TEII: Think, Explain, Interact and Iterate with Large Language Models to Solve Cross-lingual Emotion Detection
2405.17129
0
0
Abstract
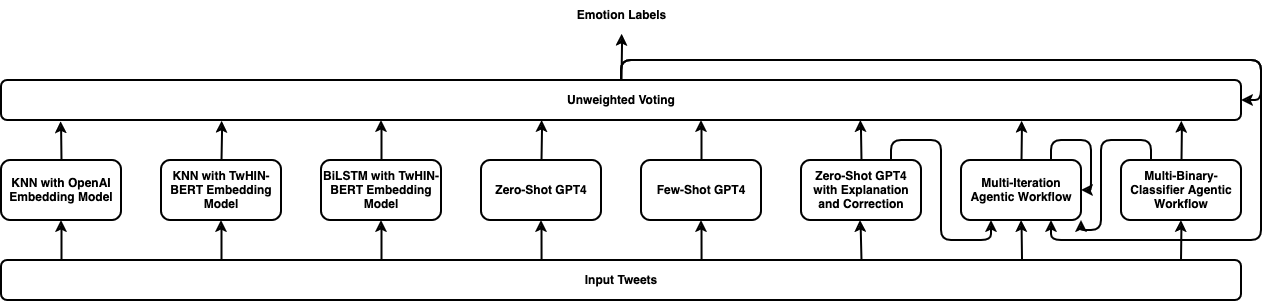
Cross-lingual emotion detection allows us to analyze global trends, public opinion, and social phenomena at scale. We participated in the Explainability of Cross-lingual Emotion Detection (EXALT) shared task, achieving an F1-score of 0.6046 on the evaluation set for the emotion detection sub-task. Our system outperformed the baseline by more than 0.16 F1-score absolute, and ranked second amongst competing systems. We conducted experiments using fine-tuning, zero-shot learning, and few-shot learning for Large Language Model (LLM)-based models as well as embedding-based BiLSTM and KNN for non-LLM-based techniques. Additionally, we introduced two novel methods: the Multi-Iteration Agentic Workflow and the Multi-Binary-Classifier Agentic Workflow. We found that LLM-based approaches provided good performance on multilingual emotion detection. Furthermore, ensembles combining all our experimented models yielded higher F1-scores than any single approach alone.
Create account to get full access
Overview
This research paper proposes a novel framework called TEII (Think, Explain, Interact, and Iterate) to improve cross-lingual emotion detection using large language models. The key idea is to leverage the strengths of these powerful models by having them engage in a multi-step process of thinking, explaining their reasoning, interacting with the user, and iterating on their approach. This allows the models to better understand the nuances of emotion detection across different languages and cultural contexts.
Plain English Explanation
The paper is focused on the challenge of detecting emotions in text, particularly when dealing with multiple languages. Emotion detection is an important task in natural language processing, as it can help machines better understand and respond to human communication.
The researchers recognized that existing emotion detection models often struggle when applied to languages and cultural contexts they weren't trained on. To address this, they developed the TEII framework, which has the model go through a series of steps:
- Think: The model first processes the input text and tries to determine the emotional state it conveys.
- Explain: The model then explains its reasoning for the detected emotion, revealing its internal thought process.
- Interact: The model engages with the user, asking for feedback or clarification to improve its understanding.
- Iterate: Based on the user's input, the model refines its emotion detection approach and repeats the process.
By having the model explain its logic, interact with the user, and iteratively refine its approach, the researchers found that it was able to achieve better cross-lingual emotion detection performance compared to traditional methods. This is because the model can learn from the user's feedback and adapt its understanding to different cultural contexts.
The TEII framework represents an innovative way to leverage the power of large language models to tackle complex natural language tasks, like emotion detection, in a more nuanced and adaptive manner. It demonstrates how AI systems can be designed to work collaboratively with humans to continuously improve their capabilities.
Technical Explanation
The paper proposes the TEII (Think, Explain, Interact, and Iterate) framework to address the challenge of cross-lingual emotion detection using large language models. The key steps are:
- Think: The model first processes the input text using a pre-trained large language model, such as BERT or GPT, to detect the emotional state conveyed in the text.
