TabularMark: Watermarking Tabular Datasets for Machine Learning

0

Sign in to get full access
Overview
- This paper introduces TabularMark, a technique for watermarking tabular datasets used in machine learning models.
- Watermarking is a way to embed invisible markers in datasets to help identify the source or ownership of the data.
- The goal is to enable owners to track and protect their tabular data from unauthorized use or redistribution.
Plain English Explanation
Tabular datasets are collections of data organized into rows and columns, like a spreadsheet. These datasets are often used to train machine learning models, which are algorithms that learn patterns from data.
TabularMark: Watermarking Tabular Datasets for Machine Learning presents a new method called TabularMark that can add invisible "watermarks" to tabular datasets. These watermarks act like digital signatures, allowing the dataset owner to track and identify if their data is being used without permission.
Imagine you own a valuable recipe book and want to make sure no one makes copies of it. With TabularMark, you could add a hidden mark to each page that would allow you to prove the book is yours if you ever found an unauthorized copy. Similarly, TabularMark allows dataset owners to protect their data from being stolen or misused by embedding these invisible watermarks.
The paper explains how TabularMark works and shows through experiments that it can effectively watermark tabular datasets without significantly impacting the performance of machine learning models trained on the data. This could be an important tool for dataset owners to safeguard their intellectual property in the age of growing AI and data-driven technologies.
Technical Explanation
TabularMark: Watermarking Tabular Datasets for Machine Learning proposes a novel technique for watermarking tabular datasets used to train machine learning models. The key idea is to embed invisible marks into the dataset that can later be detected to identify the source or ownership of the data.
The authors design a watermarking framework that can be applied to both numerical and categorical attributes in tabular data. For numerical attributes, they use a perturbation technique that slightly modifies the values while preserving the overall statistical properties of the data. For categorical attributes, they propose a more complex encoding scheme that embeds the watermark by selectively flipping the category labels.
Through extensive experiments on various real-world datasets, the researchers demonstrate that TabularMark can effectively watermark tabular data without significantly degrading the performance of machine learning models trained on the marked datasets. They also show that the watermarks are resilient to common data augmentation and adversarial attacks aimed at removing or distorting the marks.
The paper also discusses potential applications of TabularMark, such as enabling dataset owners to track unauthorized usage of their data and providing a way to prove data ownership in legal disputes. Overall, TabularMark represents an important advance in the field of dataset watermarking, which is crucial for protecting intellectual property in the era of widespread data sharing and AI model development.
Critical Analysis
The TabularMark paper presents a well-designed and thorough approach to watermarking tabular datasets. The authors have carefully considered the unique challenges of watermarking structured data and have proposed effective solutions.
One potential limitation is that the watermarking process may still introduce some distortion to the data, even if the authors claim it is minimal. This could be a concern for certain applications where data integrity is paramount, such as in medical or financial domains. Further research may be needed to quantify the trade-offs between watermark robustness and data fidelity.
Additionally, the paper does not explore the potential impacts of TabularMark on downstream machine learning tasks beyond the standard evaluation metrics. It would be valuable to investigate how the watermarking process affects the fairness, interpretability, or generalization of models trained on the marked data.
Reliable Model Watermarking: Defending Against Theft Without Weakening Performance and Proving Membership in LLM Pretraining Data via Data-Centric Watermarks are related works that explore watermarking techniques for other types of AI assets, such as machine learning models and language models. Comparing and contrasting the approaches taken in these papers could provide additional insights and identify potential synergies.
Overall, the TabularMark paper represents an important contribution to the growing field of dataset watermarking, which is crucial for protecting intellectual property in the age of AI and data-driven technologies.
Conclusion
TabularMark: Watermarking Tabular Datasets for Machine Learning presents a novel technique for embedding invisible watermarks into tabular datasets used to train machine learning models. This approach allows dataset owners to track and identify the use of their data, helping to protect their intellectual property in an era of widespread data sharing and AI development.
