TaskCLIP: Extend Large Vision-Language Model for Task Oriented Object Detection

0

Sign in to get full access
Overview
- Bullet point summary of the paper's key ideas:
- Extends large vision-language models like CLIP for task-oriented object detection
- Allows tailoring object detection to specific tasks by fine-tuning on task-specific data
- Shows improved performance on task-oriented object detection benchmarks
Plain English Explanation
The paper introduces TaskCLIP, a method for extending large vision-language models like CLIP to perform task-oriented object detection.
Instead of just detecting general objects in an image, TaskCLIP allows the model to be tailored for specific tasks or scenarios. This is done by fine-tuning the model on task-specific data, which teaches it to focus on the objects and attributes that are most relevant for that particular task.
The paper shows that TaskCLIP achieves better performance on task-oriented object detection benchmarks compared to standard object detection approaches. This suggests it could be a useful tool for applications where the goal is to detect objects in service of a specific task, rather than just general object recognition.
Technical Explanation
The key idea behind TaskCLIP is to leverage the powerful representation learning capabilities of large vision-language models like CLIP, and fine-tune them for task-oriented object detection.
The authors start with a pre-trained CLIP model, which has already learned rich visual and language representations by being trained on a large corpus of image-text pairs. They then fine-tune this model on task-specific datasets, using the text prompts to guide the model towards detecting objects that are relevant for the given task.
The fine-tuning process involves several key steps:
- Defining task-specific text prompts that describe the objects and attributes of interest for the target task.
- Collecting a dataset of images annotated with bounding boxes for the relevant objects.
- Fine-tuning the CLIP model to predict these task-specific object detections, using the text prompts as guidance.
Through this fine-tuning process, the model learns to focus on the most salient objects and visual features for the target task, rather than just general object recognition.
The authors evaluate TaskCLIP on several task-oriented object detection benchmarks, and show that it outperforms standard object detection approaches that are not tailored to the specific task. This demonstrates the benefits of using large vision-language models as a foundation and fine-tuning them for task-specific needs.
Critical Analysis
The paper presents a compelling approach for extending powerful vision-language models like CLIP to tackle task-oriented object detection. By fine-tuning on task-specific data and prompts, TaskCLIP is able to hone in on the most relevant objects and attributes for a given application.
However, the authors acknowledge some limitations of their work. First, the fine-tuning process requires annotated task-specific datasets, which may not always be available. Developing methods to leverage weaker forms of supervision could expand the applicability of TaskCLIP.
Additionally, the paper focuses on a limited set of tasks and benchmarks. Further research is needed to understand how well TaskCLIP generalizes to a wider range of tasks and real-world scenarios. Exploring the model's robustness and generalization capabilities would also be valuable.
Finally, the authors do not deeply investigate the internal workings of TaskCLIP or provide much insight into why the fine-tuning approach is so effective. A more thorough analysis of the model's learned representations and decision-making process could lead to a better understanding of its strengths and limitations.
Overall, TaskCLIP represents an important step forward in adapting powerful vision-language models for more targeted, task-oriented applications. Addressing the identified limitations could further strengthen this line of research and unlock new possibilities for task-oriented object detection.
Conclusion
The TaskCLIP paper introduces a novel approach for extending large vision-language models like CLIP to perform task-oriented object detection. By fine-tuning on task-specific data and prompts, the model is able to focus on the most relevant objects and visual features for a given application, leading to improved performance on task-oriented benchmarks.
This work highlights the potential of leveraging powerful pre-trained models as a foundation and tailoring them to specific needs through fine-tuning. As the capabilities of vision-language models continue to advance, techniques like TaskCLIP could enable a wide range of task-oriented applications that require more nuanced and contextual object detection.
While the paper identifies some limitations that warrant further research, the overall approach represents an important step forward in adapting large-scale AI models to tackle real-world challenges in a more targeted and effective manner.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
TaskCLIP: Extend Large Vision-Language Model for Task Oriented Object Detection
Hanning Chen, Wenjun Huang, Yang Ni, Sanggeon Yun, Yezi Liu, Fei Wen, Alvaro Velasquez, Hugo Latapie, Mohsen Imani
Task-oriented object detection aims to find objects suitable for accomplishing specific tasks. As a challenging task, it requires simultaneous visual data processing and reasoning under ambiguous semantics. Recent solutions are mainly all-in-one models. However, the object detection backbones are pre-trained without text supervision. Thus, to incorporate task requirements, their intricate models undergo extensive learning on a highly imbalanced and scarce dataset, resulting in capped performance, laborious training, and poor generalizability. In contrast, we propose TaskCLIP, a more natural two-stage design composed of general object detection and task-guided object selection. Particularly for the latter, we resort to the recently successful large Vision-Language Models (VLMs) as our backbone, which provides rich semantic knowledge and a uniform embedding space for images and texts. Nevertheless, the naive application of VLMs leads to sub-optimal quality, due to the misalignment between embeddings of object images and their visual attributes, which are mainly adjective phrases. To this end, we design a transformer-based aligner after the pre-trained VLMs to re-calibrate both embeddings. Finally, we employ a trainable score function to post-process the VLM matching results for object selection. Experimental results demonstrate that our TaskCLIP outperforms the state-of-the-art DETR-based model TOIST by 3.5% and only requires a single NVIDIA RTX 4090 for both training and inference.
