TAGCOS: Task-agnostic Gradient Clustered Coreset Selection for Instruction Tuning Data

0

Sign in to get full access
Overview
- TAGCOS is a method for selecting a representative subset (coreset) of data for instruction tuning of large language models
- It uses task-agnostic clustering based on gradient information to identify the most informative data points
- This can significantly reduce the amount of data required for effective fine-tuning, leading to faster and more efficient training
Plain English Explanation
TAGCOS is a technique used to select a smaller, more representative subset of data for fine-tuning large language models on specific tasks or instructions. Large language models like GPT-3 are often trained on massive datasets, but for a particular application, only a portion of that data may be relevant or informative.
TAGCOS: Task-agnostic Gradient Clustered Coreset Selection for Instruction Tuning Data aims to identify the most important data points that should be used for fine-tuning. It does this by looking at the gradients, or the rate of change, in the model's performance as it trains on each data point. Data points with larger gradients are considered more informative and are clustered together. This allows TAGCOS to select a smaller, more representative "coreset" of the data for fine-tuning, rather than using the entire original dataset.
By using this task-agnostic coreset selection approach, TAGCOS can significantly reduce the amount of data required for effective fine-tuning. This leads to faster and more efficient training, as the model only needs to learn from the most informative data points. This can be especially useful when working with very large language models that require a lot of computational resources to train on large datasets.
Technical Explanation
TAGCOS: Task-agnostic Gradient Clustered Coreset Selection for Instruction Tuning Data presents a method for selecting a representative subset of data, or a "coreset," for instruction tuning of large language models. The key idea is to use task-agnostic gradient information to identify the most informative data points, and then cluster these points to create the coreset.
The authors first compute the gradients of the model's performance with respect to each input data point. They then use a gradient-based clustering algorithm to group the data points with similar gradients, forming clusters that represent the most informative regions of the input space. Finally, they select a subset of data points from each cluster to create the final coreset, ensuring that the coreset is representative of the full dataset.
The authors evaluate TAGCOS on several instruction tuning tasks, including text generation, question answering, and natural language inference. They show that TAGCOS can achieve comparable performance to using the full dataset while only requiring a fraction of the data, leading to faster and more efficient fine-tuning.
Critical Analysis
The TAGCOS: Task-agnostic Gradient Clustered Coreset Selection for Instruction Tuning Data paper presents a novel and promising approach for data selection in the context of instruction tuning. By leveraging gradient information in a task-agnostic manner, TAGCOS can effectively identify the most informative data points for fine-tuning, which is a significant advantage over more traditional data selection methods.
One potential limitation of the work is that the authors only evaluate TAGCOS on a limited set of instruction tuning tasks. It would be interesting to see how the method performs on a wider range of tasks and datasets, including those with different characteristics or domain-specific challenges. Additionally, the authors do not provide a detailed analysis of the computational cost or scalability of the TAGCOS method, which could be an important consideration when working with very large language models and datasets.
Despite these minor concerns, the TAGCOS: Task-agnostic Gradient Clustered Coreset Selection for Instruction Tuning Data paper makes a valuable contribution to the field of data selection for instruction tuning. The authors have demonstrated that TAGCOS can significantly reduce the amount of data required for effective fine-tuning, which has important implications for the efficient and sustainable development of large language models.
Conclusion
TAGCOS: Task-agnostic Gradient Clustered Coreset Selection for Instruction Tuning Data introduces a novel method for selecting a representative subset of data, or a "coreset," for instruction tuning of large language models. By using a task-agnostic, gradient-based clustering approach, TAGCOS can identify the most informative data points and significantly reduce the amount of data required for effective fine-tuning.
This work has important implications for the efficient and sustainable development of large language models, as it can lead to faster and more resource-efficient training. As the size and complexity of these models continue to grow, techniques like TAGCOS will become increasingly crucial for ensuring that the training process is both effective and environmentally responsible.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
TAGCOS: Task-agnostic Gradient Clustered Coreset Selection for Instruction Tuning Data
Jipeng Zhang, Yaxuan Qin, Renjie Pi, Weizhong Zhang, Rui Pan, Tong Zhang
Instruction tuning has achieved unprecedented success in NLP, turning large language models into versatile chatbots. However, the increasing variety and volume of instruction datasets demand significant computational resources. To address this, it is essential to extract a small and highly informative subset (i.e., Coreset) that achieves comparable performance to the full dataset. Achieving this goal poses non-trivial challenges: 1) data selection requires accurate data representations that reflect the training samples' quality, 2) considering the diverse nature of instruction datasets, and 3) ensuring the efficiency of the coreset selection algorithm for large models. To address these challenges, we propose Task-Agnostic Gradient Clustered COreset Selection (TAGCOS). Specifically, we leverage sample gradients as the data representations, perform clustering to group similar data, and apply an efficient greedy algorithm for coreset selection. Experimental results show that our algorithm, selecting only 5% of the data, surpasses other unsupervised methods and achieves performance close to that of the full dataset.
Read more7/23/2024