The key strengths of TabularMark are its ability to effectively watermark both numerical and categorical data without significantly degrading machine learning model performance, and its resilience to common data augmentation and adversarial attacks. While there are some potential limitations to consider, such as the impact on data integrity and downstream tasks, TabularMark represents an important step forward in the field of dataset watermarking.
As the use of AI and machine learning continues to grow, tools like TabularMark will become increasingly crucial for enabling dataset owners to safeguard their valuable data assets. The principles and techniques introduced in this paper could also inspire further research into watermarking approaches for other types of AI-related intellectual property, such as machine learning models and language models.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
TabularMark: Watermarking Tabular Datasets for Machine Learning
Yihao Zheng, Haocheng Xia, Junyuan Pang, Jinfei Liu, Kui Ren, Lingyang Chu, Yang Cao, Li Xiong
Watermarking is broadly utilized to protect ownership of shared data while preserving data utility. However, existing watermarking methods for tabular datasets fall short on the desired properties (detectability, non-intrusiveness, and robustness) and only preserve data utility from the perspective of data statistics, ignoring the performance of downstream ML models trained on the datasets. Can we watermark tabular datasets without significantly compromising their utility for training ML models while preventing attackers from training usable ML models on attacked datasets? In this paper, we propose a hypothesis testing-based watermarking scheme, TabularMark. Data noise partitioning is utilized for data perturbation during embedding, which is adaptable for numerical and categorical attributes while preserving the data utility. For detection, a custom-threshold one proportion z-test is employed, which can reliably determine the presence of the watermark. Experiments on real-world and synthetic datasets demonstrate the superiority of TabularMark in detectability, non-intrusiveness, and robustness.
Read more6/24/2024

0
Watermarking Generative Tabular Data
Hengzhi He, Peiyu Yu, Junpeng Ren, Ying Nian Wu, Guang Cheng
In this paper, we introduce a simple yet effective tabular data watermarking mechanism with statistical guarantees. We show theoretically that the proposed watermark can be effectively detected, while faithfully preserving the data fidelity, and also demonstrates appealing robustness against additive noise attack. The general idea is to achieve the watermarking through a strategic embedding based on simple data binning. Specifically, it divides the feature's value range into finely segmented intervals and embeds watermarks into selected ``green list intervals. To detect the watermarks, we develop a principled statistical hypothesis-testing framework with minimal assumptions: it remains valid as long as the underlying data distribution has a continuous density function. The watermarking efficacy is demonstrated through rigorous theoretical analysis and empirical validation, highlighting its utility in enhancing the security of synthetic and real-world datasets.
