A Structure-Guided Gauss-Newton Method for Shallow ReLU Neural Network
2404.05064
0
0
Abstract
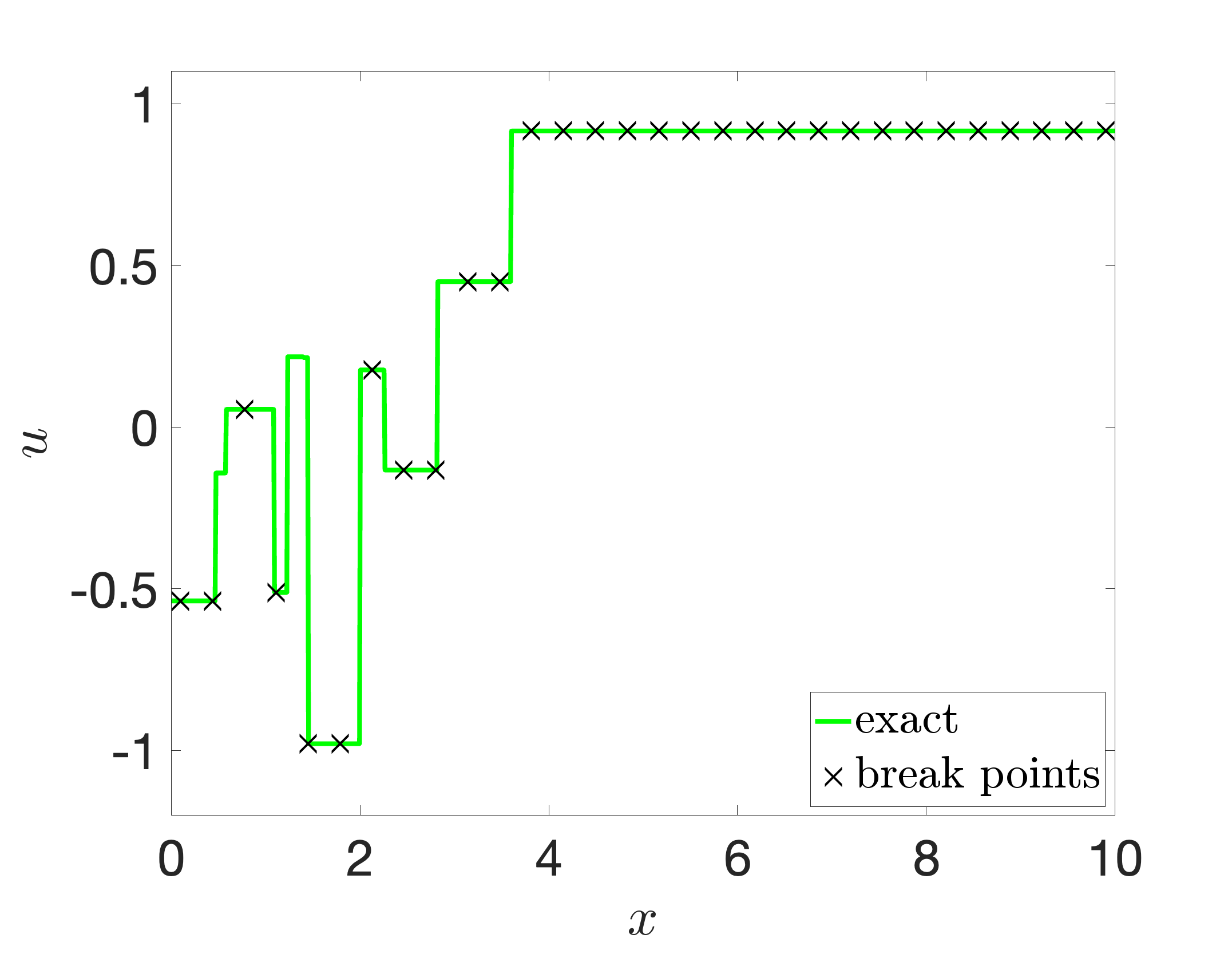
In this paper, we propose a structure-guided Gauss-Newton (SgGN) method for solving least squares problems using a shallow ReLU neural network. The method effectively takes advantage of both the least squares structure and the neural network structure of the objective function. By categorizing the weights and biases of the hidden and output layers of the network as nonlinear and linear parameters, respectively, the method iterates back and forth between the nonlinear and linear parameters. The nonlinear parameters are updated by a damped Gauss-Newton method and the linear ones are updated by a linear solver. Moreover, at the Gauss-Newton step, a special form of the Gauss-Newton matrix is derived for the shallow ReLU neural network and is used for efficient iterations. It is shown that the corresponding mass and Gauss-Newton matrices in the respective linear and nonlinear steps are symmetric and positive definite under reasonable assumptions. Thus, the SgGN method naturally produces an effective search direction without the need of additional techniques like shifting in the Levenberg-Marquardt method to achieve invertibility of the Gauss-Newton matrix. The convergence and accuracy of the method are demonstrated numerically for several challenging function approximation problems, especially those with discontinuities or sharp transition layers that pose significant challenges for commonly used training algorithms in machine learning.
