Taming Stable Diffusion for Text to 360{deg} Panorama Image Generation

0
Sign in to get full access
Overview
- This paper presents a method for generating 360° panoramic images from text prompts using a modified version of the Stable Diffusion model.
- The proposed approach, called DreamScene360, aims to overcome the limitations of existing text-to-image models in generating visually coherent and realistic panoramic content.
- The authors introduce several key innovations, including a custom network architecture, training pipeline, and inference technique to enable high-quality 360° panorama generation.
Plain English Explanation
The research paper describes a way to generate 360-degree panoramic images based on text descriptions, using an artificial intelligence (AI) model called Stable Diffusion. Current text-to-image AI models have difficulty creating visually coherent and realistic panoramic content, so the researchers developed a new approach called DreamScene360 to address this challenge.
DreamScene360 modifies the Stable Diffusion model with a custom network architecture, training process, and inference technique. This allows the AI to understand how to effectively "stitch together" different visual elements into a cohesive 360-degree panoramic image that matches the given text prompt. For example, if you asked the AI to generate a "serene mountain landscape at sunset," DreamScene360 would be able to create a panoramic image that captures that scene realistically from all angles.
The key innovations in this research enable the AI to generate higher-quality 360-degree panoramic images compared to previous text-to-image models. This could have important applications in areas like virtual tourism, immersive media, and 3D content creation, where being able to generate realistic panoramic scenes from text is valuable.
Technical Explanation
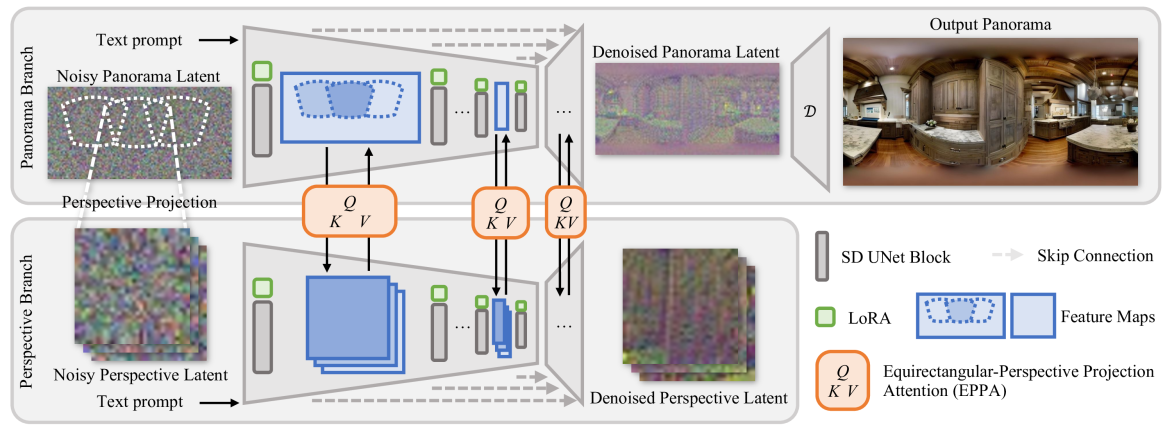
The paper introduces the DreamScene360 model, which builds upon the Stable Diffusion architecture [<a href="https://aimodels.fyi/papers/arxiv/ranni-taming-text-to-image-diffusion-accurate">1</a>] to enable text-to-360° panorama image generation. The authors make several key contributions:
-
Custom Network Architecture: DreamScene360 uses a modified U-Net [<a href="https://aimodels.fyi/papers/arxiv/coarse-to-fine-latent-diffusion-pose-guided">2</a>] backbone with additional components to handle the 360° panorama output. This includes a "panorama encoder" that encodes the 360° context and a "panorama decoder" that generates the final panoramic image.
-
Training Pipeline: The model is trained on a large dataset of 360° panorama images and their associated text captions. The training process includes techniques like multi-scale training and self-attention to improve the model's ability to capture long-range dependencies in the panoramic output.
-
Inference Technique: During inference, DreamScene360 uses a custom sampling procedure that leverages the panorama encoder to generate the 360° panoramic image in an efficient and coherent manner, rather than naively stitching together multiple 2D outputs.
The authors evaluate DreamScene360 on several benchmarks and show that it outperforms previous text-to-image models in generating high-quality, visually coherent 360° panoramic images that align with the given text prompts. This represents an important step forward in the field of text-to-3D content generation, with potential applications in virtual reality, augmented reality, and immersive media experiences.
Critical Analysis
The DreamScene360 paper presents a compelling approach to addressing the challenges of text-to-360° panorama generation, but there are a few potential limitations and areas for further research:
-
Dataset and Bias: The authors acknowledge that their training dataset may have inherent biases, which could lead to the model generating panoramic images that reflect those biases. Further research is needed to understand and mitigate potential biases in the data and model.
-
Computational Complexity: The custom architecture and inference technique introduced in DreamScene360 may have increased computational requirements compared to simpler text-to-image models. The trade-offs between model complexity, inference speed, and output quality should be explored in more depth.
