On Synthetic Texture Datasets: Challenges, Creation, and Curation

0

Sign in to get full access
Overview
- Challenges in creating and curating synthetic texture datasets
- Importance of high-quality synthetic texture data for computer vision and graphics applications
- Insights into the key considerations and best practices for developing synthetic texture datasets
Plain English Explanation
Creating high-quality synthetic texture datasets can be a complex and challenging task. Texture images, which capture the visual patterns and characteristics of surfaces, are essential for many computer vision and graphics applications, such as material recognition, texture synthesis, and photorealistic rendering.
However, collecting and annotating real-world texture samples can be time-consuming and resource-intensive. Synthetic texture datasets offer a potential solution, allowing researchers and developers to generate diverse and customizable texture data.
This paper explores the key challenges, best practices, and considerations for creating and curating high-quality synthetic texture datasets. It provides insights into the technical aspects of texture representation, generation, and evaluation, as well as the broader issues of dataset design, annotation, and quality control.
By understanding the nuances and best practices for developing synthetic texture datasets, researchers and developers can create more robust and effective computer vision and graphics systems that can better handle the complexity and diversity of real-world textures.
Technical Explanation
The paper begins by providing background on texture images and their importance in computer vision and graphics applications. It then delves into the key challenges and considerations for creating synthetic texture datasets, including:
-
Texture representation: Effectively capturing and representing the intricate patterns and characteristics of textures is crucial for generating realistic synthetic textures.
-
Texture generation: Developing robust and flexible texture generation techniques that can produce a diverse range of realistic and varied synthetic textures.
-
Texture dataset curation: Ensuring the quality, diversity, and representativeness of synthetic texture datasets through careful curation and annotation processes.
The paper also discusses the evaluation and validation of synthetic texture datasets, highlighting the importance of assessing the perceptual and statistical properties of the generated textures to ensure their fidelity and usefulness for real-world applications.
Critical Analysis
The paper presents a comprehensive overview of the challenges and best practices for creating synthetic texture datasets, addressing key technical and practical considerations. However, it also acknowledges the inherent difficulties in fully replicating the complexity and diversity of real-world textures, which may limit the applicability of synthetic datasets in certain scenarios.
The paper suggests that further research is needed to develop more advanced texture generation techniques, as well as robust evaluation metrics that can better capture the nuances of texture perception and usefulness for specific applications.
Additionally, the paper does not delve into the potential biases and ethical considerations that may arise from the use of synthetic texture datasets, such as the risk of perpetuating or amplifying existing biases in the data or the potential for misuse in sensitive applications.
Conclusion
This paper provides valuable insights into the challenges and best practices for creating high-quality synthetic texture datasets. By understanding the technical and practical considerations involved, researchers and developers can work towards developing more robust and effective computer vision and graphics systems that can better handle the complexity and diversity of real-world textures.
However, the limitations of synthetic datasets and the potential for unintended consequences of their use should continue to be carefully considered and addressed through ongoing research and responsible development practices.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
New!On Synthetic Texture Datasets: Challenges, Creation, and Curation
Blaine Hoak, Patrick McDaniel
The influence of textures on machine learning models has been an ongoing investigation, specifically in texture bias/learning, interpretability, and robustness. However, due to the lack of large and diverse texture data available, the findings in these works have been limited, as more comprehensive evaluations have not been feasible. Image generative models are able to provide data creation at scale, but utilizing these models for texture synthesis has been unexplored and poses additional challenges both in creating accurate texture images and validating those images. In this work, we introduce an extensible methodology and corresponding new dataset for generating high-quality, diverse texture images capable of supporting a broad set of texture-based tasks. Our pipeline consists of: (1) developing prompts from a range of descriptors to serve as input to text-to-image models, (2) adopting and adapting Stable Diffusion pipelines to generate and filter the corresponding images, and (3) further filtering down to the highest quality images. Through this, we create the Prompted Textures Dataset (PTD), a dataset of 362,880 texture images that span 56 textures. During the process of generating images, we find that NSFW safety filters in image generation pipelines are highly sensitive to texture (and flag up to 60% of our texture images), uncovering a potential bias in these models and presenting unique challenges when working with texture data. Through both standard metrics and a human evaluation, we find that our dataset is high quality and diverse.
Read more9/17/2024

0
Infinite Texture: Text-guided High Resolution Diffusion Texture Synthesis
Yifan Wang, Aleksander Holynski, Brian L. Curless, Steven M. Seitz
We present Infinite Texture, a method for generating arbitrarily large texture images from a text prompt. Our approach fine-tunes a diffusion model on a single texture, and learns to embed that statistical distribution in the output domain of the model. We seed this fine-tuning process with a sample texture patch, which can be optionally generated from a text-to-image model like DALL-E 2. At generation time, our fine-tuned diffusion model is used through a score aggregation strategy to generate output texture images of arbitrary resolution on a single GPU. We compare synthesized textures from our method to existing work in patch-based and deep learning texture synthesis methods. We also showcase two applications of our generated textures in 3D rendering and texture transfer.
Read more5/15/2024

