The Model Arena for Cross-lingual Sentiment Analysis: A Comparative Study in the Era of Large Language Models
2406.19358
0
0

Abstract
Sentiment analysis serves as a pivotal component in Natural Language Processing (NLP). Advancements in multilingual pre-trained models such as XLM-R and mT5 have contributed to the increasing interest in cross-lingual sentiment analysis. The recent emergence in Large Language Models (LLM) has significantly advanced general NLP tasks, however, the capability of such LLMs in cross-lingual sentiment analysis has not been fully studied. This work undertakes an empirical analysis to compare the cross-lingual transfer capability of public Small Multilingual Language Models (SMLM) like XLM-R, against English-centric LLMs such as Llama-3, in the context of sentiment analysis across English, Spanish, French and Chinese. Our findings reveal that among public models, SMLMs exhibit superior zero-shot cross-lingual performance relative to LLMs. However, in few-shot cross-lingual settings, public LLMs demonstrate an enhanced adaptive potential. In addition, we observe that proprietary GPT-3.5 and GPT-4 lead in zero-shot cross-lingual capability, but are outpaced by public models in few-shot scenarios.
Create account to get full access
Overview
- This paper presents a comprehensive comparative study of various cross-lingual sentiment analysis models, including both traditional machine learning and large language models (LLMs).
- The researchers explore the performance and capabilities of these models across multiple languages, aiming to provide insights into the current state of the art in cross-lingual sentiment analysis.
- The study compares the models' ability to handle sentiment analysis tasks in different languages, as well as their performance on code-switched and multilingual data.
Plain English Explanation
The paper examines different models that can analyze the sentiment (positive, negative, or neutral) of text written in multiple languages. The researchers compare the performance of traditional machine learning models and more recent large language models (LLMs) on these cross-lingual sentiment analysis tasks.
The goal is to understand the current capabilities and limitations of these models when dealing with text in different languages, as well as scenarios where the text contains a mix of languages (code-switching). This information can help researchers and practitioners choose the most appropriate models for their cross-lingual sentiment analysis needs.
Technical Explanation
The researchers evaluate a range of models, including traditional machine learning models and large language models (LLMs), on cross-lingual sentiment analysis tasks. They assess the models' performance on datasets with text in multiple languages, as well as code-switched scenarios where the text contains a mix of languages.
The study examines the models' ability to handle sentiment analysis in different languages, including their robustness to language variations and their cross-lingual transfer capabilities. The researchers also investigate the impact of model scale and multilingual training on the models' cross-lingual sentiment analysis performance.
The findings provide insights into the current state of the art in cross-lingual sentiment analysis, highlighting the strengths and limitations of the various models and identifying areas for future research and development.
Critical Analysis
The paper presents a thorough and well-designed comparative study, but it acknowledges several limitations and areas for further investigation. For example, the researchers note that the performance of the models may be influenced by factors such as dataset size, language similarity, and the specific characteristics of the sentiment analysis tasks.
Additionally, the study focused on a limited set of languages and did not explore the potential impact of linguistic and cultural nuances on the models' performance. Further research could expand the linguistic diversity of the datasets and investigate the challenges of aligning multilingual data for cross-lingual sentiment analysis.
Conclusion
This paper provides a comprehensive evaluation of the current state of cross-lingual sentiment analysis models, including both traditional machine learning and large language models. The findings offer valuable insights into the strengths, limitations, and potential areas for improvement in this field.
The study's comparative approach and insights can inform the development of more robust and versatile cross-lingual sentiment analysis systems, which have important applications in areas such as social media monitoring, customer service, and multilingual content analysis.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Crosslingual Capabilities and Knowledge Barriers in Multilingual Large Language Models
Lynn Chua, Badih Ghazi, Yangsibo Huang, Pritish Kamath, Ravi Kumar, Pasin Manurangsi, Amer Sinha, Chulin Xie, Chiyuan Zhang
0
0
Large language models (LLMs) are typically multilingual due to pretraining on diverse multilingual corpora. But can these models relate corresponding concepts across languages, effectively being crosslingual? This study evaluates six state-of-the-art LLMs on inherently crosslingual tasks. We observe that while these models show promising surface-level crosslingual abilities on machine translation and embedding space analyses, they struggle with deeper crosslingual knowledge transfer, revealing a crosslingual knowledge barrier in both general (MMLU benchmark) and domain-specific (Harry Potter quiz) contexts. We observe that simple inference-time mitigation methods offer only limited improvement. On the other hand, we propose fine-tuning of LLMs on mixed-language data, which effectively reduces these gaps, even when using out-of-domain datasets like WikiText. Our findings suggest the need for explicit optimization to unlock the full crosslingual potential of LLMs. Our code is publicly available at https://github.com/google-research/crosslingual-knowledge-barriers.