-
Generalization to Other 3D Formats: While the paper focuses on 360° panoramic images, it would be interesting to see if the key innovations in DreamScene360 could be extended to other 3D content formats, such as [<a href="https://aimodels.fyi/papers/arxiv/dreamscene360-unconstrained-text-to-3d-scene-generation">3D scenes</a>] or [<a href="https://aimodels.fyi/papers/arxiv/diffusiondollar2dollar-dynamic-3d-content-generation-via-score">dynamic 3D content</a>].
Overall, the DreamScene360 paper represents an important advancement in the field of text-to-3D content generation, and the authors' approach could have a significant impact on the development of more immersive and realistic virtual experiences.
Conclusion
The DreamScene360 model presented in this paper addresses a key challenge in text-to-image generation by enabling the creation of high-quality, visually coherent 360° panoramic images from text prompts. The authors' innovations in network architecture, training pipeline, and inference technique allow the model to overcome the limitations of previous approaches and generate panoramic content that aligns well with the given text descriptions.
This research could have important implications for various applications, such as virtual tourism, immersive media, and 3D content creation, where the ability to generate realistic 360-degree scenes from text is highly valuable. While the paper identifies some potential limitations and areas for further exploration, the DreamScene360 model represents a significant step forward in the field of text-to-3D content generation.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Taming Stable Diffusion for Text to 360{deg} Panorama Image Generation
Cheng Zhang, Qianyi Wu, Camilo Cruz Gambardella, Xiaoshui Huang, Dinh Phung, Wanli Ouyang, Jianfei Cai
Generative models, e.g., Stable Diffusion, have enabled the creation of photorealistic images from text prompts. Yet, the generation of 360-degree panorama images from text remains a challenge, particularly due to the dearth of paired text-panorama data and the domain gap between panorama and perspective images. In this paper, we introduce a novel dual-branch diffusion model named PanFusion to generate a 360-degree image from a text prompt. We leverage the stable diffusion model as one branch to provide prior knowledge in natural image generation and register it to another panorama branch for holistic image generation. We propose a unique cross-attention mechanism with projection awareness to minimize distortion during the collaborative denoising process. Our experiments validate that PanFusion surpasses existing methods and, thanks to its dual-branch structure, can integrate additional constraints like room layout for customized panorama outputs. Code is available at https://chengzhag.github.io/publication/panfusion.
Read more4/12/2024
0
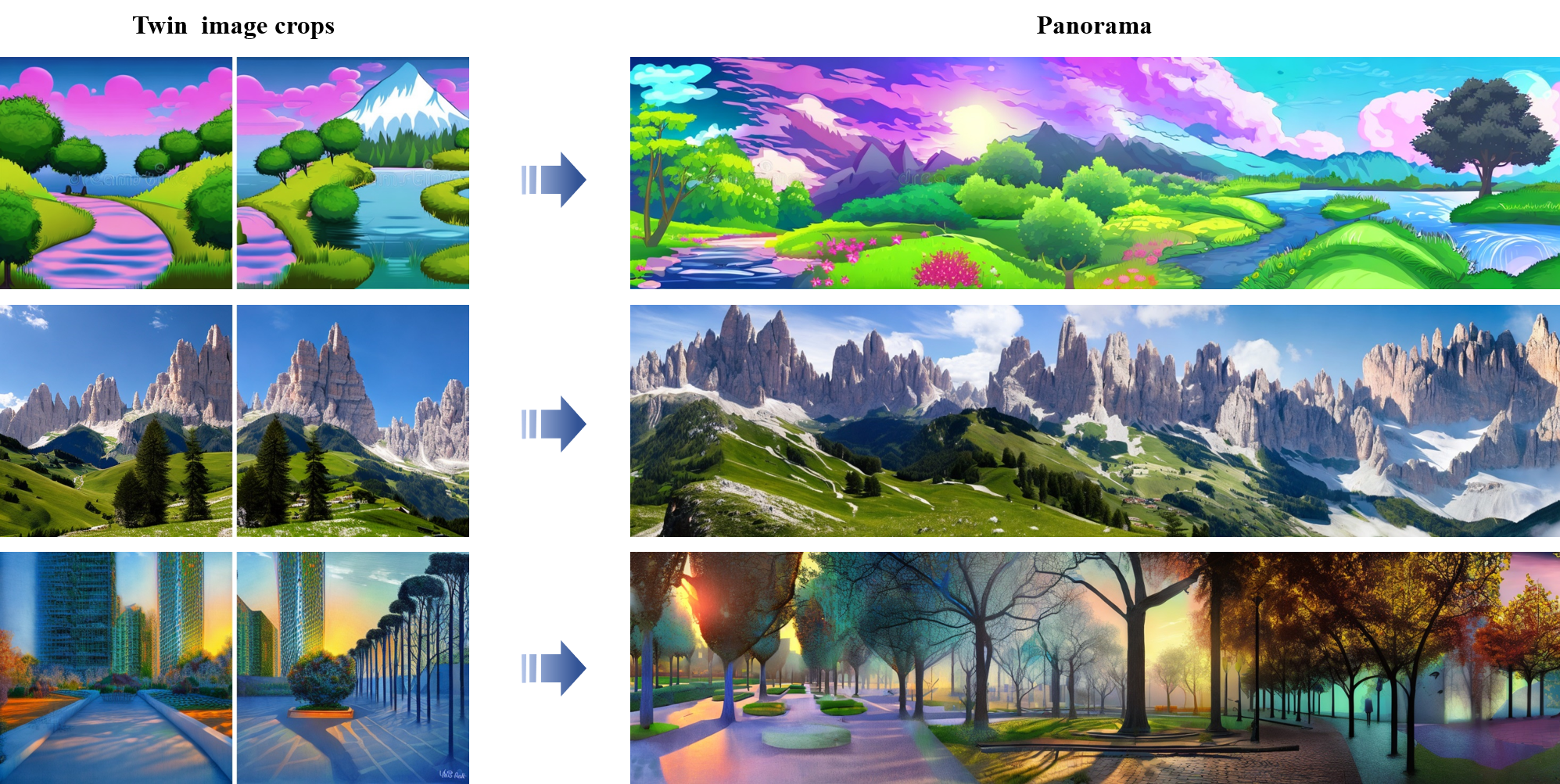
TwinDiffusion: Enhancing Coherence and Efficiency in Panoramic Image Generation with Diffusion Models
Teng Zhou, Yongchuan Tang