0
The Power of Few: Accelerating and Enhancing Data Reweighting with Coreset Selection
Mohammad Jafari, Yimeng Zhang, Yihua Zhang, Sijia Liu
As machine learning tasks continue to evolve, the trend has been to gather larger datasets and train increasingly larger models. While this has led to advancements in accuracy, it has also escalated computational costs to unsustainable levels. Addressing this, our work aims to strike a delicate balance between computational efficiency and model accuracy, a persisting challenge in the field. We introduce a novel method that employs core subset selection for reweighting, effectively optimizing both computational time and model performance. By focusing on a strategically selected coreset, our approach offers a robust representation, as it efficiently minimizes the influence of outliers. The re-calibrated weights are then mapped back to and propagated across the entire dataset. Our experimental results substantiate the effectiveness of this approach, underscoring its potential as a scalable and precise solution for model training.
Read more6/3/2024
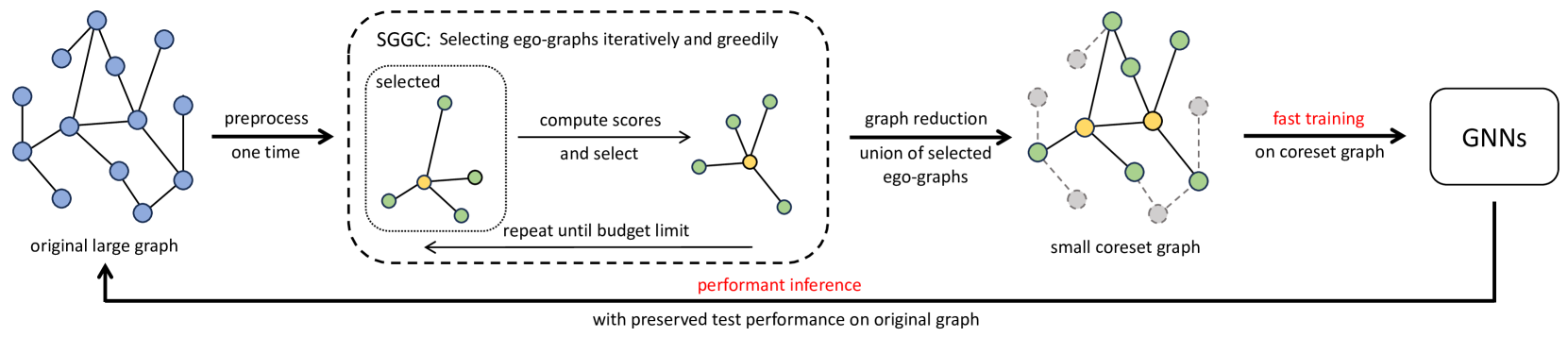
0
Spectral Greedy Coresets for Graph Neural Networks
Mucong Ding, Yinhan He, Jundong Li, Furong Huang
The ubiquity of large-scale graphs in node-classification tasks significantly hinders the real-world applications of Graph Neural Networks (GNNs). Node sampling, graph coarsening, and dataset condensation are effective strategies for enhancing data efficiency. However, owing to the interdependence of graph nodes, coreset selection, which selects subsets of the data examples, has not been successfully applied to speed up GNN training on large graphs, warranting special treatment. This paper studies graph coresets for GNNs and avoids the interdependence issue by selecting ego-graphs (i.e., neighborhood subgraphs around a node) based on their spectral embeddings. We decompose the coreset selection problem for GNNs into two phases: a coarse selection of widely spread ego graphs and a refined selection to diversify their topologies. We design a greedy algorithm that approximately optimizes both objectives. Our spectral greedy graph coreset (SGGC) scales to graphs with millions of nodes, obviates the need for model pre-training, and applies to low-homophily graphs. Extensive experiments on ten datasets demonstrate that SGGC outperforms other coreset methods by a wide margin, generalizes well across GNN architectures, and is much faster than graph condensation.
Read more5/28/2024

0
LESS: Selecting Influential Data for Targeted Instruction Tuning
Mengzhou Xia, Sadhika Malladi, Suchin Gururangan, Sanjeev Arora, Danqi Chen
Instruction tuning has unlocked powerful capabilities in large language models (LLMs), effectively using combined datasets to develop generalpurpose chatbots. However, real-world applications often require a specialized suite of skills (e.g., reasoning). The challenge lies in identifying the most relevant data from these extensive datasets to effectively develop specific capabilities, a setting we frame as targeted instruction tuning. We propose LESS, an optimizer-aware and practically efficient algorithm to effectively estimate data influences and perform Low-rank gradiEnt Similarity Search for instruction data selection. Crucially, LESS adapts existing influence formulations to work with the Adam optimizer and variable-length instruction data. LESS first constructs a highly reusable and transferable gradient datastore with low-dimensional gradient features and then selects examples based on their similarity to few-shot examples embodying a specific capability. Experiments show that training on a LESS-selected 5% of the data can often outperform training on the full dataset across diverse downstream tasks. Furthermore, the selected data is highly transferable: smaller models can be leveraged to select useful data for larger models and models from different families. Our qualitative analysis shows that our method goes beyond surface form cues to identify data that exemplifies the necessary reasoning skills for the intended downstream application.
Read more6/14/2024