TensAIR: Real-Time Training of Neural Networks from Data-streams

0
🏋️
Sign in to get full access
Overview
- This paper presents TensAIR, a new system for training artificial neural networks in real-time from data streams.
- Existing stream processing platforms like Apache Kafka and Flink have basic support for training neural networks, but they suffer from performance and scalability issues when doing so in real-time.
- TensAIR addresses these limitations with a decentralized and asynchronous architecture that uses decentralized and asynchronous stochastic gradient descent to train neural network models.
Plain English Explanation
The paper discusses a new system called TensAIR that can train artificial neural networks in real-time as data streams in. Existing stream processing platforms have some ability to train neural networks, but they struggle to do it fast enough and efficiently enough to keep up with rapidly arriving data.
TensAIR solves this problem by using a decentralized and asynchronous architecture. This means the training happens in a distributed way across multiple computers, and the individual computers don't have to wait for each other to complete each training step. This allows TensAIR to scale up very well as you add more computers, achieving near-linear increases in performance.
The paper demonstrates TensAIR's capabilities on both sparse data (like text) and dense data (like images), showing it can significantly outperform other systems at sustaining high data throughput rates while training neural networks. This makes TensAIR well-suited for real-time applications like online scheduling or piano transcription that need to process and make predictions on data as it arrives.
Technical Explanation
The paper presents TensAIR, a system designed to train artificial neural networks in real-time from data streams. Existing stream processing platforms like Apache Kafka and Flink have basic extensions for training neural networks, but they struggle with performance and scalability issues when attempting to do so in a real-time setting.
TensAIR addresses these limitations by using a decentralized and asynchronous architecture to train neural network models. It employs decentralized and asynchronous stochastic gradient descent to update model parameters in a distributed manner, without the individual worker nodes having to wait for each other to complete each training step.
The authors empirically demonstrate that TensAIR achieves near-linear scale-out performance as the number of worker nodes is increased, as well as in terms of the throughput rate of the incoming data batches. They evaluate TensAIR on both sparse (word embedding) and dense (image classification) use cases, showing that it can achieve 6 to 116 times higher sustainable throughput rates compared to state-of-the-art systems for training neural networks in a stream processing pipeline.
Critical Analysis
The paper provides a thorough evaluation of TensAIR's performance and scalability, clearly demonstrating its advantages over existing systems. However, the authors do not discuss any potential limitations or caveats of their approach.
For example, the decentralized and asynchronous nature of the training process may introduce challenges in terms of model convergence or stability, especially for more complex neural network architectures. Additionally, the paper does not address how TensAIR would handle concept drift or changes in the underlying data distribution over time, which can be a significant challenge in real-world streaming applications.
Further research could explore the robustness of TensAIR under various data stream conditions, such as varying degrees of concept drift, and investigate strategies to ensure stable and reliable model updates in a decentralized setting. Comparisons to other real-time machine learning approaches beyond stream processing platforms would also help contextualize the performance and applicability of TensAIR.
Conclusion
The TensAIR system presented in this paper represents a significant advancement in the field of online learning from data streams. By employing a decentralized and asynchronous architecture, TensAIR is able to achieve remarkable performance and scalability when training artificial neural networks in real-time.
The versatility of TensAIR, demonstrated across both sparse and dense data use cases, suggests it could be a valuable tool for a wide range of real-time applications that require fast, reliable, and scalable machine learning models. As the volume and velocity of data continues to increase, systems like TensAIR will become increasingly important for unlocking the full potential of online learning and real-time data processing.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🏋️
0
TensAIR: Real-Time Training of Neural Networks from Data-streams
Mauro D. L. Tosi, Vinu E. Venugopal, Martin Theobald
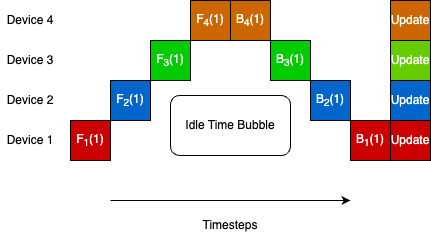
Online learning (OL) from data streams is an emerging area of research that encompasses numerous challenges from stream processing, machine learning, and networking. Stream-processing platforms, such as Apache Kafka and Flink, have basic extensions for the training of Artificial Neural Networks (ANNs) in a stream-processing pipeline. However, these extensions were not designed to train ANNs in real-time, and they suffer from performance and scalability issues when doing so. This paper presents TensAIR, the first OL system for training ANNs in real time. TensAIR achieves remarkable performance and scalability by using a decentralized and asynchronous architecture to train ANN models (either freshly initialized or pre-trained) via DASGD (decentralized and asynchronous stochastic gradient descent). We empirically demonstrate that TensAIR achieves a nearly linear scale-out performance in terms of (1) the number of worker nodes deployed in the network, and (2) the throughput at which the data batches arrive at the dataflow operators. We depict the versatility of TensAIR by investigating both sparse (word embedding) and dense (image classification) use cases, for which TensAIR achieved from 6 to 116 times higher sustainable throughput rates than state-of-the-art systems for training ANN in a stream-processing pipeline.
