Teacher-Student Network for Real-World Face Super-Resolution with Progressive Embedding of Edge Information
2405.04778
0
0
🌐
Abstract
Traditional face super-resolution (FSR) methods trained on synthetic datasets usually have poor generalization ability for real-world face images. Recent work has utilized complex degradation models or training networks to simulate the real degradation process, but this limits the performance of these methods due to the domain differences that still exist between the generated low-resolution images and the real low-resolution images. Moreover, because of the existence of a domain gap, the semantic feature information of the target domain may be affected when synthetic data and real data are utilized to train super-resolution models simultaneously. In this study, a real-world face super-resolution teacher-student model is proposed, which considers the domain gap between real and synthetic data and progressively includes diverse edge information by using the recurrent network's intermediate outputs. Extensive experiments demonstrate that our proposed approach surpasses state-of-the-art methods in obtaining high-quality face images for real-world FSR.
Create account to get full access
Overview
- Traditional face super-resolution (FSR) methods trained on synthetic datasets often struggle to perform well on real-world face images.
- Recent approaches have tried to simulate the real degradation process, but this is limited by the domain differences that still exist between generated low-resolution images and real low-resolution images.
- There is also a domain gap when using synthetic and real data to train super-resolution models simultaneously, which can affect the semantic feature information of the target domain.
- The paper proposes a real-world face super-resolution teacher-student model that addresses the domain gap and progressively incorporates diverse edge information using a recurrent network's intermediate outputs.
- Experiments show this approach outperforms state-of-the-art methods in generating high-quality real-world face images.
Plain English Explanation
Super-resolution is the process of creating a higher quality image from a lower quality one. Traditional face super-resolution (FSR) methods often use synthetic, or computer-generated, low-resolution images to train their models. However, these models tend to perform poorly when applied to real-world, low-resolution face images due to differences between the synthetic and real data.
Recent work has tried to address this by simulating the real degradation process that occurs when capturing low-resolution images. But there are still gaps between the generated low-resolution images and the actual real-world low-resolution images. Additionally, when using both synthetic and real data to train super-resolution models, the domain differences can affect the semantic feature information that the model learns.
This paper proposes a new approach called a "real-world face super-resolution teacher-student model." The key ideas are:
- It specifically considers the domain gap between real and synthetic data.
- It progressively includes more diverse edge information by using the intermediate outputs of a recurrent neural network.
The researchers show through extensive experiments that this approach outperforms other state-of-the-art methods at generating high-quality face images from real-world, low-resolution inputs.
Technical Explanation
The paper presents a real-world face super-resolution (FSR) teacher-student model that addresses the domain gap between synthetic and real data. Traditional FSR methods trained on synthetic datasets often struggle to generalize well to real-world face images due to this domain mismatch.
Recent work has attempted to simulate the real degradation process by using complex degradation models or training networks to generate synthetic low-resolution images. However, there are still differences between the generated low-res images and actual real-world low-res images, limiting the performance of these methods.
Additionally, when using both synthetic and real data to train super-resolution models, the domain gap can affect the semantic feature information that the model learns about the target real-world domain.
To address these challenges, the proposed approach uses a teacher-student architecture. The teacher model is first trained on synthetic data, then the student model is trained on real data while distilling knowledge from the teacher. This helps bridge the domain gap.
Importantly, the student model also progressively incorporates diverse edge information by using the intermediate outputs of a recurrent network. This allows it to better capture the detailed structure of real-world face images.
Extensive experiments demonstrate that this real-world FSR teacher-student model outperforms state-of-the-art methods like Reference-Based Super-Resolution and Beyond Image Super-Resolution on real-world face image super-resolution tasks.
Critical Analysis
The paper provides a solid technical approach to addressing the domain gap issue in real-world face super-resolution. The use of a teacher-student architecture to distill knowledge from a model trained on synthetic data to one trained on real data is a promising strategy.
However, the paper does not fully explore the limitations of this approach. For example, it is unclear how well the method would generalize to very low-quality real-world face images or how sensitive it is to variations in the synthetic data generation process.
Additionally, the paper does not discuss potential biases that could be introduced by the recurrent network's edge information, or how this might impact the fairness and robustness of the super-resolution outputs.
Further research could investigate ways to more rigorously evaluate the real-world performance and limitations of this approach, as well as explore strategies to make it more robust and equitable.
Conclusion
This paper presents an innovative real-world face super-resolution teacher-student model that addresses the domain gap between synthetic and real data. By progressively incorporating diverse edge information, the approach is able to generate high-quality face images from real-world, low-resolution inputs, outperforming state-of-the-art methods.
