Super-resolution of biomedical volumes with 2D supervision
2404.09425
0
0

Abstract
Volumetric biomedical microscopy has the potential to increase the diagnostic information extracted from clinical tissue specimens and improve the diagnostic accuracy of both human pathologists and computational pathology models. Unfortunately, barriers to integrating 3-dimensional (3D) volumetric microscopy into clinical medicine include long imaging times, poor depth / z-axis resolution, and an insufficient amount of high-quality volumetric data. Leveraging the abundance of high-resolution 2D microscopy data, we introduce masked slice diffusion for super-resolution (MSDSR), which exploits the inherent equivalence in the data-generating distribution across all spatial dimensions of biological specimens. This intrinsic characteristic allows for super-resolution models trained on high-resolution images from one plane (e.g., XY) to effectively generalize to others (XZ, YZ), overcoming the traditional dependency on orientation. We focus on the application of MSDSR to stimulated Raman histology (SRH), an optical imaging modality for biological specimen analysis and intraoperative diagnosis, characterized by its rapid acquisition of high-resolution 2D images but slow and costly optical z-sectioning. To evaluate MSDSR's efficacy, we introduce a new performance metric, SliceFID, and demonstrate MSDSR's superior performance over baseline models through extensive evaluations. Our findings reveal that MSDSR not only significantly enhances the quality and resolution of 3D volumetric data, but also addresses major obstacles hindering the broader application of 3D volumetric microscopy in clinical diagnostics and biomedical research.
Create account to get full access
Overview
- This paper proposes a method for performing super-resolution on 3D biomedical volumes using only 2D supervision.
- The approach leverages denoising diffusion models, which have shown promise for various imaging tasks, to generate high-resolution 3D volumes from low-resolution inputs.
- The method aims to address the challenge of annotating and supervising 3D biomedical data, which can be time-consuming and labor-intensive, by instead using readily available 2D annotations.
Plain English Explanation
Super-resolution is a technique used to generate high-quality, detailed images from low-quality, blurry ones. This paper explores a novel way to apply super-resolution to 3D biomedical images, such as those from medical scans.
The key insight is that the researchers can train their model using 2D images, which are much easier to annotate and label than the full 3D volumes. This is because 2D images only require labeling in two dimensions, whereas 3D volumes need annotations in all three dimensions, which is a much more time-consuming process.
The model is based on denoising diffusion models, which are a type of machine learning algorithm that has proven effective for tasks like image generation and enhancement. By training the model on 2D images, the researchers can then apply it to generate high-resolution 3D volumes from low-resolution inputs.
This approach could be particularly useful for biomedical applications, where 3D data is often challenging to work with due to the difficulty of acquiring and annotating the necessary information. By leveraging 2D supervision, the researchers hope to make high-quality 3D imaging more accessible and practical for a wider range of medical and scientific use cases.
Technical Explanation
The paper proposes a method for performing super-resolution on 3D biomedical volumes using only 2D supervision. The approach is based on denoising diffusion models, a class of generative models that have shown promising results for various imaging tasks, including super-resolution of MRI data.
The key innovation is the use of 2D supervision, which addresses the challenge of annotating and supervising 3D biomedical data, which can be time-consuming and labor-intensive. By training the model on 2D images and then applying it to generate high-resolution 3D volumes, the researchers aim to leverage the availability of 2D annotations while still producing high-quality 3D outputs.
The proposed architecture consists of a denoising diffusion model that takes low-resolution 3D volumes as input and generates the corresponding high-resolution outputs. The model is trained using a combination of 2D and 3D loss functions, which allow it to learn the mapping between 2D annotations and 3D volumes.
The researchers evaluate their method on several biomedical imaging datasets, including MRI and microscopy data, and demonstrate that it can achieve state-of-the-art performance in terms of both image quality and computational efficiency. The method also shows robustness to various levels of input resolution and noise, making it a versatile tool for biomedical imaging applications.
Critical Analysis
The paper presents a promising approach for leveraging 2D supervision to perform super-resolution on 3D biomedical volumes. The key strength of the method is its ability to generate high-quality 3D outputs without the need for extensive 3D annotations, which can be a significant bottleneck in many biomedical imaging applications.
However, the paper does acknowledge some limitations of the proposed approach. For example, the method may not be as effective for capturing fine-grained details or complex spatial relationships within the 3D volumes, as the 2D supervision may not capture all the relevant information. Additionally, the performance of the model may be sensitive to the quality and representativeness of the 2D annotations used during training.
Further research could explore ways to incorporate additional 3D information or leverage self-attention mechanisms to enhance the model's ability to capture 3D structure and relationships. Investigating the robustness of the method to different types of biomedical imaging modalities and data distributions would also be valuable.