Read more9/9/2024
0
Raising the Bar of AI-generated Image Detection with CLIP
Davide Cozzolino, Giovanni Poggi, Riccardo Corvi, Matthias Nie{ss}ner, Luisa Verdoliva
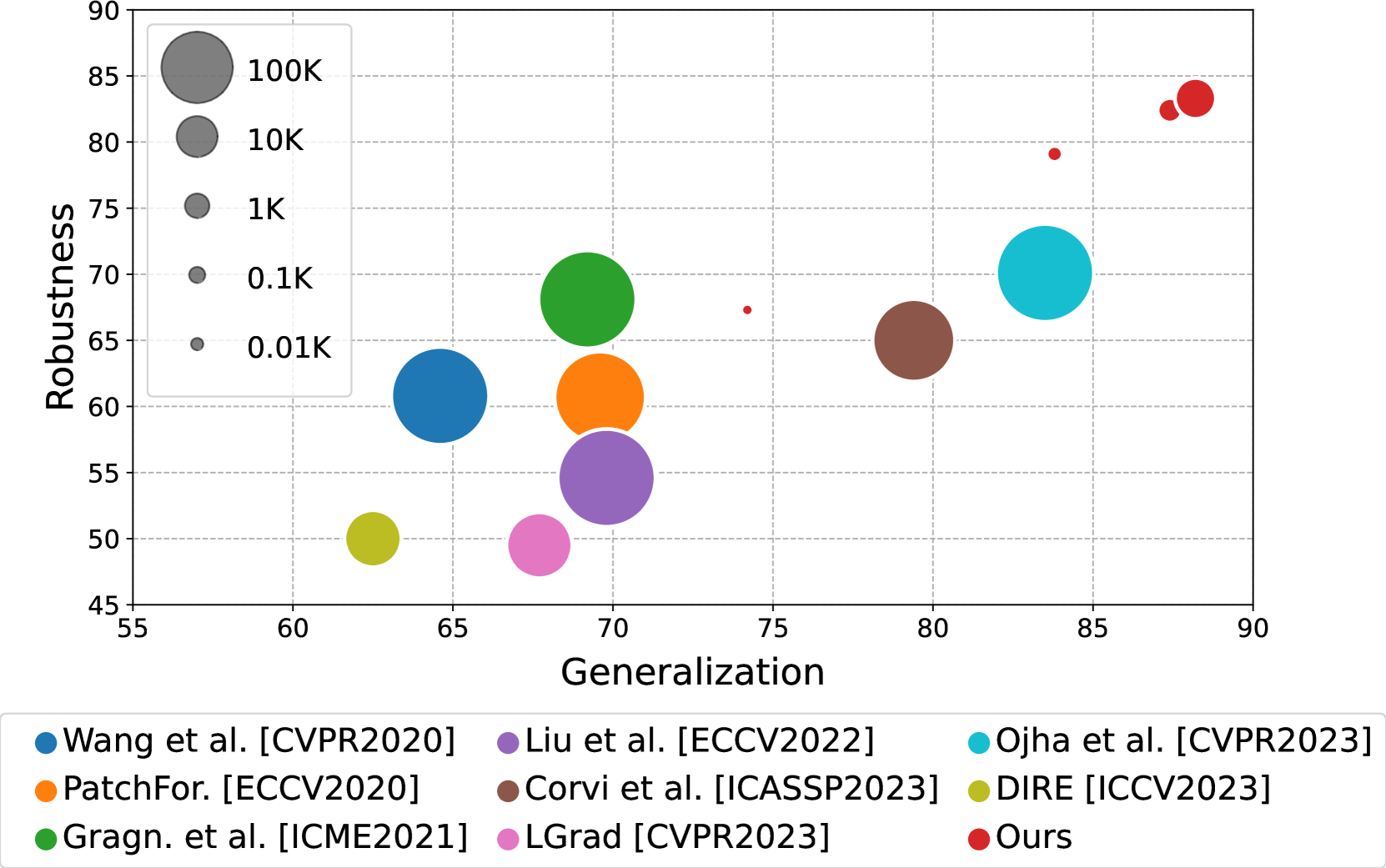
The aim of this work is to explore the potential of pre-trained vision-language models (VLMs) for universal detection of AI-generated images. We develop a lightweight detection strategy based on CLIP features and study its performance in a wide variety of challenging scenarios. We find that, contrary to previous beliefs, it is neither necessary nor convenient to use a large domain-specific dataset for training. On the contrary, by using only a handful of example images from a single generative model, a CLIP-based detector exhibits surprising generalization ability and high robustness across different architectures, including recent commercial tools such as Dalle-3, Midjourney v5, and Firefly. We match the state-of-the-art (SoTA) on in-distribution data and significantly improve upon it in terms of generalization to out-of-distribution data (+6% AUC) and robustness to impaired/laundered data (+13%). Our project is available at https://grip-unina.github.io/ClipBased-SyntheticImageDetection/
Read more4/30/2024

0
Fully Fine-tuned CLIP Models are Efficient Few-Shot Learners
Mushui Liu, Bozheng Li, Yunlong Yu
Prompt tuning, which involves training a small set of parameters, effectively enhances the pre-trained Vision-Language Models (VLMs) to downstream tasks. However, they often come at the cost of flexibility and adaptability when the tuned models are applied to different datasets or domains. In this paper, we explore capturing the task-specific information via meticulous refinement of entire VLMs, with minimal parameter adjustments. When fine-tuning the entire VLMs for specific tasks under limited supervision, overfitting and catastrophic forgetting become the defacto factors. To mitigate these issues, we propose a framework named CLIP-CITE via designing