A Survey on Complex Tasks for Goal-Directed Interactive Agents

0
🏅
Sign in to get full access
Overview
- Goal-directed interactive agents can help humans with various tasks in daily life
- Recent advances in large language models (LLMs) have led to new, more challenging tasks to evaluate these agents
- Understanding the different challenges these tasks pose is crucial for properly assessing agent performance
Plain English Explanation
Goal-directed interactive agents are computer programs that can autonomously complete tasks by interacting with their environment. These agents can assist humans with various activities in their everyday lives. Recent breakthroughs in large language models (LLMs) have led to the development of new, increasingly complex tasks that can be used to evaluate the capabilities of these interactive agents.
To properly understand how well these agents perform across these diverse tasks, it's important to examine the different challenges they present. This survey compiles relevant tasks and environments for evaluating goal-directed interactive agents, organizing them based on factors that are crucial for understanding the current limitations and obstacles these agents face.
The researchers have also created a project website where you can find an up-to-date collection of resources related to this topic.
Technical Explanation
This survey article aims to compile and structure the various tasks and environments that can be used to evaluate the performance of goal-directed interactive agents. These agents are designed to autonomously complete tasks by interacting with their surroundings, and they have the potential to assist humans in many aspects of daily life.
The researchers note that recent advancements in large language models (LLMs) have led to the emergence of an increasingly diverse and challenging set of tasks for evaluating the capabilities of these interactive agents. To properly contextualize the performance of these agents across these varied tasks, it is crucial to understand the different challenges they face.
By compiling relevant tasks and environments and structuring them along dimensions that are relevant for understanding current obstacles, the survey aims to provide a comprehensive overview of the landscape for evaluating goal-directed interactive agents.
Critical Analysis
The survey provides a valuable resource for researchers and developers working on goal-directed interactive agents. By cataloging the various tasks and environments used to assess these agents, the authors have created a useful reference point for understanding the current state of the field and the key challenges that must be addressed.
One potential limitation of the survey is that it may not capture the full breadth of emerging tasks and environments, as the field is rapidly evolving. The researchers acknowledge this and have created a project website to maintain an up-to-date compilation of resources, which helps mitigate this concern.
Additionally, the survey focuses on the tasks and environments themselves, without delving too deeply into the specific approaches or architectures used to address them. Exploring these aspects in more detail could provide additional insights into the current state of the field and the potential paths forward.
Conclusion
This survey offers a comprehensive overview of the tasks and environments used to evaluate the performance of goal-directed interactive agents. By structuring these elements along relevant dimensions, the authors have created a valuable resource for researchers and developers working in this rapidly evolving field.
The insights gained from this survey can help inform the development of more capable and versatile interactive agents, which in turn can lead to improvements in the ways these agents can assist humans in their daily lives. As the field continues to progress, the survey's project website will be a valuable resource for staying up-to-date on the latest advancements and challenges.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🏅
0
New!A Survey on Complex Tasks for Goal-Directed Interactive Agents
Mareike Hartmann, Alexander Koller
Goal-directed interactive agents, which autonomously complete tasks through interactions with their environment, can assist humans in various domains of their daily lives. Recent advances in large language models (LLMs) led to a surge of new, more and more challenging tasks to evaluate such agents. To properly contextualize performance across these tasks, it is imperative to understand the different challenges they pose to agents. To this end, this survey compiles relevant tasks and environments for evaluating goal-directed interactive agents, structuring them along dimensions relevant for understanding current obstacles. An up-to-date compilation of relevant resources can be found on our project website: https://coli-saar.github.io/interactive-agents.
Read more9/30/2024
💬
0
SelfGoal: Your Language Agents Already Know How to Achieve High-level Goals
Ruihan Yang, Jiangjie Chen, Yikai Zhang, Siyu Yuan, Aili Chen, Kyle Richardson, Yanghua Xiao, Deqing Yang
Language agents powered by large language models (LLMs) are increasingly valuable as decision-making tools in domains such as gaming and programming. However, these agents often face challenges in achieving high-level goals without detailed instructions and in adapting to environments where feedback is delayed. In this paper, we present SelfGoal, a novel automatic approach designed to enhance agents' capabilities to achieve high-level goals with limited human prior and environmental feedback. The core concept of SelfGoal involves adaptively breaking down a high-level goal into a tree structure of more practical subgoals during the interaction with environments while identifying the most useful subgoals and progressively updating this structure. Experimental results demonstrate that SelfGoal significantly enhances the performance of language agents across various tasks, including competitive, cooperative, and deferred feedback environments. Project page: https://selfgoal-agent.github.io.