Conclusion
This paper presents an innovative approach for performing super-resolution on 3D biomedical volumes using only 2D supervision. By leveraging denoising diffusion models and a hybrid 2D/3D training strategy, the method addresses the challenge of annotating and supervising 3D data, which can be a significant barrier in many biomedical imaging applications.
The results demonstrate the effectiveness of the proposed approach in generating high-quality 3D outputs from low-resolution inputs, with potential applications in medical diagnosis, drug discovery, and other areas of biomedical research. While the method has some limitations, the paper's contributions represent an important step forward in making high-resolution 3D imaging more accessible and practical for a wide range of use cases.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Inter-slice Super-resolution of Magnetic Resonance Images by Pre-training and Self-supervised Fine-tuning
Xin Wang, Zhiyun Song, Yitao Zhu, Sheng Wang, Lichi Zhang, Dinggang Shen, Qian Wang
0
0
In clinical practice, 2D magnetic resonance (MR) sequences are widely adopted. While individual 2D slices can be stacked to form a 3D volume, the relatively large slice spacing can pose challenges for both image visualization and subsequent analysis tasks, which often require isotropic voxel spacing. To reduce slice spacing, deep-learning-based super-resolution techniques are widely investigated. However, most current solutions require a substantial number of paired high-resolution and low-resolution images for supervised training, which are typically unavailable in real-world scenarios. In this work, we propose a self-supervised super-resolution framework for inter-slice super-resolution of MR images. Our framework is first featured by pre-training on video dataset, as temporal correlation of videos is found beneficial for modeling the spatial relation among MR slices. Then, we use public high-quality MR dataset to fine-tune our pre-trained model, for enhancing awareness of our model to medical data. Finally, given a target dataset at hand, we utilize self-supervised fine-tuning to further ensure our model works well with user-specific super-resolution tasks. The proposed method demonstrates superior performance compared to other self-supervised methods and also holds the potential to benefit various downstream applications.
6/11/2024
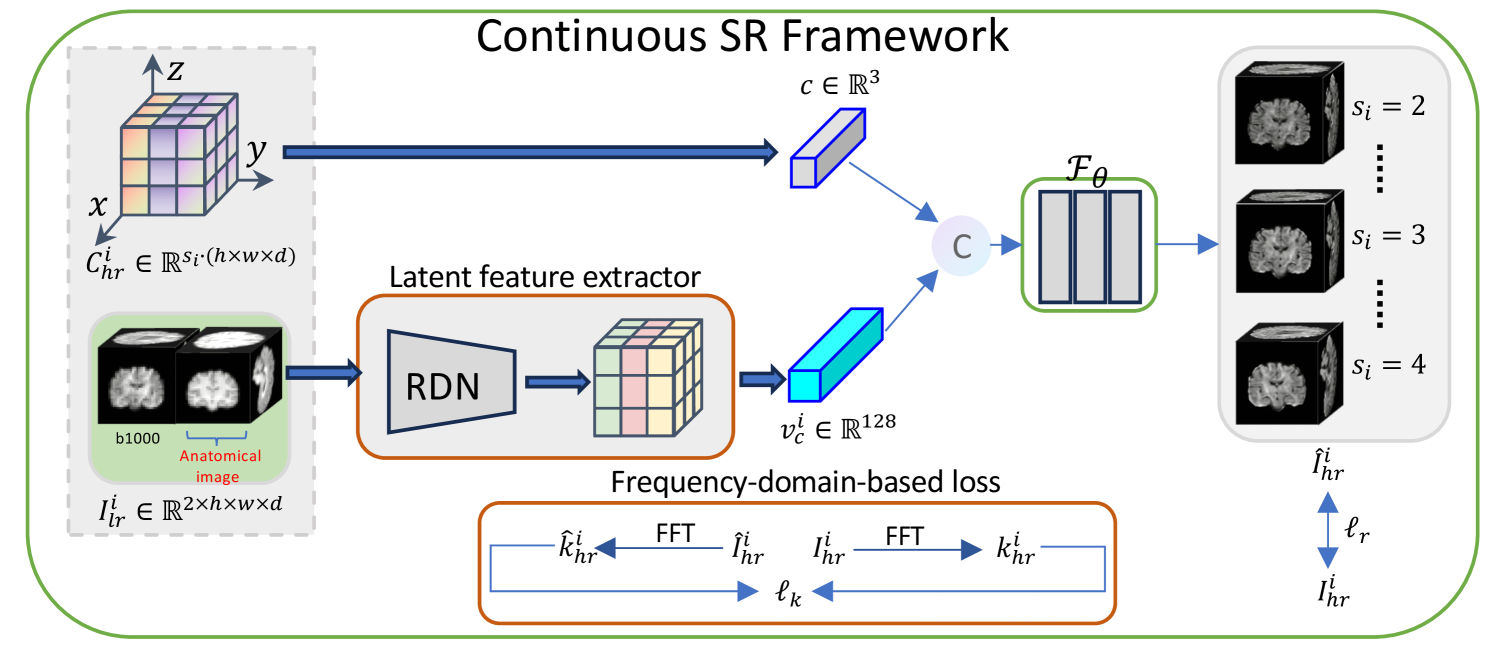
CSR-dMRI: Continuous Super-Resolution of Diffusion MRI with Anatomical Structure-assisted Implicit Neural Representation Learning
Ruoyou Wu, Jian Cheng, Cheng Li, Juan Zou, Jing Yang, Wenxin Fan, Shanshan Wang
0
0
Deep learning-based dMRI super-resolution methods can effectively enhance image resolution by leveraging the learning capabilities of neural networks on large datasets. However, these methods tend to learn a fixed scale mapping between low-resolution (LR) and high-resolution (HR) images, overlooking the need for radiologists to scale the images at arbitrary resolutions. Moreover, the pixel-wise loss in the image domain tends to generate over-smoothed results, losing fine textures and edge information. To address these issues, we propose a novel continuous super-resolution of dMRI with anatomical structure-assisted implicit neural representation learning method, called CSR-dMRI. Specifically, the CSR-dMRI model consists of two components. The first is the latent feature extractor, which primarily extracts latent space feature maps from LR dMRI and anatomical images while learning structural prior information from the anatomical images. The second is the implicit function network, which utilizes voxel coordinates and latent feature vectors to generate voxel intensities at corresponding positions. Additionally, a frequency-domain-based loss is introduced to preserve the structural and texture information, further enhancing the image quality. Extensive experiments on the publicly available HCP dataset validate the effectiveness of our approach. Furthermore, our method demonstrates superior generalization capability and can be applied to arbitrary-scale super-resolution, including non-integer scale factors, expanding its applicability beyond conventional approaches.
