Swin2-MoSE: A New Single Image Super-Resolution Model for Remote Sensing

0
🖼️
Sign in to get full access
Overview
- Current satellite technologies may not always meet desired spectral and spatial resolution requirements, leading to increased interest in Remote-Sensing Single-Image Super-Resolution (RS-SISR) techniques.
- This paper presents Swin2-MoSE, an enhanced version of the Swin2SR model, which introduces MoE-SM (an enhanced Mixture-of-Experts) and explores the interaction between positional encodings.
- The model also utilizes a combination of Normalized-Cross-Correlation (NCC) and Structural Similarity Index Measure (SSIM) losses to address limitations of the typical Mean Squared Error (MSE) loss.
Plain English Explanation
Satellites are used to gather a lot of important data about our world, like information about the environment, weather, and more. However, the cameras and sensors on these satellites don't always have as much detail or resolution as we'd like. This can make it harder to use the data for things like monitoring changes over time or making important decisions.
To address this, researchers have been developing super-resolution techniques that can take the lower-quality satellite images and intelligently "upscale" them to create higher-quality versions. The Swin2-MoSE model is an example of one of these advanced super-resolution techniques.
The key innovations in Swin2-MoSE include:
- An enhanced "Mixture-of-Experts" module that helps the model learn more efficiently
- A new way of using positional information that allows the different components of the model to work together better
- Using a combination of two different loss functions to train the model, which helps it produce higher-quality results compared to just using the standard loss function
By incorporating these advances, the Swin2-MoSE model is able to outperform other state-of-the-art super-resolution models when applied to satellite imagery. This could help unlock new applications and insights from satellite data that were previously limited by the resolution of the images.
Technical Explanation
The Swin2-MoSE model builds upon the Swin2SR architecture, which is a Transformer-based super-resolution model. Swin2-MoSE introduces two key innovations:
-
MoE-SM (Mixture-of-Experts with Smart Merger): This is an enhanced version of the Mixture-of-Experts (MoE) module, which replaces the standard Feed-Forward layer in the Transformer blocks. MoE-SM includes a "Smart Merger" component that learns how to effectively combine the outputs of the individual expert sub-networks. It also uses a new per-example routing strategy instead of the more common per-token routing.
-
Positional Encoding Analysis: The authors analyze how the various positional encoding mechanisms (per-channel bias and per-head bias) interact with each other. They demonstrate that these components can work together in a complementary way to improve performance.
Additionally, the Swin2-MoSE model utilizes a combination of Normalized-Cross-Correlation (NCC) and Structural Similarity Index Measure (SSIM) losses, rather than the standard Mean Squared Error (MSE) loss. This is done to address the limitations of MSE, which can struggle to capture perceptual quality and structural information.
Experimental results on the Sen2Venus and OLI2MSI datasets show that Swin2-MoSE outperforms other state-of-the-art models by up to 0.958 dB in PSNR (a measure of image quality) for 2x, 3x, and 4x resolution upscaling tasks. The authors also demonstrate the effectiveness of Swin2-MoSE on a semantic segmentation task using the SeasoNet dataset.
Critical Analysis
The paper provides a comprehensive and technically detailed exploration of the Swin2-MoSE model and its innovations. The authors have carefully designed experiments to evaluate the model's performance on various remote sensing tasks and datasets.
One potential limitation is that the paper does not delve deeply into the computational complexity and inference speed of the Swin2-MoSE model, which could be an important consideration for real-world deployment. The authors could have provided more analysis on the tradeoffs between model performance and efficiency.
Additionally, while the authors mention the limitations of the standard MSE loss, they could have further discussed the rationale and potential drawbacks of using the NCC and SSIM losses, as well as how they compare to other perceptual loss functions used in the super-resolution literature.
Overall, the Swin2-MoSE model presents an interesting and promising approach to remote sensing super-resolution, with several novel technical contributions. Further research could explore the model's performance on a wider range of real-world applications and datasets, as well as potential optimizations for efficient deployment.
Conclusion
The Swin2-MoSE model introduces several advancements to the field of Remote-Sensing Single-Image Super-Resolution (RS-SISR), including an enhanced Mixture-of-Experts module and a novel analysis of positional encodings. By leveraging these innovations and using a combination of NCC and SSIM losses, the model is able to outperform other state-of-the-art super-resolution techniques on various remote sensing datasets and tasks.