- Explain: The model then generates an explanation for its emotion detection, revealing its internal reasoning process. This is done by fine-tuning the language model on a dataset of emotion-annotated text paired with human-written explanations.
- Interact: The model engages in a dialogue with the user, asking for feedback or clarification on its emotion detection and explanation. This allows the model to better understand the nuances of emotion across different languages and cultural contexts.
- Iterate: Based on the user's input, the model refines its emotion detection approach and repeats the process, continuously improving its performance.
The researchers evaluated the TEII framework on cross-lingual emotion detection tasks, testing it on text in English, Chinese, and Spanish. They found that the TEII approach outperformed traditional emotion detection models, particularly in cases where the model was applied to languages and contexts it was not initially trained on.
The ability of the TEII framework to engage in an interactive, iterative process with users is a key innovation. This allows the model to learn from user feedback and adapt its understanding to different cultural and linguistic nuances, something that is often a challenge for more static emotion detection models.
Critical Analysis
The TEII framework proposed in this paper represents an important step forward in developing more robust and adaptable emotion detection systems, particularly for cross-lingual applications. By incorporating an interactive, iterative process, the model can learn from user feedback and continuously improve its performance.
However, the paper does not address some potential limitations of the approach. For example, the reliance on user feedback may limit the scalability of the system, as it requires direct human involvement. Additionally, the quality and consistency of the user feedback may vary, which could impact the model's learning process.
Furthermore, the paper does not discuss the computational and resource requirements of the TEII framework, which could be a practical concern for real-world deployment. Large language models are known to be computationally intensive, and the added steps of explanation generation and interactive dialogue may further increase the computational load.
Despite these potential limitations, the TEII framework demonstrates the value of designing AI systems that can work collaboratively with humans to solve complex natural language processing tasks. The ability to explain their reasoning, receive feedback, and iteratively refine their approach is a promising direction for the development of more trustworthy and versatile AI systems.
Conclusion
The TEII (Think, Explain, Interact, and Iterate) framework proposed in this paper represents a novel approach to improving cross-lingual emotion detection using large language models. By incorporating an interactive, iterative process, the model can learn from user feedback and adapt its understanding to different cultural and linguistic contexts, overcoming a key limitation of traditional emotion detection systems.
While the paper does not address all the potential challenges and limitations of the TEII framework, it highlights the value of designing AI systems that can work collaboratively with humans to solve complex natural language processing tasks. As the field of AI continues to advance, the ability of models to explain their reasoning, receive feedback, and iteratively refine their approach will be crucial for developing more trustworthy and versatile AI systems that can be deployed in real-world applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
💬
Modeling Emotions and Ethics with Large Language Models
Edward Y. Chang
0
0
This paper explores the integration of human-like emotions and ethical considerations into Large Language Models (LLMs). We first model eight fundamental human emotions, presented as opposing pairs, and employ collaborative LLMs to reinterpret and express these emotions across a spectrum of intensity. Our focus extends to embedding a latent ethical dimension within LLMs, guided by a novel self-supervised learning algorithm with human feedback (SSHF). This approach enables LLMs to perform self-evaluations and adjustments concerning ethical guidelines, enhancing their capability to generate content that is not only emotionally resonant but also ethically aligned. The methodologies and case studies presented herein illustrate the potential of LLMs to transcend mere text and image generation, venturing into the realms of empathetic interaction and principled decision-making, thereby setting a new precedent in the development of emotionally aware and ethically conscious AI systems.
