Systematic Evaluation of LLM-as-a-Judge in LLM Alignment Tasks: Explainable Metrics and Diverse Prompt Templates

0
Sign in to get full access
Overview
- This paper presents a systematic evaluation of using large language models (LLMs) as judges in LLM alignment tasks.
- It introduces explainable metrics and diverse prompt templates to assess LLMs' performance in this role.
- The authors explore the strengths and limitations of LLMs as evaluators, providing insights for future research and applications.
Plain English Explanation
The paper explores using large language models (LLMs) - advanced AI systems trained on vast amounts of text data - as judges or evaluators in tasks related to "aligning" other LLMs to behave in desired ways. The paper on "Evaluating the Evaluator" provides more background on this.
The researchers developed new ways to measure and understand how well LLMs perform in this role of judging other LLMs. They created a variety of prompts (instructions) for the LLMs to use when evaluating other AIs, and looked at different metrics to quantify the LLMs' performance.
This allowed them to assess the strengths and weaknesses of using LLMs as judges. For example, the LLMs were good at providing detailed feedback, but had trouble being fully impartial and objective. The paper provides insights that can help guide future research and applications of LLMs in this area.
Technical Explanation
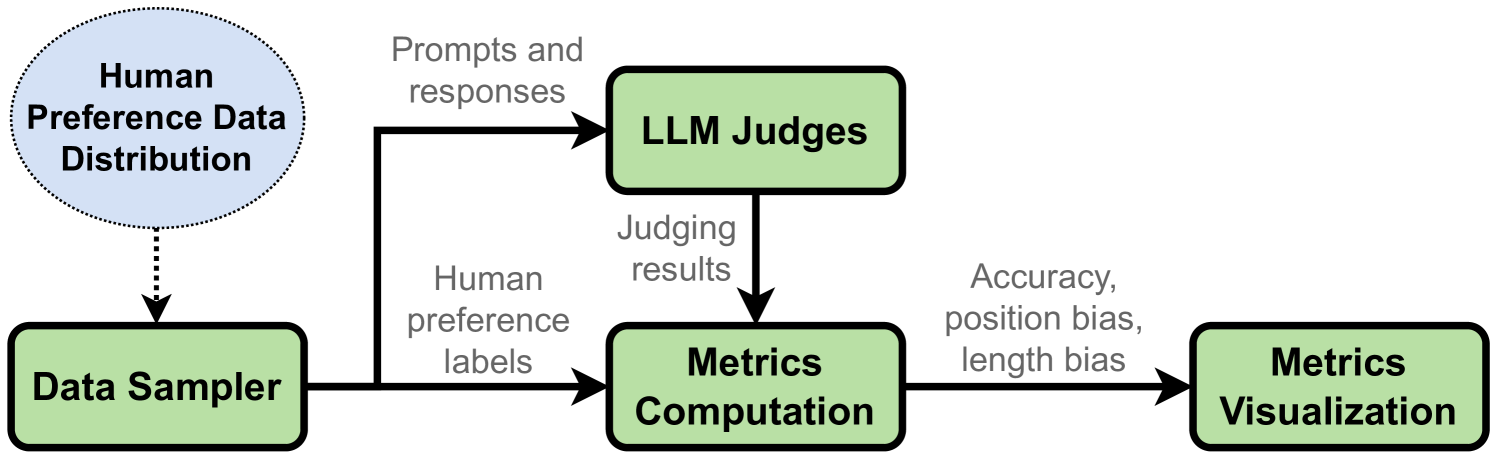
The paper introduces a systematic evaluation framework for assessing the performance of LLMs in the role of a "judge" for other LLM alignment tasks. The authors developed a set of explainable metrics and diverse prompt templates to measure various aspects of the LLMs' judgement capabilities.
The key elements of the framework include:
- Prompt templates: The researchers created a diverse set of prompts for the LLM judges to use when evaluating other LLMs. This allowed them to assess the judges' performance across different types of prompts.
- Explainable metrics: The paper introduces several metrics to quantify the LLM judges' performance, such as their ability to provide detailed and actionable feedback, their objectivity and impartiality, and their overall accuracy in assessing alignment.
- Experimental design: The authors conducted extensive experiments, using different LLM architectures as both the judges and the aligned LLMs being evaluated. This allowed them to explore how the judges' performance varies based on the specific models involved.
Through this systematic evaluation, the paper provides insights into the strengths and limitations of using LLMs as judges in alignment tasks. The findings can inform future research and applications in this area.
Critical Analysis
The paper presents a thorough and well-designed evaluation framework for assessing LLMs as judges. The use of diverse prompt templates and explainable metrics is a strength, as it allows the researchers to go beyond simple accuracy measures and gain deeper insights into the LLMs' judgement capabilities.
However, the paper does acknowledge some limitations. For example, the prompts and metrics used may not capture all relevant aspects of judgement, and the experimental setup may not fully reflect real-world deployment scenarios. Additionally, the paper does not delve into potential biases or ethical concerns that may arise from using LLMs as judges, which would be an important consideration for future research.
Overall, the paper makes a valuable contribution by providing a rigorous methodology for evaluating LLMs in this role. The insights generated can inform the design of more robust and trustworthy LLM-based judgement systems, while also highlighting areas for further research and development.
Conclusion
This paper presents a systematic evaluation of using large language models (LLMs) as judges in LLM alignment tasks. By developing explainable metrics and diverse prompt templates, the researchers were able to assess the strengths and limitations of LLMs in this role.
The findings provide valuable insights that can guide future research and applications of LLMs as judges. The paper highlights the LLMs' ability to provide detailed feedback, but also their potential challenges in maintaining objectivity and impartiality. These insights can help inform the design of more robust and trustworthy LLM-based judgement systems, which have important implications for the responsible development of advanced AI technology.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Systematic Evaluation of LLM-as-a-Judge in LLM Alignment Tasks: Explainable Metrics and Diverse Prompt Templates
Hui Wei, Shenghua He, Tian Xia, Andy Wong, Jingyang Lin, Mei Han
Alignment approaches such as RLHF and DPO are actively investigated to align large language models (LLMs) with human preferences. Commercial large language models (LLMs) like GPT-4 have been recently employed to evaluate and compare different LLM alignment approaches. These models act as surrogates for human evaluators due to their promising abilities to approximate human preferences with remarkably faster feedback and lower costs. This methodology is referred to as LLM-as-a-judge. However, concerns regarding its reliability have emerged, attributed to LLM judges' biases and inconsistent decision-making. Previous research has sought to develop robust evaluation frameworks for assessing the reliability of LLM judges and their alignment with human preferences. However, the employed evaluation metrics often lack adequate explainability and fail to address the internal inconsistency of LLMs. Additionally, existing studies inadequately explore the impact of various prompt templates when applying LLM-as-a-judge methods, which leads to potentially inconsistent comparisons between different alignment algorithms. In this work, we systematically evaluate LLM judges on alignment tasks (e.g. summarization) by defining evaluation metrics with improved theoretical interpretability and disentangling reliability metrics with LLM internal inconsistency. We develop a framework to evaluate, compare, and visualize the reliability and alignment of LLM judges to provide informative observations that help choose LLM judges for alignment tasks. Our results indicate a significant impact of prompt templates on LLM judge performance, as well as a mediocre alignment level between the tested LLM judges and human evaluators.
Read more8/26/2024