These improvements in super-resolution could lead to new insights and applications that were previously limited by the low spatial and spectral resolution of satellite imagery. As remote sensing technologies continue to evolve, models like Swin2-MoSE will play an increasingly important role in extracting maximum value from available data, benefiting fields such as environmental monitoring, urban planning, and disaster response.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🖼️
0
Swin2-MoSE: A New Single Image Super-Resolution Model for Remote Sensing
Leonardo Rossi, Vittorio Bernuzzi, Tomaso Fontanini, Massimo Bertozzi, Andrea Prati
Due to the limitations of current optical and sensor technologies and the high cost of updating them, the spectral and spatial resolution of satellites may not always meet desired requirements. For these reasons, Remote-Sensing Single-Image Super-Resolution (RS-SISR) techniques have gained significant interest. In this paper, we propose Swin2-MoSE model, an enhanced version of Swin2SR. Our model introduces MoE-SM, an enhanced Mixture-of-Experts (MoE) to replace the Feed-Forward inside all Transformer block. MoE-SM is designed with Smart-Merger, and new layer for merging the output of individual experts, and with a new way to split the work between experts, defining a new per-example strategy instead of the commonly used per-token one. Furthermore, we analyze how positional encodings interact with each other, demonstrating that per-channel bias and per-head bias can positively cooperate. Finally, we propose to use a combination of Normalized-Cross-Correlation (NCC) and Structural Similarity Index Measure (SSIM) losses, to avoid typical MSE loss limitations. Experimental results demonstrate that Swin2-MoSE outperforms SOTA by up to 0.377 ~ 0.958 dB (PSNR) on task of 2x, 3x and 4x resolution-upscaling (Sen2Venus and OLI2MSI datasets). We show the efficacy of Swin2-MoSE, applying it to a semantic segmentation task (SeasoNet dataset). Code and pretrained are available on https://github.com/IMPLabUniPr/swin2-mose/tree/official_code
Read more4/30/2024

0
Perceptual-Distortion Balanced Image Super-Resolution is a Multi-Objective Optimization Problem
Qiwen Zhu, Yanjie Wang, Shilv Cai, Liqun Chen, Jiahuan Zhou, Luxin Yan, Sheng Zhong, Xu Zou
Training Single-Image Super-Resolution (SISR) models using pixel-based regression losses can achieve high distortion metrics scores (e.g., PSNR and SSIM), but often results in blurry images due to insufficient recovery of high-frequency details. Conversely, using GAN or perceptual losses can produce sharp images with high perceptual metric scores (e.g., LPIPS), but may introduce artifacts and incorrect textures. Balancing these two types of losses can help achieve a trade-off between distortion and perception, but the challenge lies in tuning the loss function weights. To address this issue, we propose a novel method that incorporates Multi-Objective Optimization (MOO) into the training process of SISR models to balance perceptual quality and distortion. We conceptualize the relationship between loss weights and image quality assessment (IQA) metrics as black-box objective functions to be optimized within our Multi-Objective Bayesian Optimization Super-Resolution (MOBOSR) framework. This approach automates the hyperparameter tuning process, reduces overall computational cost, and enables the use of numerous loss functions simultaneously. Extensive experiments demonstrate that MOBOSR outperforms state-of-the-art methods in terms of both perceptual quality and distortion, significantly advancing the perception-distortion Pareto frontier. Our work points towards a new direction for future research on balancing perceptual quality and fidelity in nearly all image restoration tasks. The source code and pretrained models are available at: https://github.com/ZhuKeven/MOBOSR.