While the technical approach is sound, further research is needed to fully understand the limitations and potential biases of this method. Nonetheless, this work represents an important step forward in improving the practicality and robustness of face super-resolution for real-world applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Real-GDSR: Real-World Guided DSM Super-Resolution via Edge-Enhancing Residual Network
Daniel Panangian, Ksenia Bittner
0
0
A low-resolution digital surface model (DSM) features distinctive attributes impacted by noise, sensor limitations and data acquisition conditions, which failed to be replicated using simple interpolation methods like bicubic. This causes super-resolution models trained on synthetic data does not perform effectively on real ones. Training a model on real low and high resolution DSMs pairs is also a challenge because of the lack of information. On the other hand, the existence of other imaging modalities of the same scene can be used to enrich the information needed for large-scale super-resolution. In this work, we introduce a novel methodology to address the intricacies of real-world DSM super-resolution, named REAL-GDSR, breaking down this ill-posed problem into two steps. The first step involves the utilization of a residual local refinement network. This strategic approach departs from conventional methods that trained to directly predict height values instead of the differences (residuals) and utilize large receptive fields in their networks. The second step introduces a diffusion-based technique that enhances the results on a global scale, with a primary focus on smoothing and edge preservation. Our experiments underscore the effectiveness of the proposed method. We conduct a comprehensive evaluation, comparing it to recent state-of-the-art techniques in the domain of real-world DSM super-resolution (SR). Our approach consistently outperforms these existing methods, as evidenced through qualitative and quantitative assessments.
4/8/2024
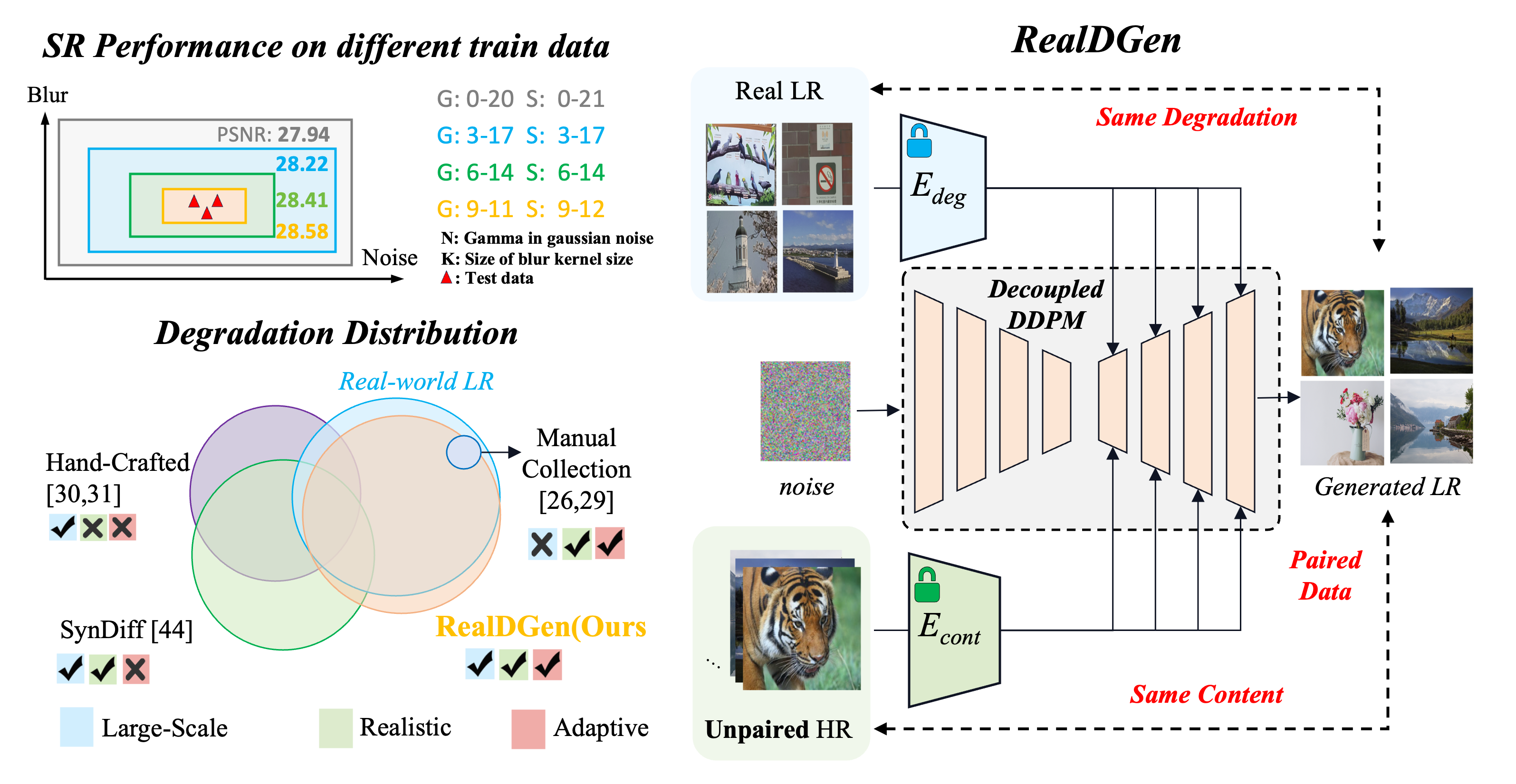
Towards Realistic Data Generation for Real-World Super-Resolution
Long Peng, Wenbo Li, Renjing Pei, Jingjing Ren, Xueyang Fu, Yang Wang, Yang Cao, Zheng-Jun Zha
0
0
Existing image super-resolution (SR) techniques often fail to generalize effectively in complex real-world settings due to the significant divergence between training data and practical scenarios. To address this challenge, previous efforts have either manually simulated intricate physical-based degradations or utilized learning-based techniques, yet these approaches remain inadequate for producing large-scale, realistic, and diverse data simultaneously. In this paper, we introduce a novel Realistic Decoupled Data Generator (RealDGen), an unsupervised learning data generation framework designed for real-world super-resolution. We meticulously develop content and degradation extraction strategies, which are integrated into a novel content-degradation decoupled diffusion model to create realistic low-resolution images from unpaired real LR and HR images. Extensive experiments demonstrate that RealDGen excels in generating large-scale, high-quality paired data that mirrors real-world degradations, significantly advancing the performance of popular SR models on various real-world benchmarks.
