Tabular Transfer Learning via Prompting LLMs

0
🔄
Sign in to get full access
Overview
- Transfer learning is a key approach to deal with the scarcity of labeled data in real-world machine learning applications.
- While transfer learning has been successful in domains like computer vision and natural language processing, it has seen less progress in tabular data tasks.
- This is because tables are inherently heterogeneous, with different columns and feature spaces, making transfer learning challenging.
- Recent advances in large language models (LLMs) suggest their in-context learning capabilities could help mitigate the label scarcity issue.
- Leveraging the ability of LLMs to process tables, this paper proposes a novel tabular transfer learning framework called Prompt to Transfer (P2T).
Plain English Explanation
In many real-world machine learning problems, it can be expensive or difficult to obtain enough labeled data to train effective models. Transfer learning is a common solution, where a model is first trained on a large dataset and then adapted to a new, smaller task.
This approach has been quite successful in areas like computer vision and natural language processing. However, transferring knowledge to tabular data tasks has proven more challenging.
The reason is that tables often contain very different types of information in each column, making it hard to find commonalities across datasets that can be leveraged for transfer learning. In contrast, images and text tend to have more inherent structure that can be better transferred.
But recent breakthroughs in large language models suggest a potential solution. These powerful AI systems can understand and process tabular data, and their ability to learn quickly from just a few examples could help address the label scarcity problem.
Inspired by this, the researchers propose a new framework called Prompt to Transfer (P2T) that uses large language models to enable more effective transfer learning for tabular datasets, even when the source and target datasets have very different formats.
Technical Explanation
The core idea behind P2T is to leverage the in-context learning capabilities of large language models to create "pseudo-demonstrations" that can be used as prompts for transfer learning.
Specifically, the P2T framework first identifies a column feature in the source dataset that is strongly correlated with a target task feature. It then uses this relationship to generate synthetic examples that are relevant to the target task, even though the source and target datasets may have very different structures.
These synthetic examples are then used as prompts to fine-tune the language model, allowing it to quickly learn patterns that are transferable to the target task, despite the data heterogeneity.
The researchers evaluate P2T on several tabular learning benchmarks and show that it outperforms previous transfer learning methods. This demonstrates the promise of using large language models to address the important, yet underexplored challenge of tabular transfer learning.
Critical Analysis
The P2T framework represents an innovative approach to a critical problem in applied machine learning. By leveraging the strengths of large language models, the researchers have found a way to overcome the inherent challenges of transferring knowledge across heterogeneous tabular datasets.
That said, the paper does note some potential limitations and areas for further research. For example, the method relies on identifying a strongly correlated feature between the source and target datasets, which may not always be possible. Additionally, the performance of P2T could be sensitive to the quality and coverage of the source dataset.
It would also be valuable to explore how P2T's performance scales with the size and complexity of the tabular datasets, as well as its robustness to noisy or incomplete data. Comparing P2T to other emerging approaches for tabular transfer learning, such as meta-learning or few-shot learning, could also provide additional insights.
Overall, the P2T framework represents an important step forward in addressing a longstanding challenge in the field of machine learning. As the authors note, the ability to effectively transfer knowledge across tabular datasets has significant implications for a wide range of real-world applications.
Conclusion
This paper introduces a novel tabular transfer learning framework called Prompt to Transfer (P2T) that leverages the capabilities of large language models to overcome the challenges of data heterogeneity in tabular datasets.
By generating synthetic "pseudo-demonstrations" based on correlations between source and target features, P2T is able to fine-tune language models in a way that enables effective transfer learning, even when the underlying data structures are quite different.