6/26/2024
Beyond Metrics: Evaluating LLMs' Effectiveness in Culturally Nuanced, Low-Resource Real-World Scenarios
Millicent Ochieng, Varun Gumma, Sunayana Sitaram, Jindong Wang, Vishrav Chaudhary, Keshet Ronen, Kalika Bali, Jacki O'Neill
0
0
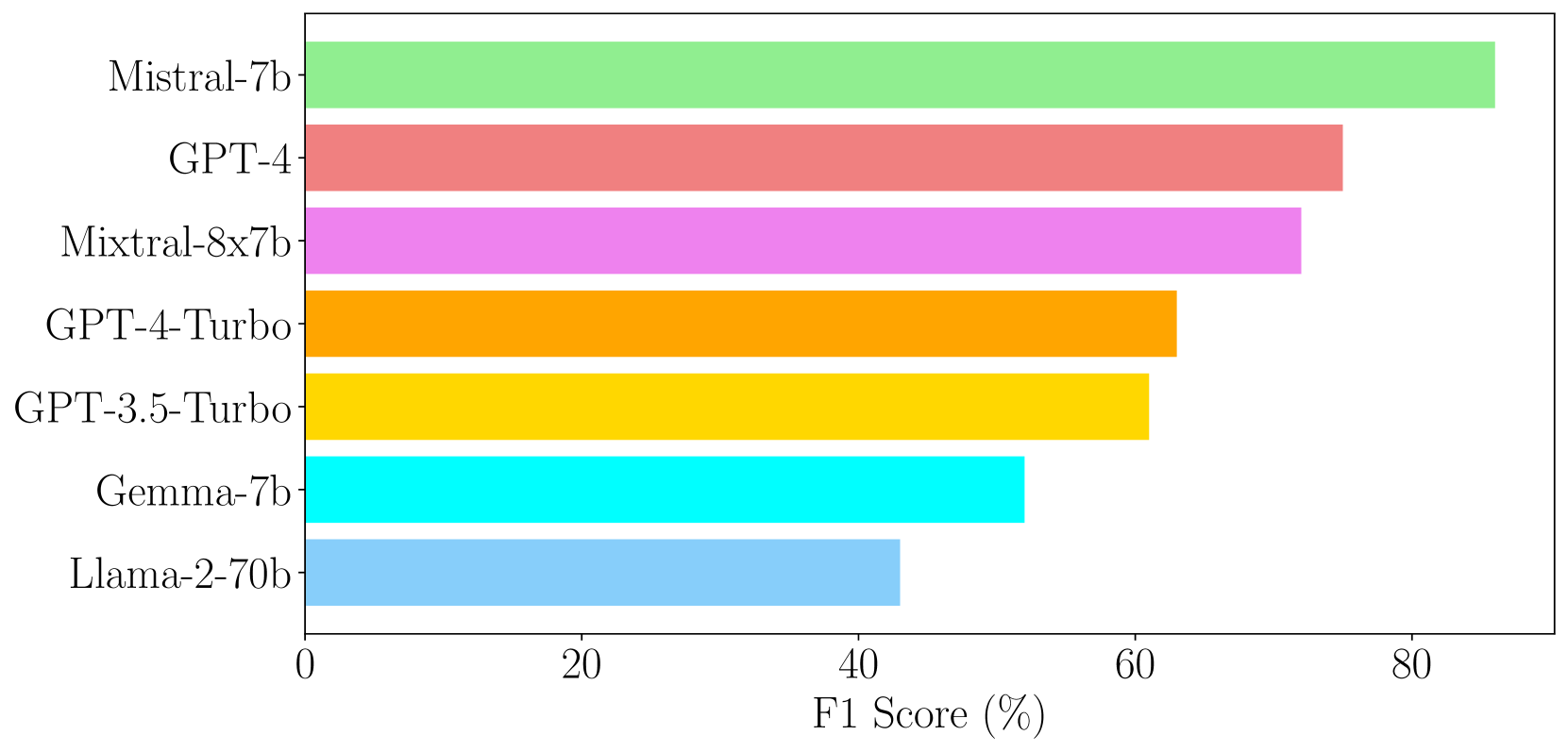
The deployment of Large Language Models (LLMs) in real-world applications presents both opportunities and challenges, particularly in multilingual and code-mixed communication settings. This research evaluates the performance of seven leading LLMs in sentiment analysis on a dataset derived from multilingual and code-mixed WhatsApp chats, including Swahili, English and Sheng. Our evaluation includes both quantitative analysis using metrics like F1 score and qualitative assessment of LLMs' explanations for their predictions. We find that, while Mistral-7b and Mixtral-8x7b achieved high F1 scores, they and other LLMs such as GPT-3.5-Turbo, Llama-2-70b, and Gemma-7b struggled with understanding linguistic and contextual nuances, as well as lack of transparency in their decision-making process as observed from their explanations. In contrast, GPT-4 and GPT-4-Turbo excelled in grasping diverse linguistic inputs and managing various contextual information, demonstrating high consistency with human alignment and transparency in their decision-making process. The LLMs however, encountered difficulties in incorporating cultural nuance especially in non-English settings with GPT-4s doing so inconsistently. The findings emphasize the necessity of continuous improvement of LLMs to effectively tackle the challenges of culturally nuanced, low-resource real-world settings and the need for developing evaluation benchmarks for capturing these issues.