Create account to get full access
Overview
- This paper proposes a new optimization algorithm called the Structure-Guided Gauss-Newton (SGGN) method for training shallow ReLU neural networks.
- The method leverages the structure of shallow ReLU networks to improve the efficiency and convergence of the standard Gauss-Newton optimization approach.
- Experiments on several benchmark datasets demonstrate the advantages of SGGN over existing optimization methods for training shallow ReLU networks.
Plain English Explanation
Neural networks are a powerful machine learning technique inspired by the human brain. They are made up of interconnected nodes, or "neurons," that can learn to perform complex tasks by adjusting the strength of their connections.
Training a neural network involves optimizing its internal parameters to minimize the error between the network's predictions and the desired outputs. This optimization process can be challenging, especially for deep neural networks with many layers.
The authors of this paper have developed a new optimization algorithm called the Structure-Guided Gauss-Newton (SGGN) method that is specifically designed for training shallow ReLU neural networks. Shallow networks have fewer layers than deep networks and can be faster and more efficient to train.
The key insight behind SGGN is that it takes advantage of the special structure of shallow ReLU networks to improve the standard Gauss-Newton optimization approach. Gauss-Newton is a powerful optimization method, but it can be computationally expensive, especially for large neural networks.
By exploiting the structure of shallow ReLU networks, SGGN is able to reduce the computational cost of Gauss-Newton while still maintaining its convergence properties. This makes SGGN a more efficient and effective way to train shallow ReLU networks compared to existing optimization methods.
Technical Explanation
The authors propose a new optimization algorithm called the Structure-Guided Gauss-Newton (SGGN) method for training shallow ReLU neural networks. SGGN builds on the standard Gauss-Newton optimization approach, which is known to be effective for training neural networks, but can be computationally expensive, especially for large networks.
The key insight behind SGGN is that it exploits the special structure of shallow ReLU networks to reduce the computational cost of Gauss-Newton while still maintaining its desirable convergence properties. Specifically, the authors show that the Gauss-Newton Hessian matrix for a shallow ReLU network has a particular block structure that can be leveraged to significantly simplify the optimization problem.
The authors derive efficient algorithms for computing the SGGN update directions and step sizes, and they show that SGGN can achieve faster convergence compared to other optimization methods, such as gradient descent and quasi-Newton methods.
The authors evaluate the performance of SGGN on several benchmark datasets and neural network architectures, including ReLU-based feedforward networks and Bayesian neural networks. The results demonstrate that SGGN can outperform existing optimization methods in terms of both convergence speed and final performance.
Critical Analysis
The authors present a well-designed and thorough study of their proposed SGGN optimization algorithm for training shallow ReLU neural networks. The key strengths of the paper include:
- A clear and detailed explanation of the SGGN method and how it exploits the structure of shallow ReLU networks to improve upon standard Gauss-Newton optimization.
- A comprehensive experimental evaluation on multiple benchmark datasets and network architectures, demonstrating the advantages of SGGN over existing optimization approaches.
- Insightful discussions of the theoretical properties of SGGN, such as its convergence guarantees and computational complexity.
However, the paper also has a few limitations:
- The focus is solely on shallow ReLU networks, and it's unclear how well the SGGN method would generalize to deeper or more complex network architectures.
- The experiments are limited to relatively small-scale datasets and networks, and it would be valuable to assess the performance of SGGN on larger-scale real-world problems.
- The paper does not provide much discussion of the potential drawbacks or limitations of the SGGN method, such as its sensitivity to hyperparameter tuning or its performance in the presence of noisy or imbalanced data.
Overall, the SGGN method appears to be a promising and well-executed contribution to the field of neural network optimization. However, further research and experimentation would be needed to fully understand the broader applicability and limitations of this approach.
Conclusion
This paper introduces a new optimization algorithm called the Structure-Guided Gauss-Newton (SGGN) method for training shallow ReLU neural networks. The key insight of SGGN is that it exploits the special structure of shallow ReLU networks to improve upon the standard Gauss-Newton optimization approach, making it more computationally efficient while maintaining its desirable convergence properties.
The authors demonstrate the advantages of SGGN through extensive experiments on various benchmark datasets and neural network architectures. The results show that SGGN can outperform existing optimization methods in terms of both convergence speed and final performance.