6/13/2024

SeeSR: Towards Semantics-Aware Real-World Image Super-Resolution
Rongyuan Wu, Tao Yang, Lingchen Sun, Zhengqiang Zhang, Shuai Li, Lei Zhang
0
0
Owe to the powerful generative priors, the pre-trained text-to-image (T2I) diffusion models have become increasingly popular in solving the real-world image super-resolution problem. However, as a consequence of the heavy quality degradation of input low-resolution (LR) images, the destruction of local structures can lead to ambiguous image semantics. As a result, the content of reproduced high-resolution image may have semantic errors, deteriorating the super-resolution performance. To address this issue, we present a semantics-aware approach to better preserve the semantic fidelity of generative real-world image super-resolution. First, we train a degradation-aware prompt extractor, which can generate accurate soft and hard semantic prompts even under strong degradation. The hard semantic prompts refer to the image tags, aiming to enhance the local perception ability of the T2I model, while the soft semantic prompts compensate for the hard ones to provide additional representation information. These semantic prompts encourage the T2I model to generate detailed and semantically accurate results. Furthermore, during the inference process, we integrate the LR images into the initial sampling noise to mitigate the diffusion model's tendency to generate excessive random details. The experiments show that our method can reproduce more realistic image details and hold better the semantics. The source code of our method can be found at https://github.com/cswry/SeeSR.
6/5/2024
Federated Learning for Blind Image Super-Resolution
Brian B. Moser, Ahmed Anwar, Federico Raue, Stanislav Frolov, Andreas Dengel
0
0
Traditional blind image SR methods need to model real-world degradations precisely. Consequently, current research struggles with this dilemma by assuming idealized degradations, which leads to limited applicability to actual user data. Moreover, the ideal scenario - training models on data from the targeted user base - presents significant privacy concerns. To address both challenges, we propose to fuse image SR with federated learning, allowing real-world degradations to be directly learned from users without invading their privacy. Furthermore, it enables optimization across many devices without data centralization. As this fusion is underexplored, we introduce new benchmarks specifically designed to evaluate new SR methods in this federated setting. By doing so, we employ known degradation modeling techniques from SR research. However, rather than aiming to mirror real degradations, our benchmarks use these degradation models to simulate the variety of degradations found across clients within a distributed user base. This distinction is crucial as it circumvents the need to precisely model real-world degradations, which limits contemporary blind image SR research. Our proposed benchmarks investigate blind image SR under new aspects, namely differently distributed degradation types among users and varying user numbers. We believe new methods tested within these benchmarks will perform more similarly in an application, as the simulated scenario addresses the variety while federated learning enables the training on actual degradations.
4/30/2024