6/14/2024
Large Language Models Meet Text-Centric Multimodal Sentiment Analysis: A Survey
Hao Yang, Yanyan Zhao, Yang Wu, Shilong Wang, Tian Zheng, Hongbo Zhang, Wanxiang Che, Bing Qin
0
0
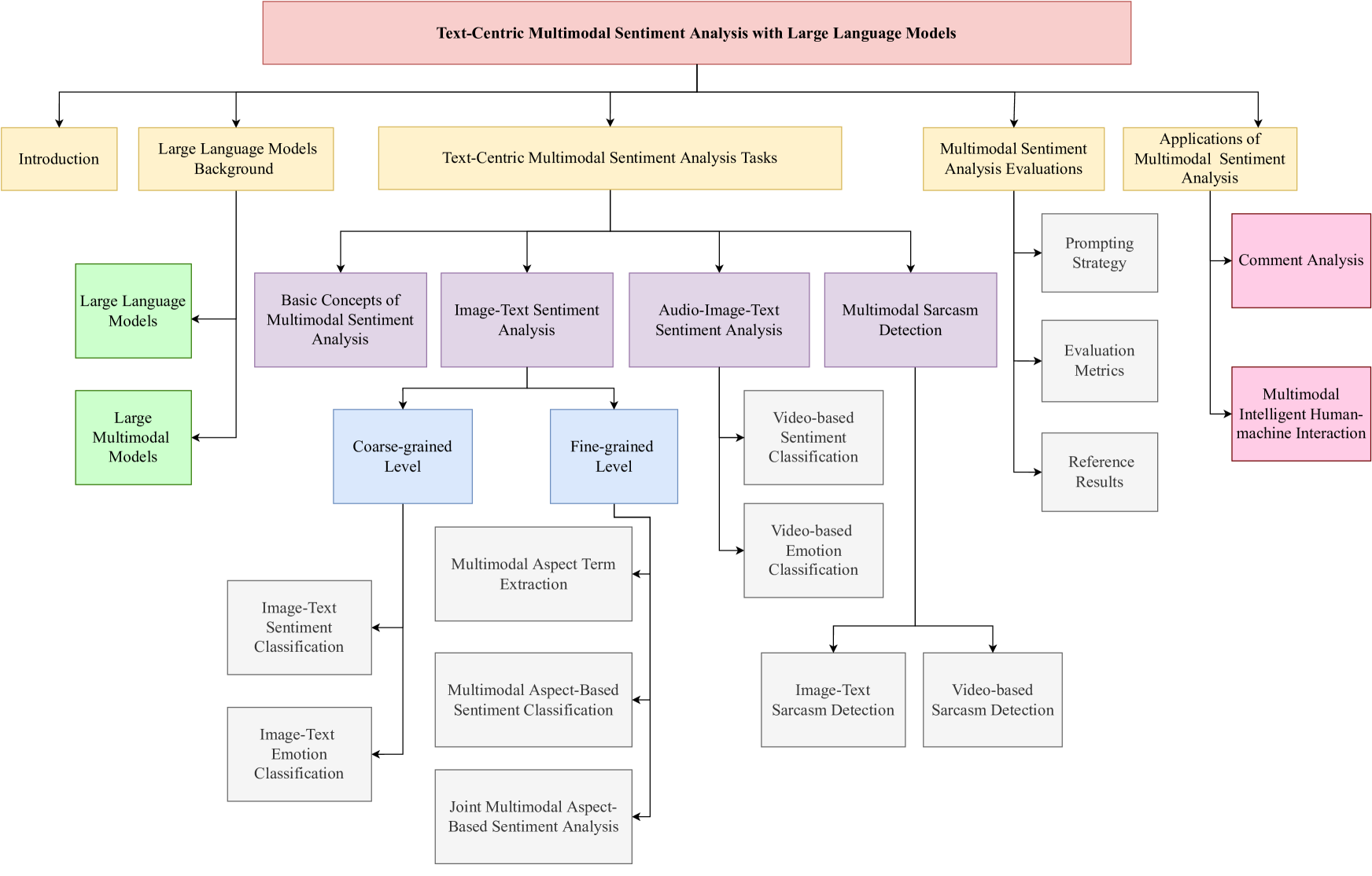
Compared to traditional sentiment analysis, which only considers text, multimodal sentiment analysis needs to consider emotional signals from multimodal sources simultaneously and is therefore more consistent with the way how humans process sentiment in real-world scenarios. It involves processing emotional information from various sources such as natural language, images, videos, audio, physiological signals, etc. However, although other modalities also contain diverse emotional cues, natural language usually contains richer contextual information and therefore always occupies a crucial position in multimodal sentiment analysis. The emergence of ChatGPT has opened up immense potential for applying large language models (LLMs) to text-centric multimodal tasks. However, it is still unclear how existing LLMs can adapt better to text-centric multimodal sentiment analysis tasks. This survey aims to (1) present a comprehensive review of recent research in text-centric multimodal sentiment analysis tasks, (2) examine the potential of LLMs for text-centric multimodal sentiment analysis, outlining their approaches, advantages, and limitations, (3) summarize the application scenarios of LLM-based multimodal sentiment analysis technology, and (4) explore the challenges and potential research directions for multimodal sentiment analysis in the future.