Diffusion models have emerged as effective tools for generating diverse and high-quality content. However, their capability in high-resolution image generation, particularly for panoramic images, still faces challenges such as visible seams and incoherent transitions. In this paper, we propose TwinDiffusion, an optimized framework designed to address these challenges through two key innovations: the Crop Fusion for quality enhancement and the Cross Sampling for efficiency optimization. We introduce a training-free optimizing stage to refine the similarity of adjacent image areas, as well as an interleaving sampling strategy to yield dynamic patches during the cropping process. A comprehensive evaluation is conducted to compare TwinDiffusion with the prior works, considering factors including coherence, fidelity, compatibility, and efficiency. The results demonstrate the superior performance of our approach in generating seamless and coherent panoramas, setting a new standard in quality and efficiency for panoramic image generation.
Read more7/9/2024

0
360DVD: Controllable Panorama Video Generation with 360-Degree Video Diffusion Model
Qian Wang, Weiqi Li, Chong Mou, Xinhua Cheng, Jian Zhang
Panorama video recently attracts more interest in both study and application, courtesy of its immersive experience. Due to the expensive cost of capturing 360-degree panoramic videos, generating desirable panorama videos by prompts is urgently required. Lately, the emerging text-to-video (T2V) diffusion methods demonstrate notable effectiveness in standard video generation. However, due to the significant gap in content and motion patterns between panoramic and standard videos, these methods encounter challenges in yielding satisfactory 360-degree panoramic videos. In this paper, we propose a pipeline named 360-Degree Video Diffusion model (360DVD) for generating 360-degree panoramic videos based on the given prompts and motion conditions. Specifically, we introduce a lightweight 360-Adapter accompanied by 360 Enhancement Techniques to transform pre-trained T2V models for panorama video generation. We further propose a new panorama dataset named WEB360 consisting of panoramic video-text pairs for training 360DVD, addressing the absence of captioned panoramic video datasets. Extensive experiments demonstrate the superiority and effectiveness of 360DVD for panorama video generation. Our project page is at https://akaneqwq.github.io/360DVD/.
Read more5/13/2024

0
360PanT: Training-Free Text-Driven 360-Degree Panorama-to-Panorama Translation
Hai Wang, Jing-Hao Xue
Preserving boundary continuity in the translation of 360-degree panoramas remains a significant challenge for existing text-driven image-to-image translation methods. These methods often produce visually jarring discontinuities at the translated panorama's boundaries, disrupting the immersive experience. To address this issue, we propose 360PanT, a training-free approach to text-based 360-degree panorama-to-panorama translation with boundary continuity. Our 360PanT achieves seamless translations through two key components: boundary continuity encoding and seamless tiling translation with spatial control. Firstly, the boundary continuity encoding embeds critical boundary continuity information of the input 360-degree panorama into the noisy latent representation by constructing an extended input image. Secondly, leveraging this embedded noisy latent representation and guided by a target prompt, the seamless tiling translation with spatial control enables the generation of a translated image with identical left and right halves while adhering to the extended input's structure and semantic layout. This process ensures a final translated 360-degree panorama with seamless boundary continuity. Experimental results on both real-world and synthesized datasets demonstrate the effectiveness of our 360PanT in translating 360-degree panoramas. Code is available at href{https://github.com/littlewhitesea/360PanT}{https://github.com/littlewhitesea/360PanT}.
Read more9/16/2024