Read more6/10/2024
0
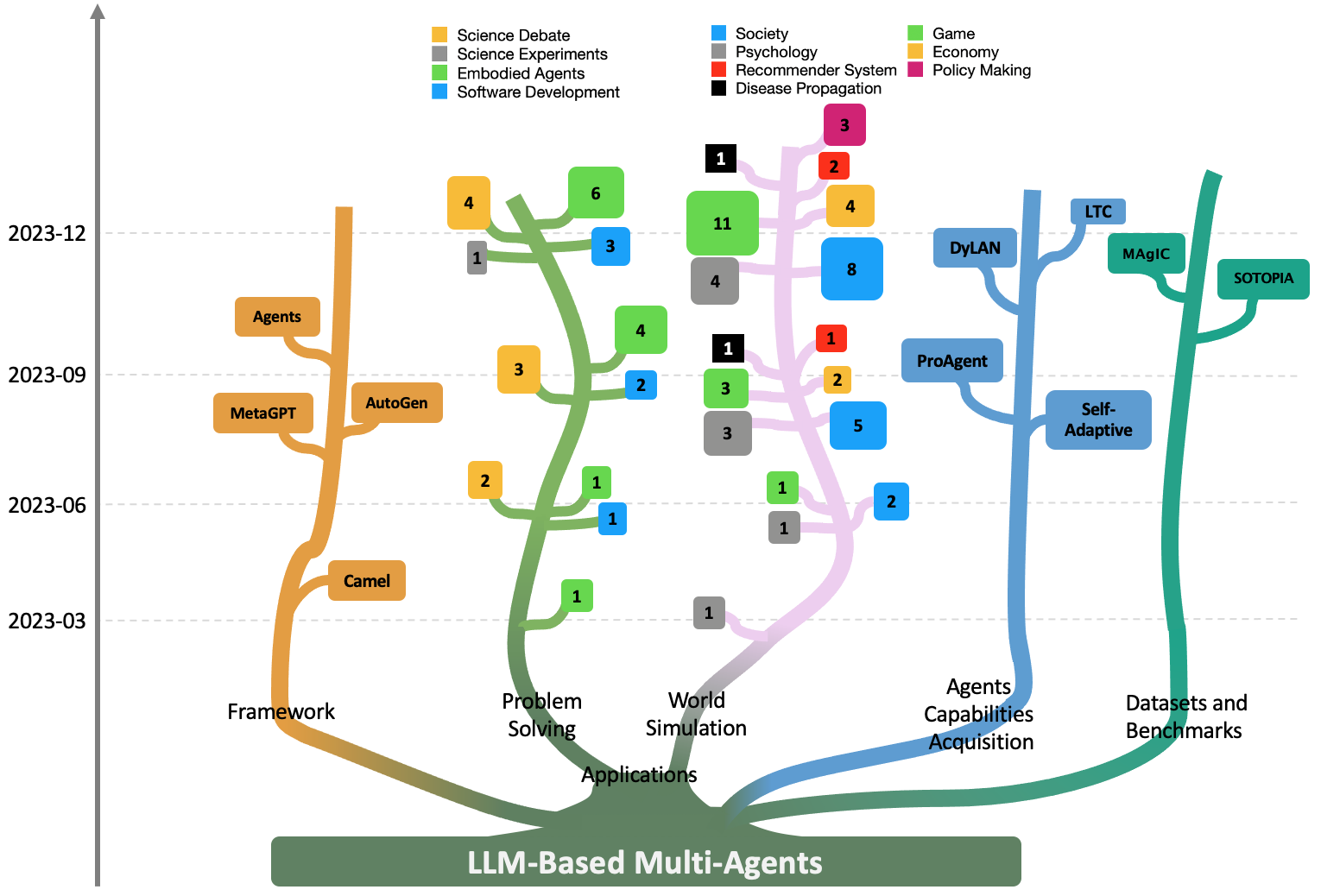
Large Language Model based Multi-Agents: A Survey of Progress and Challenges
Taicheng Guo, Xiuying Chen, Yaqi Wang, Ruidi Chang, Shichao Pei, Nitesh V. Chawla, Olaf Wiest, Xiangliang Zhang
Large Language Models (LLMs) have achieved remarkable success across a wide array of tasks. Due to the impressive planning and reasoning abilities of LLMs, they have been used as autonomous agents to do many tasks automatically. Recently, based on the development of using one LLM as a single planning or decision-making agent, LLM-based multi-agent systems have achieved considerable progress in complex problem-solving and world simulation. To provide the community with an overview of this dynamic field, we present this survey to offer an in-depth discussion on the essential aspects of multi-agent systems based on LLMs, as well as the challenges. Our goal is for readers to gain substantial insights on the following questions: What domains and environments do LLM-based multi-agents simulate? How are these agents profiled and how do they communicate? What mechanisms contribute to the growth of agents' capacities? For those interested in delving into this field of study, we also summarize the commonly used datasets or benchmarks for them to have convenient access. To keep researchers updated on the latest studies, we maintain an open-source GitHub repository, dedicated to outlining the research on LLM-based multi-agent systems.
Read more4/22/2024
⚙️
0
WebArena: A Realistic Web Environment for Building Autonomous Agents
Shuyan Zhou, Frank F. Xu, Hao Zhu, Xuhui Zhou, Robert Lo, Abishek Sridhar, Xianyi Cheng, Tianyue Ou, Yonatan Bisk, Daniel Fried, Uri Alon, Graham Neubig
With advances in generative AI, there is now potential for autonomous agents to manage daily tasks via natural language commands. However, current agents are primarily created and tested in simplified synthetic environments, leading to a disconnect with real-world scenarios. In this paper, we build an environment for language-guided agents that is highly realistic and reproducible. Specifically, we focus on agents that perform tasks on the web, and create an environment with fully functional websites from four common domains: e-commerce, social forum discussions, collaborative software development, and content management. Our environment is enriched with tools (e.g., a map) and external knowledge bases (e.g., user manuals) to encourage human-like task-solving. Building upon our environment, we release a set of benchmark tasks focusing on evaluating the functional correctness of task completions. The tasks in our benchmark are diverse, long-horizon, and designed to emulate tasks that humans routinely perform on the internet. We experiment with several baseline agents, integrating recent techniques such as reasoning before acting. The results demonstrate that solving complex tasks is challenging: our best GPT-4-based agent only achieves an end-to-end task success rate of 14.41%, significantly lower than the human performance of 78.24%. These results highlight the need for further development of robust agents, that current state-of-the-art large language models are far from perfect performance in these real-life tasks, and that WebArena can be used to measure such progress.
Read more4/17/2024