Read more9/6/2024
0
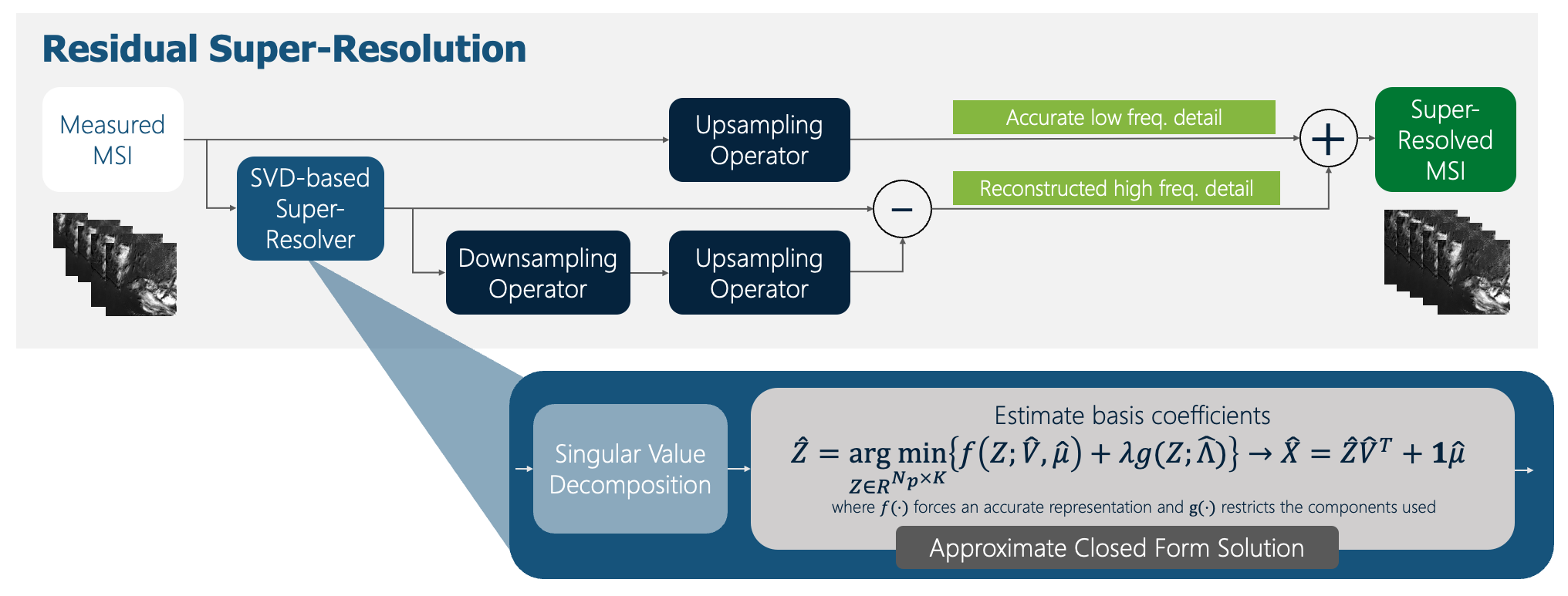
ResSR: A Residual Approach to Super-Resolving Multispectral Images
Haley Duba-Sullivan, Emma J. Reid, Sophie Voisin, Charles A. Bouman, Gregery T. Buzzard
Multispectral imaging sensors typically have wavelength-dependent resolution, which reduces the ability to distinguish small features in some spectral bands. Existing super-resolution methods upsample a multispectral image (MSI) to achieve a common resolution across all bands but are typically sensor-specific, computationally expensive, and may assume invariant image statistics across multiple length scales. In this paper, we introduce ResSR, an efficient and modular residual-based method for super-resolving the lower-resolution bands of a multispectral image. ResSR uses singular value decomposition (SVD) to identify correlations across spectral bands and then applies a residual correction process that corrects only the high-spatial frequency components of the upsampled bands. The SVD formulation improves the conditioning and simplifies the super-resolution problem, and the residual method retains accurate low-spatial frequencies from the measured data while incorporating high-spatial frequency detail from the SVD solution. While ResSR is formulated as the solution to an optimization problem, we derive an approximate closed-form solution that is fast and accurate. We formulate ResSR for any number of distinct resolutions, enabling easy application to any MSI. In a series of experiments on simulated and measured Sentinel-2 MSIs, ResSR is shown to produce image quality comparable to or better than alternative algorithms. However, it is computationally faster and can run on larger images, making it useful for processing large data sets.
Read more8/26/2024

0
SwinFuSR: an image fusion-inspired model for RGB-guided thermal image super-resolution
Cyprien Arnold, Philippe Jouvet, Lama Seoud
Thermal imaging plays a crucial role in various applications, but the inherent low resolution of commonly available infrared (IR) cameras limits its effectiveness. Conventional super-resolution (SR) methods often struggle with thermal images due to their lack of high-frequency details. Guided SR leverages information from a high-resolution image, typically in the visible spectrum, to enhance the reconstruction of a high-res IR image from the low-res input. Inspired by SwinFusion, we propose SwinFuSR, a guided SR architecture based on Swin transformers. In real world scenarios, however, the guiding modality (e.g. RBG image) may be missing, so we propose a training method that improves the robustness of the model in this case. Our method has few parameters and outperforms state of the art models in terms of Peak Signal to Noise Ratio (PSNR) and Structural SIMilarity (SSIM). In Track 2 of the PBVS 2024 Thermal Image Super-Resolution Challenge, it achieves 3rd place in the PSNR metric. Our code and pretained weights are available at https://github.com/VisionICLab/SwinFuSR.
Read more4/24/2024