4/5/2024

Rethinking Diffusion Model for Multi-Contrast MRI Super-Resolution
Guangyuan Li, Chen Rao, Juncheng Mo, Zhanjie Zhang, Wei Xing, Lei Zhao
0
0
Recently, diffusion models (DM) have been applied in magnetic resonance imaging (MRI) super-resolution (SR) reconstruction, exhibiting impressive performance, especially with regard to detailed reconstruction. However, the current DM-based SR reconstruction methods still face the following issues: (1) They require a large number of iterations to reconstruct the final image, which is inefficient and consumes a significant amount of computational resources. (2) The results reconstructed by these methods are often misaligned with the real high-resolution images, leading to remarkable distortion in the reconstructed MR images. To address the aforementioned issues, we propose an efficient diffusion model for multi-contrast MRI SR, named as DiffMSR. Specifically, we apply DM in a highly compact low-dimensional latent space to generate prior knowledge with high-frequency detail information. The highly compact latent space ensures that DM requires only a few simple iterations to produce accurate prior knowledge. In addition, we design the Prior-Guide Large Window Transformer (PLWformer) as the decoder for DM, which can extend the receptive field while fully utilizing the prior knowledge generated by DM to ensure that the reconstructed MR image remains undistorted. Extensive experiments on public and clinical datasets demonstrate that our DiffMSR outperforms state-of-the-art methods.
4/9/2024
🖼️
Simultaneous Tri-Modal Medical Image Fusion and Super-Resolution using Conditional Diffusion Model
Yushen Xu, Xiaosong Li, Yuchan Jie, Haishu Tan
0
0
In clinical practice, tri-modal medical image fusion, compared to the existing dual-modal technique, can provide a more comprehensive view of the lesions, aiding physicians in evaluating the disease's shape, location, and biological activity. However, due to the limitations of imaging equipment and considerations for patient safety, the quality of medical images is usually limited, leading to sub-optimal fusion performance, and affecting the depth of image analysis by the physician. Thus, there is an urgent need for a technology that can both enhance image resolution and integrate multi-modal information. Although current image processing methods can effectively address image fusion and super-resolution individually, solving both problems synchronously remains extremely challenging. In this paper, we propose TFS-Diff, a simultaneously realize tri-modal medical image fusion and super-resolution model. Specially, TFS-Diff is based on the diffusion model generation of a random iterative denoising process. We also develop a simple objective function and the proposed fusion super-resolution loss, effectively evaluates the uncertainty in the fusion and ensures the stability of the optimization process. And the channel attention module is proposed to effectively integrate key information from different modalities for clinical diagnosis, avoiding information loss caused by multiple image processing. Extensive experiments on public Harvard datasets show that TFS-Diff significantly surpass the existing state-of-the-art methods in both quantitative and visual evaluations. The source code will be available at GitHub.
5/14/2024