The researchers demonstrate the effectiveness of P2T on several benchmarks, highlighting its promise for addressing the critical problem of label scarcity in real-world machine learning applications that rely on tabular data. While the method has some limitations, it represents an important advance in the field and opens up new avenues for further research and development.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🔄
0
Tabular Transfer Learning via Prompting LLMs
Jaehyun Nam, Woomin Song, Seong Hyeon Park, Jihoon Tack, Sukmin Yun, Jaehyung Kim, Kyu Hwan Oh, Jinwoo Shin
Learning with a limited number of labeled data is a central problem in real-world applications of machine learning, as it is often expensive to obtain annotations. To deal with the scarcity of labeled data, transfer learning is a conventional approach; it suggests to learn a transferable knowledge by training a neural network from multiple other sources. In this paper, we investigate transfer learning of tabular tasks, which has been less studied and successful in the literature, compared to other domains, e.g., vision and language. This is because tables are inherently heterogeneous, i.e., they contain different columns and feature spaces, making transfer learning difficult. On the other hand, recent advances in natural language processing suggest that the label scarcity issue can be mitigated by utilizing in-context learning capability of large language models (LLMs). Inspired by this and the fact that LLMs can also process tables within a unified language space, we ask whether LLMs can be effective for tabular transfer learning, in particular, under the scenarios where the source and target datasets are of different format. As a positive answer, we propose a novel tabular transfer learning framework, coined Prompt to Transfer (P2T), that utilizes unlabeled (or heterogeneous) source data with LLMs. Specifically, P2T identifies a column feature in a source dataset that is strongly correlated with a target task feature to create examples relevant to the target task, thus creating pseudo-demonstrations for prompts. Experimental results demonstrate that P2T outperforms previous methods on various tabular learning benchmarks, showing good promise for the important, yet underexplored tabular transfer learning problem. Code is available at https://github.com/jaehyun513/P2T.
Read more8/22/2024
🛸
0
An Automatic Prompt Generation System for Tabular Data Tasks
Ashlesha Akella, Abhijit Manatkar, Brij Chavda, Hima Patel
Efficient processing of tabular data is important in various industries, especially when working with datasets containing a large number of columns. Large language models (LLMs) have demonstrated their ability on several tasks through carefully crafted prompts. However, creating effective prompts for tabular datasets is challenging due to the structured nature of the data and the need to manage numerous columns. This paper presents an innovative auto-prompt generation system suitable for multiple LLMs, with minimal training. It proposes two novel methods; 1) A Reinforcement Learning-based algorithm for identifying and sequencing task-relevant columns 2) Cell-level similarity-based approach for enhancing few-shot example selection. Our approach has been extensively tested across 66 datasets, demonstrating improved performance in three downstream tasks: data imputation, error detection, and entity matching using two distinct LLMs; Google flan-t5-xxl and Mixtral 8x7B.
Read more5/10/2024

0
Large Scale Transfer Learning for Tabular Data via Language Modeling
Josh Gardner, Juan C. Perdomo, Ludwig Schmidt
Tabular data -- structured, heterogeneous, spreadsheet-style data with rows and columns -- is widely used in practice across many domains. However, while recent foundation models have reduced the need for developing task-specific datasets and predictors in domains such as language modeling and computer vision, this transfer learning paradigm has not had similar impact in the tabular domain. In this work, we seek to narrow this gap and present TabuLa-8B, a language model for tabular prediction. We define a process for extracting a large, high-quality training dataset from the TabLib corpus, proposing methods for tabular data filtering and quality control. Using the resulting dataset, which comprises over 1.6B rows from 3.1M unique tables, we fine-tune a Llama 3-8B large language model (LLM) for tabular data prediction (classification and binned regression) using a novel packing and attention scheme for tabular prediction. Through evaluation across a test suite of 329 datasets, we find that TabuLa-8B has zero-shot accuracy on unseen tables that is over 15 percentage points (pp) higher than random guessing, a feat that is not possible with existing state-of-the-art tabular prediction models (e.g. XGBoost, TabPFN). In the few-shot setting (1-32 shots), without any fine-tuning on the target datasets, TabuLa-8B is 5-15 pp more accurate than XGBoost and TabPFN models that are explicitly trained on equal, or even up to 16x more data. We release our model, code, and data along with the publication of this paper.