While the focus of this paper is on shallow ReLU networks, the SGGN method represents a promising step forward in the ongoing efforts to develop more efficient and effective optimization algorithms for training complex neural network models. Further research and exploration of the broader applicability and limitations of SGGN could lead to valuable insights and advancements in the field of deep learning.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🛠️
Exact Gauss-Newton Optimization for Training Deep Neural Networks
Mikalai Korbit, Adeyemi D. Adeoye, Alberto Bemporad, Mario Zanon
0
0
We present EGN, a stochastic second-order optimization algorithm that combines the generalized Gauss-Newton (GN) Hessian approximation with low-rank linear algebra to compute the descent direction. Leveraging the Duncan-Guttman matrix identity, the parameter update is obtained by factorizing a matrix which has the size of the mini-batch. This is particularly advantageous for large-scale machine learning problems where the dimension of the neural network parameter vector is several orders of magnitude larger than the batch size. Additionally, we show how improvements such as line search, adaptive regularization, and momentum can be seamlessly added to EGN to further accelerate the algorithm. Moreover, under mild assumptions, we prove that our algorithm converges to an $epsilon$-stationary point at a linear rate. Finally, our numerical experiments demonstrate that EGN consistently exceeds, or at most matches the generalization performance of well-tuned SGD, Adam, and SGN optimizers across various supervised and reinforcement learning tasks.
5/24/2024
↗️
Nonparametric regression using over-parameterized shallow ReLU neural networks
Yunfei Yang, Ding-Xuan Zhou
0
0
It is shown that over-parameterized neural networks can achieve minimax optimal rates of convergence (up to logarithmic factors) for learning functions from certain smooth function classes, if the weights are suitably constrained or regularized. Specifically, we consider the nonparametric regression of estimating an unknown $d$-variate function by using shallow ReLU neural networks. It is assumed that the regression function is from the Holder space with smoothness $alpha<(d+3)/2$ or a variation space corresponding to shallow neural networks, which can be viewed as an infinitely wide neural network. In this setting, we prove that least squares estimators based on shallow neural networks with certain norm constraints on the weights are minimax optimal, if the network width is sufficiently large. As a byproduct, we derive a new size-independent bound for the local Rademacher complexity of shallow ReLU neural networks, which may be of independent interest.
5/16/2024
🧠
Regularized Gauss-Newton for Optimizing Overparameterized Neural Networks
Adeyemi D. Adeoye, Philipp Christian Petersen, Alberto Bemporad
0
0
The generalized Gauss-Newton (GGN) optimization method incorporates curvature estimates into its solution steps, and provides a good approximation to the Newton method for large-scale optimization problems. GGN has been found particularly interesting for practical training of deep neural networks, not only for its impressive convergence speed, but also for its close relation with neural tangent kernel regression, which is central to recent studies that aim to understand the optimization and generalization properties of neural networks. This work studies a GGN method for optimizing a two-layer neural network with explicit regularization. In particular, we consider a class of generalized self-concordant (GSC) functions that provide smooth approximations to commonly-used penalty terms in the objective function of the optimization problem. This approach provides an adaptive learning rate selection technique that requires little to no tuning for optimal performance. We study the convergence of the two-layer neural network, considered to be overparameterized, in the optimization loop of the resulting GGN method for a given scaling of the network parameters. Our numerical experiments highlight specific aspects of GSC regularization that help to improve generalization of the optimized neural network. The code to reproduce the experimental results is available at https://github.com/adeyemiadeoye/ggn-score-nn.
4/24/2024
🧠
New!Fast Iterative Solver For Neural Network Method: II. 1D Diffusion-Reaction Problems And Data Fitting
Zhiqiang Cai, Anastassia Doktorova, Robert D. Falgout, C'esar Herrera
0
0
This paper expands the damped block Newton (dBN) method introduced recently in [4] for 1D diffusion-reaction equations and least-squares data fitting problems. To determine the linear parameters (the weights and bias of the output layer) of the neural network (NN), the dBN method requires solving systems of linear equations involving the mass matrix. While the mass matrix for local hat basis functions is tri-diagonal and well-conditioned, the mass matrix for NNs is dense and ill-conditioned. For example, the condition number of the NN mass matrix for quasi-uniform meshes is at least ${cal O}(n^4)$. We present a factorization of the mass matrix that enables solving the systems of linear equations in ${cal O}(n)$ operations. To determine the non-linear parameters (the weights and bias of the hidden layer), one step of a damped Newton method is employed at each iteration. A Gauss-Newton method is used in place of Newton for the instances in which the Hessian matrices are singular. This modified dBN is referred to as dBGN. For both methods, the computational cost per iteration is ${cal O}(n)$. Numerical results demonstrate the ability dBN and dBGN to efficiently achieve accurate results and outperform BFGS for select examples.
7/2/2024