0
Text-Driven Diverse Facial Texture Generation via Progressive Latent-Space Refinement
Chi Wang, Junming Huang, Rong Zhang, Qi Wang, Haotian Yang, Haibin Huang, Chongyang Ma, Weiwei Xu
Automatic 3D facial texture generation has gained significant interest recently. Existing approaches may not support the traditional physically based rendering pipeline or rely on 3D data captured by Light Stage. Our key contribution is a progressive latent space refinement approach that can bootstrap from 3D Morphable Models (3DMMs)-based texture maps generated from facial images to generate high-quality and diverse PBR textures, including albedo, normal, and roughness. It starts with enhancing Generative Adversarial Networks (GANs) for text-guided and diverse texture generation. To this end, we design a self-supervised paradigm to overcome the reliance on ground truth 3D textures and train the generative model with only entangled texture maps. Besides, we foster mutual enhancement between GANs and Score Distillation Sampling (SDS). SDS boosts GANs with more generative modes, while GANs promote more efficient optimization of SDS. Furthermore, we introduce an edge-aware SDS for multi-view consistent facial structure. Experiments demonstrate that our method outperforms existing 3D texture generation methods regarding photo-realistic quality, diversity, and efficiency.
Read more4/16/2024
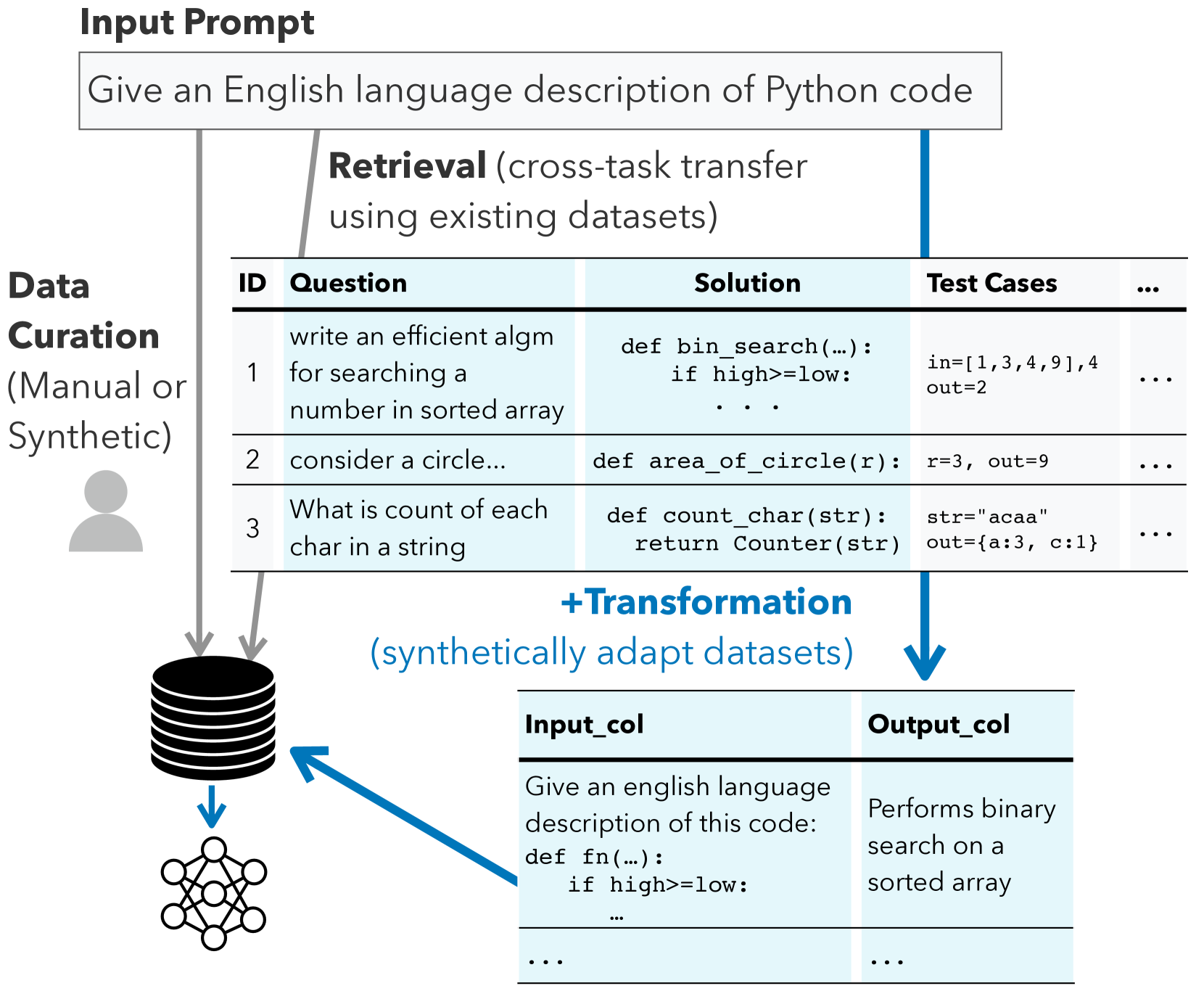
0
Better Synthetic Data by Retrieving and Transforming Existing Datasets
Saumya Gandhi, Ritu Gala, Vijay Viswanathan, Tongshuang Wu, Graham Neubig
Despite recent advances in large language models, building dependable and deployable NLP models typically requires abundant, high-quality training data. However, task-specific data is not available for many use cases, and manually curating task-specific data is labor-intensive. Recent work has studied prompt-driven synthetic data generation using large language models, but these generated datasets tend to lack complexity and diversity. To address these limitations, we introduce a method, DataTune, to make better use of existing, publicly available datasets to improve automatic dataset generation. DataTune performs dataset transformation, enabling the repurposing of publicly available datasets into a format that is directly aligned with the specific requirements of target tasks. On a diverse set of language-based tasks from the BIG-Bench benchmark, we find that finetuning language models via DataTune improves over a few-shot prompting baseline by 49% and improves over existing methods that use synthetic or retrieved training data by 34%. We find that dataset transformation significantly increases the diversity and difficulty of generated data on many tasks. We integrate DataTune into an open-source repository to make this method accessible to the community: https://github.com/neulab/prompt2model.
Read more4/30/2024