6/13/2024
A Survey on Multilingual Large Language Models: Corpora, Alignment, and Bias
Yuemei Xu, Ling Hu, Jiayi Zhao, Zihan Qiu, Yuqi Ye, Hanwen Gu
0
0
Based on the foundation of Large Language Models (LLMs), Multilingual Large Language Models (MLLMs) have been developed to address the challenges of multilingual natural language processing tasks, hoping to achieve knowledge transfer from high-resource to low-resource languages. However, significant limitations and challenges still exist, such as language imbalance, multilingual alignment, and inherent bias. In this paper, we aim to provide a comprehensive analysis of MLLMs, delving deeply into discussions surrounding these critical issues. First of all, we start by presenting an overview of MLLMs, covering their evolution, key techniques, and multilingual capacities. Secondly, we explore widely utilized multilingual corpora for MLLMs' training and multilingual datasets oriented for downstream tasks that are crucial for enhancing the cross-lingual capability of MLLMs. Thirdly, we survey the existing studies on multilingual representations and investigate whether the current MLLMs can learn a universal language representation. Fourthly, we discuss bias on MLLMs including its category and evaluation metrics, and summarize the existing debiasing techniques. Finally, we discuss existing challenges and point out promising research directions. By demonstrating these aspects, this paper aims to facilitate a deeper understanding of MLLMs and their potentiality in various domains.
6/7/2024