a discriminative visual-text task, further aligning the visual-text semantics in a supervision manner, and integrating knowledge distillation techniques to preserve the gained knowledge. Extensive experimental results under few-shot learning, base-to-new generalization, domain generalization, and cross-domain generalization settings, demonstrate that our method effectively enhances the performance on specific tasks under limited supervision while preserving the versatility of the VLMs on other datasets.
Read more7/8/2024
0
RWKV-CLIP: A Robust Vision-Language Representation Learner
Tiancheng Gu, Kaicheng Yang, Xiang An, Ziyong Feng, Dongnan Liu, Weidong Cai, Jiankang Deng
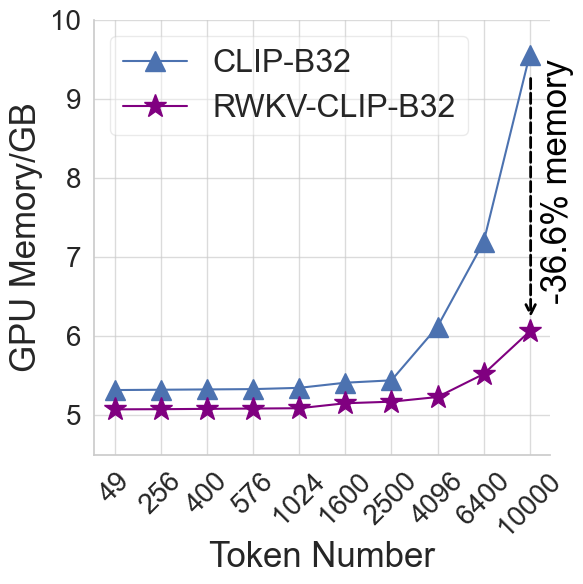
Contrastive Language-Image Pre-training (CLIP) has significantly improved performance in various vision-language tasks by expanding the dataset with image-text pairs obtained from websites. This paper further explores CLIP from the perspectives of data and model architecture. To address the prevalence of noisy data and enhance the quality of large-scale image-text data crawled from the internet, we introduce a diverse description generation framework that can leverage Large Language Models (LLMs) to synthesize and refine content from web-based texts, synthetic captions, and detection tags. Furthermore, we propose RWKV-CLIP, the first RWKV-driven vision-language representation learning model that combines the effective parallel training of transformers with the efficient inference of RNNs. Comprehensive experiments across various model scales and pre-training datasets demonstrate that RWKV-CLIP is a robust and efficient vision-language representation learner, it achieves state-of-the-art performance in several downstream tasks, including linear probe, zero-shot classification, and zero-shot image-text retrieval. To facilitate future research, the code and pre-trained models are released at https://github.com/deepglint/RWKV-CLIP
Read more6/12/2024