4/23/2024
💬
EmoLLMs: A Series of Emotional Large Language Models and Annotation Tools for Comprehensive Affective Analysis
Zhiwei Liu, Kailai Yang, Tianlin Zhang, Qianqian Xie, Sophia Ananiadou
0
0
Sentiment analysis and emotion detection are important research topics in natural language processing (NLP) and benefit many downstream tasks. With the widespread application of LLMs, researchers have started exploring the application of LLMs based on instruction-tuning in the field of sentiment analysis. However, these models only focus on single aspects of affective classification tasks (e.g. sentimental polarity or categorical emotions), and overlook the regression tasks (e.g. sentiment strength or emotion intensity), which leads to poor performance in downstream tasks. The main reason is the lack of comprehensive affective instruction tuning datasets and evaluation benchmarks, which cover various affective classification and regression tasks. Moreover, although emotional information is useful for downstream tasks, existing downstream datasets lack high-quality and comprehensive affective annotations. In this paper, we propose EmoLLMs, the first series of open-sourced instruction-following LLMs for comprehensive affective analysis based on fine-tuning various LLMs with instruction data, the first multi-task affective analysis instruction dataset (AAID) with 234K data samples based on various classification and regression tasks to support LLM instruction tuning, and a comprehensive affective evaluation benchmark (AEB) with 14 tasks from various sources and domains to test the generalization ability of LLMs. We propose a series of EmoLLMs by fine-tuning LLMs with AAID to solve various affective instruction tasks. We compare our model with a variety of LLMs on AEB, where our models outperform all other open-sourced LLMs, and surpass ChatGPT and GPT-4 in most tasks, which shows that the series of EmoLLMs achieve the ChatGPT-level and GPT-4-level generalization capabilities on affective analysis tasks, and demonstrates our models can be used as affective annotation tools.
6/19/2024

New!The Model Arena for Cross-lingual Sentiment Analysis: A Comparative Study in the Era of Large Language Models
Xiliang Zhu, Shayna Gardiner, Tere Rold'an, David Rossouw
0
0
Sentiment analysis serves as a pivotal component in Natural Language Processing (NLP). Advancements in multilingual pre-trained models such as XLM-R and mT5 have contributed to the increasing interest in cross-lingual sentiment analysis. The recent emergence in Large Language Models (LLM) has significantly advanced general NLP tasks, however, the capability of such LLMs in cross-lingual sentiment analysis has not been fully studied. This work undertakes an empirical analysis to compare the cross-lingual transfer capability of public Small Multilingual Language Models (SMLM) like XLM-R, against English-centric LLMs such as Llama-3, in the context of sentiment analysis across English, Spanish, French and Chinese. Our findings reveal that among public models, SMLMs exhibit superior zero-shot cross-lingual performance relative to LLMs. However, in few-shot cross-lingual settings, public LLMs demonstrate an enhanced adaptive potential. In addition, we observe that proprietary GPT-3.5 and GPT-4 lead in zero-shot cross-lingual capability, but are outpaced by public models in few-shot scenarios.
6/28/2024
Emotion-LLaMA: Multimodal Emotion Recognition and Reasoning with Instruction Tuning
Zebang Cheng, Zhi-Qi Cheng, Jun-Yan He, Jingdong Sun, Kai Wang, Yuxiang Lin, Zheng Lian, Xiaojiang Peng, Alexander Hauptmann
0
0
Accurate emotion perception is crucial for various applications, including human-computer interaction, education, and counseling. However, traditional single-modality approaches often fail to capture the complexity of real-world emotional expressions, which are inherently multimodal. Moreover, existing Multimodal Large Language Models (MLLMs) face challenges in integrating audio and recognizing subtle facial micro-expressions. To address this, we introduce the MERR dataset, containing 28,618 coarse-grained and 4,487 fine-grained annotated samples across diverse emotional categories. This dataset enables models to learn from varied scenarios and generalize to real-world applications. Furthermore, we propose Emotion-LLaMA, a model that seamlessly integrates audio, visual, and textual inputs through emotion-specific encoders. By aligning features into a shared space and employing a modified LLaMA model with instruction tuning, Emotion-LLaMA significantly enhances both emotional recognition and reasoning capabilities. Extensive evaluations show Emotion-LLaMA outperforms other MLLMs, achieving top scores in Clue Overlap (7.83) and Label Overlap (6.25) on EMER, an F1 score of 0.9036 on MER2023 challenge, and the highest UAR (45.59) and WAR (59.37) in zero-shot evaluations on DFEW dataset.
6/18/2024