Read more6/19/2024
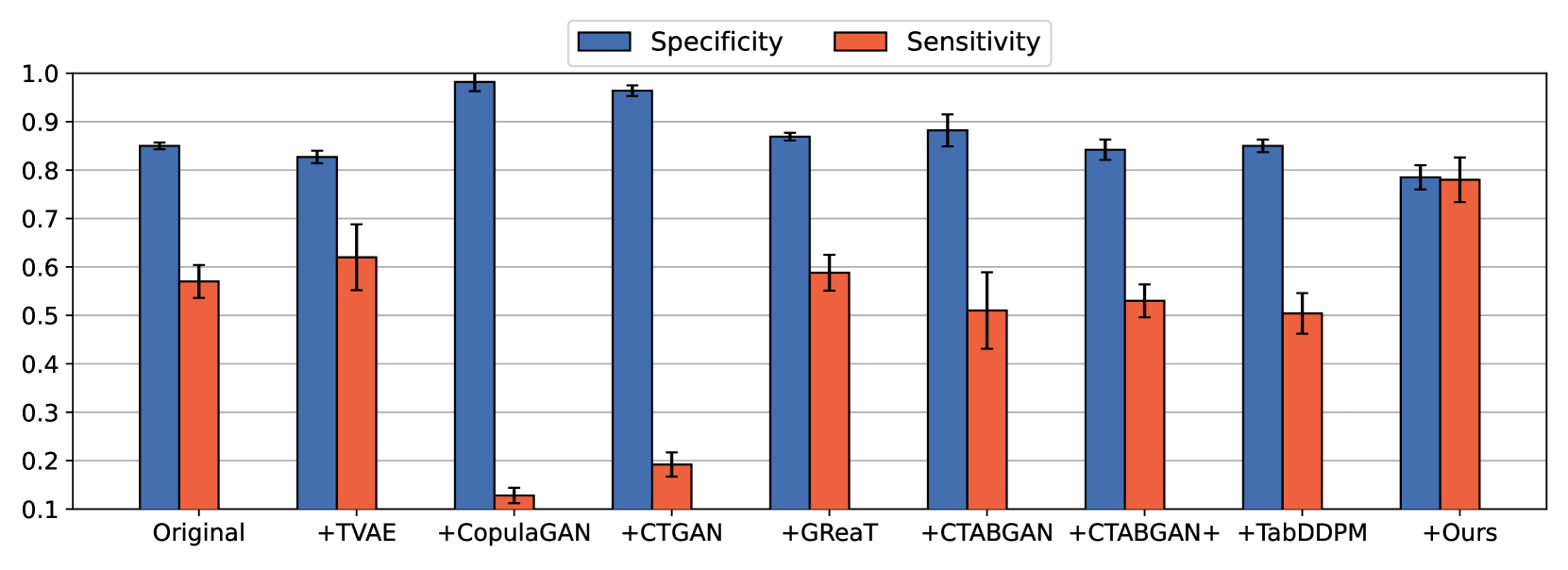
0
Group-wise Prompting for Synthetic Tabular Data Generation using Large Language Models
Jinhee Kim, Taesung Kim, Jaegul Choo
Large language models (LLMs) have demonstrated impressive in-context learning capabilities across various domains. Inspired by this, our study explores the effectiveness of LLMs in generating realistic tabular data to mitigate class imbalance. We investigate and identify key prompt design elements such as data format, class presentation, and variable mapping to optimize the generation performance. Our findings indicate that using CSV format, balancing classes, and employing unique variable mapping produces realistic and reliable data, significantly enhancing machine learning performance for minor classes in imbalanced datasets. Additionally, these approaches improve the stability and efficiency of LLM data generation. We validate our approach using six real-world datasets and a toy dataset, achieving state-of-the-art performance in classification tasks. The code is available at: https://github.com/seharanul17/synthetic-tabular-LLM
Read more5/28/2024