Read more5/28/2024
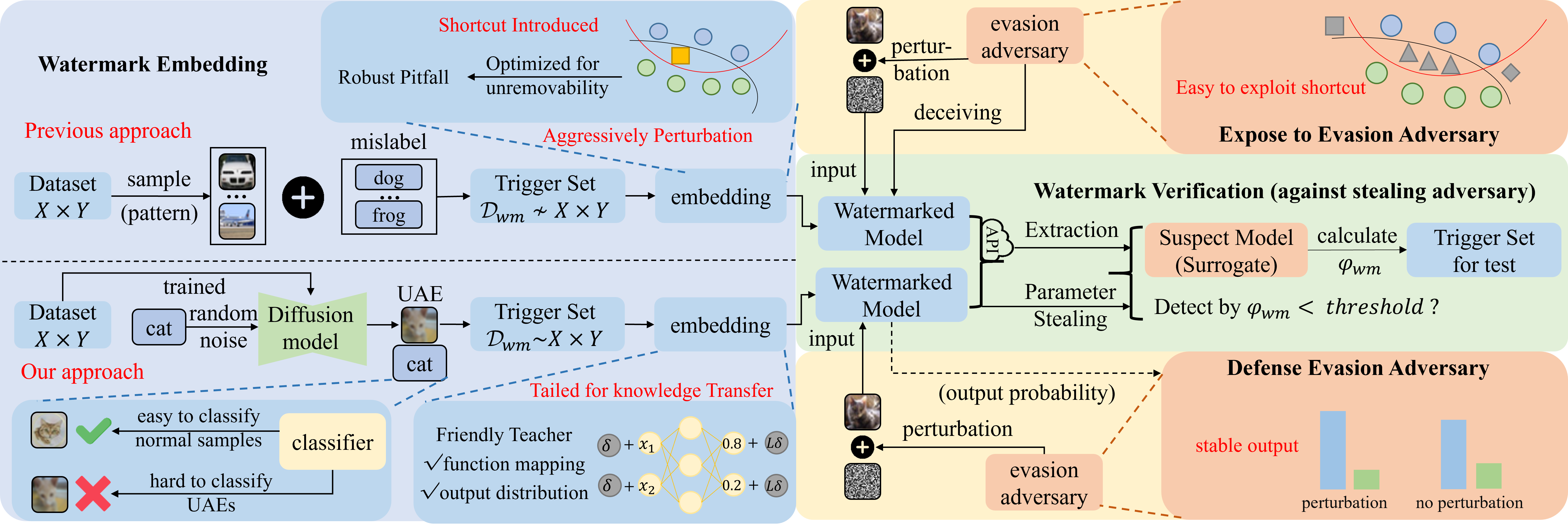
0
Reliable Model Watermarking: Defending Against Theft without Compromising on Evasion
Hongyu Zhu, Sichu Liang, Wentao Hu, Fangqi Li, Ju Jia, Shilin Wang
With the rise of Machine Learning as a Service (MLaaS) platforms,safeguarding the intellectual property of deep learning models is becoming paramount. Among various protective measures, trigger set watermarking has emerged as a flexible and effective strategy for preventing unauthorized model distribution. However, this paper identifies an inherent flaw in the current paradigm of trigger set watermarking: evasion adversaries can readily exploit the shortcuts created by models memorizing watermark samples that deviate from the main task distribution, significantly impairing their generalization in adversarial settings. To counteract this, we leverage diffusion models to synthesize unrestricted adversarial examples as trigger sets. By learning the model to accurately recognize them, unique watermark behaviors are promoted through knowledge injection rather than error memorization, thus avoiding exploitable shortcuts. Furthermore, we uncover that the resistance of current trigger set watermarking against removal attacks primarily relies on significantly damaging the decision boundaries during embedding, intertwining unremovability with adverse impacts. By optimizing the knowledge transfer properties of protected models, our approach conveys watermark behaviors to extraction surrogates without aggressively decision boundary perturbation. Experimental results on CIFAR-10/100 and Imagenette datasets demonstrate the effectiveness of our method, showing not only improved robustness against evasion adversaries but also superior resistance to watermark removal attacks compared to state-of-the-art solutions.
Read more4/23/2024

0
Proving membership in LLM pretraining data via data watermarks
Johnny Tian-Zheng Wei, Ryan Yixiang Wang, Robin Jia
Detecting whether copyright holders' works were used in LLM pretraining is poised to be an important problem. This work proposes using data watermarks to enable principled detection with only black-box model access, provided that the rightholder contributed multiple training documents and watermarked them before public release. By applying a randomly sampled data watermark, detection can be framed as hypothesis testing, which provides guarantees on the false detection rate. We study two watermarks: one that inserts random sequences, and another that randomly substitutes characters with Unicode lookalikes. We first show how three aspects of watermark design -- watermark length, number of duplications, and interference -- affect the power of the hypothesis test. Next, we study how a watermark's detection strength changes under model and dataset scaling: while increasing the dataset size decreases the strength of the watermark, watermarks remain strong if the model size also increases. Finally, we view SHA hashes as natural watermarks and show that we can robustly detect hashes from BLOOM-176B's training data, as long as they occurred at least 90 times. Together, our results point towards a promising future for data watermarks in real world use.
Read more8/20/2024