
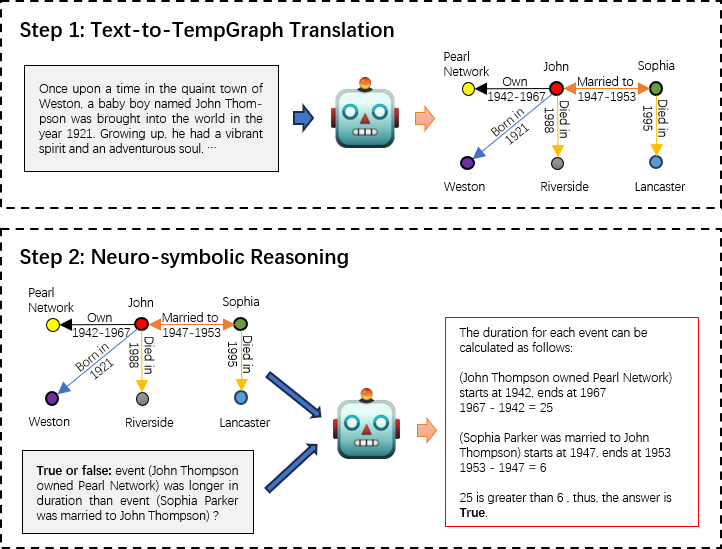
Large Language Models Can Learn Temporal Reasoning
Siheng Xiong, Ali Payani, Ramana Kompella, Faramarz Fekri
0
0
While large language models (LLMs) have demonstrated remarkable reasoning capabilities, they are not without their flaws and inaccuracies. Recent studies have introduced various methods to mitigate these limitations. Temporal reasoning (TR), in particular, presents a significant challenge for LLMs due to its reliance on diverse temporal concepts and intricate temporal logic. In this paper, we propose TG-LLM, a novel framework towards language-based TR. Instead of reasoning over the original context, we adopt a latent representation, temporal graph (TG) that enhances the learning of TR. A synthetic dataset (TGQA), which is fully controllable and requires minimal supervision, is constructed for fine-tuning LLMs on this text-to-TG translation task. We confirmed in experiments that the capability of TG translation learned on our dataset can be transferred to other TR tasks and benchmarks. On top of that, we teach LLM to perform deliberate reasoning over the TGs via Chain-of-Thought (CoT) bootstrapping and graph data augmentation. We observed that those strategies, which maintain a balance between usefulness and diversity, bring more reliable CoTs and final results than the vanilla CoT distillation.
6/12/2024

Eliciting Better Multilingual Structured Reasoning from LLMs through Code
Bryan Li, Tamer Alkhouli, Daniele Bonadiman, Nikolaos Pappas, Saab Mansour
0
0
The development of large language models (LLM) has shown progress on reasoning, though studies have largely considered either English or simple reasoning tasks. To address this, we introduce a multilingual structured reasoning and explanation dataset, termed xSTREET, that covers four tasks across six languages. xSTREET exposes a gap in base LLM performance between English and non-English reasoning tasks. We then propose two methods to remedy this gap, building on the insight that LLMs trained on code are better reasoners. First, at training time, we augment a code dataset with multilingual comments using machine translation while keeping program code as-is. Second, at inference time, we bridge the gap between training and inference by employing a prompt structure that incorporates step-by-step code primitives to derive new facts and find a solution. Our methods show improved multilingual performance on xSTREET, most notably on the scientific commonsense reasoning subtask. Furthermore, the models show no regression on non-reasoning tasks, thus demonstrating our techniques maintain general-purpose abilities.
6/13/2024