0
Judging the Judges: Evaluating Alignment and Vulnerabilities in LLMs-as-Judges
Aman Singh Thakur, Kartik Choudhary, Venkat Srinik Ramayapally, Sankaran Vaidyanathan, Dieuwke Hupkes
Offering a promising solution to the scalability challenges associated with human evaluation, the LLM-as-a-judge paradigm is rapidly gaining traction as an approach to evaluating large language models (LLMs). However, there are still many open questions about the strengths and weaknesses of this paradigm, and what potential biases it may hold. In this paper, we present a comprehensive study of the performance of various LLMs acting as judges. We leverage TriviaQA as a benchmark for assessing objective knowledge reasoning of LLMs and evaluate them alongside human annotations which we found to have a high inter-annotator agreement. Our study includes 9 judge models and 9 exam taker models -- both base and instruction-tuned. We assess the judge model's alignment across different model sizes, families, and judge prompts. Among other results, our research rediscovers the importance of using Cohen's kappa as a metric of alignment as opposed to simple percent agreement, showing that judges with high percent agreement can still assign vastly different scores. We find that both Llama-3 70B and GPT-4 Turbo have an excellent alignment with humans, but in terms of ranking exam taker models, they are outperformed by both JudgeLM-7B and the lexical judge Contains, which have up to 34 points lower human alignment. Through error analysis and various other studies, including the effects of instruction length and leniency bias, we hope to provide valuable lessons for using LLMs as judges in the future.
Read more6/19/2024

0
Evaluating the Evaluator: Measuring LLMs' Adherence to Task Evaluation Instructions
Bhuvanashree Murugadoss, Christian Poelitz, Ian Drosos, Vu Le, Nick McKenna, Carina Suzana Negreanu, Chris Parnin, Advait Sarkar
LLMs-as-a-judge is a recently popularized method which replaces human judgements in task evaluation (Zheng et al. 2024) with automatic evaluation using LLMs. Due to widespread use of RLHF (Reinforcement Learning from Human Feedback), state-of-the-art LLMs like GPT4 and Llama3 are expected to have strong alignment with human preferences when prompted for a quality judgement, such as the coherence of a text. While this seems beneficial, it is not clear whether the assessments by an LLM-as-a-judge constitute only an evaluation based on the instructions in the prompts, or reflect its preference for high-quality data similar to its fine-tune data. To investigate how much influence prompting the LLMs-as-a-judge has on the alignment of AI judgements to human judgements, we analyze prompts with increasing levels of instructions about the target quality of an evaluation, for several LLMs-as-a-judge. Further, we compare to a prompt-free method using model perplexity as a quality measure instead. We aggregate a taxonomy of quality criteria commonly used across state-of-the-art evaluations with LLMs and provide this as a rigorous benchmark of models as judges. Overall, we show that the LLMs-as-a-judge benefit only little from highly detailed instructions in prompts and that perplexity can sometimes align better with human judgements than prompting, especially on textual quality.
Read more8/19/2024

0
Human-Centered Design Recommendations for LLM-as-a-Judge
Qian Pan, Zahra Ashktorab, Michael Desmond, Martin Santillan Cooper, James Johnson, Rahul Nair, Elizabeth Daly, Werner Geyer
Traditional reference-based metrics, such as BLEU and ROUGE, are less effective for assessing outputs from Large Language Models (LLMs) that produce highly creative or superior-quality text, or in situations where reference outputs are unavailable. While human evaluation remains an option, it is costly and difficult to scale. Recent work using LLMs as evaluators (LLM-as-a-judge) is promising, but trust and reliability remain a significant concern. Integrating human input is crucial to ensure criteria used to evaluate are aligned with the human's intent, and evaluations are robust and consistent. This paper presents a user study of a design exploration called EvaluLLM, that enables users to leverage LLMs as customizable judges, promoting human involvement to balance trust and cost-saving potential with caution. Through interviews with eight domain experts, we identified the need for assistance in developing effective evaluation criteria aligning the LLM-as-a-judge with practitioners' preferences and expectations. We offer findings and design recommendations to optimize human-assisted LLM-as-judge systems.
Read more7/8/2024