Read more4/19/2024
0
Ravnest: Decentralized Asynchronous Training on Heterogeneous Devices
Anirudh Rajiv Menon, Unnikrishnan Menon, Kailash Ahirwar
Modern deep learning models, growing larger and more complex, have demonstrated exceptional generalization and accuracy due to training on huge datasets. This trend is expected to continue. However, the increasing size of these models poses challenges in training, as traditional centralized methods are limited by memory constraints at such scales. This paper proposes an asynchronous decentralized training paradigm for large modern deep learning models that harnesses the compute power of regular heterogeneous PCs with limited resources connected across the internet to achieve favourable performance metrics. Ravnest facilitates decentralized training by efficiently organizing compute nodes into clusters with similar data transfer rates and compute capabilities, without necessitating that each node hosts the entire model. These clusters engage in $textit{Zero-Bubble Asynchronous Model Parallel}$ training, and a $textit{Parallel Multi-Ring All-Reduce}$ method is employed to effectively execute global parameter averaging across all clusters. We have framed our asynchronous SGD loss function as a block structured optimization problem with delayed updates and derived an optimal convergence rate of $Oleft(frac{1}{sqrt{K}}right)$. We further discuss linear speedup with respect to the number of participating clusters and the bound on the staleness parameter.
Read more5/24/2024
0
Multi-Stream Cellular Test-Time Adaptation of Real-Time Models Evolving in Dynamic Environments
Beno^it G'erin, Anais Halin, Anthony Cioppa, Maxim Henry, Bernard Ghanem, Beno^it Macq, Christophe De Vleeschouwer, Marc Van Droogenbroeck
In the era of the Internet of Things (IoT), objects connect through a dynamic network, empowered by technologies like 5G, enabling real-time data sharing. However, smart objects, notably autonomous vehicles, face challenges in critical local computations due to limited resources. Lightweight AI models offer a solution but struggle with diverse data distributions. To address this limitation, we propose a novel Multi-Stream Cellular Test-Time Adaptation (MSC-TTA) setup where models adapt on the fly to a dynamic environment divided into cells. Then, we propose a real-time adaptive student-teacher method that leverages the multiple streams available in each cell to quickly adapt to changing data distributions. We validate our methodology in the context of autonomous vehicles navigating across cells defined based on location and weather conditions. To facilitate future benchmarking, we release a new multi-stream large-scale synthetic semantic segmentation dataset, called DADE, and show that our multi-stream approach outperforms a single-stream baseline. We believe that our work will open research opportunities in the IoT and 5G eras, offering solutions for real-time model adaptation.
Read more4/30/2024

0
A Real-Time Adaptive Multi-Stream GPU System for Online Approximate Nearest Neighborhood Search
Yiping Sun, Yang Shi, Jiaolong Du
In recent years, Approximate Nearest Neighbor Search (ANNS) has played a pivotal role in modern search and recommendation systems, especially in emerging LLM applications like Retrieval-Augmented Generation. There is a growing exploration into harnessing the parallel computing capabilities of GPUs to meet the substantial demands of ANNS. However, existing systems primarily focus on offline scenarios, overlooking the distinct requirements of online applications that necessitate real-time insertion of new vectors. This limitation renders such systems inefficient for real-world scenarios. Moreover, previous architectures struggled to effectively support real-time insertion due to their reliance on serial execution streams. In this paper, we introduce a novel Real-Time Adaptive Multi-Stream GPU ANNS System (RTAMS-GANNS). Our architecture achieves its objectives through three key advancements: 1) We initially examined the real-time insertion mechanisms in existing GPU ANNS systems and discovered their reliance on repetitive copying and memory allocation, which significantly hinders real-time effectiveness on GPUs. As a solution, we introduce a dynamic vector insertion algorithm based on memory blocks, which includes in-place rearrangement. 2) To enable real-time vector insertion in parallel, we introduce a multi-stream parallel execution mode, which differs from existing systems that operate serially within a single stream. Our system utilizes a dynamic resource pool, allowing multiple streams to execute concurrently without additional execution blocking. 3) Through extensive experiments and comparisons, our approach effectively handles varying QPS levels across different datasets, reducing latency by up to 40%-80%. The proposed system has also been deployed in real-world industrial search and recommendation systems, serving hundreds of millions of users daily, and has achieved good results.
Read more8/7/2024