Textual Unlearning Gives a False Sense of Unlearning
2406.13348
0
0
Abstract
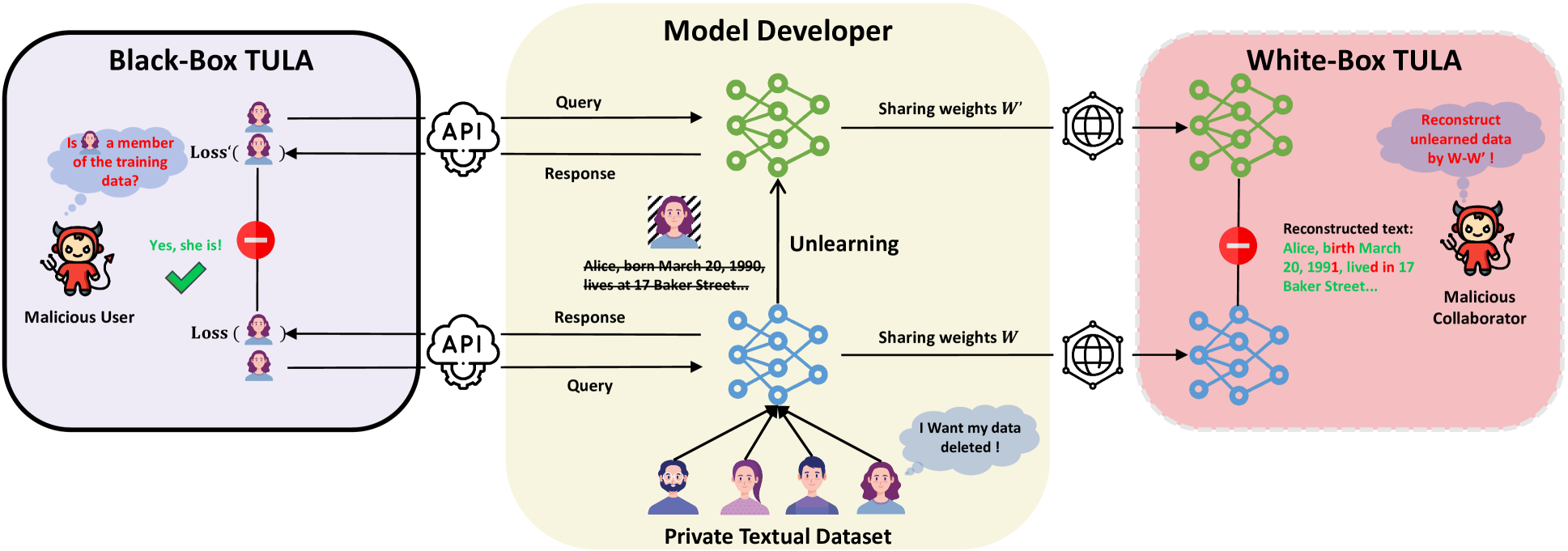
Language models (LMs) are susceptible to memorizing training data, including a large amount of private or copyright-protected content. To safeguard the right to be forgotten (RTBF), machine unlearning has emerged as a promising method for LMs to efficiently forget sensitive training content and mitigate knowledge leakage risks. However, despite its good intentions, could the unlearning mechanism be counterproductive? In this paper, we propose the Textual Unlearning Leakage Attack (TULA), where an adversary can infer information about the unlearned data only by accessing the models before and after unlearning. Furthermore, we present variants of TULA in both black-box and white-box scenarios. Through various experimental results, we critically demonstrate that machine unlearning amplifies the risk of knowledge leakage from LMs. Specifically, TULA can increase an adversary's ability to infer membership information about the unlearned data by more than 20% in black-box scenario. Moreover, TULA can even reconstruct the unlearned data directly with more than 60% accuracy with white-box access. Our work is the first to reveal that machine unlearning in LMs can inversely create greater knowledge risks and inspire the development of more secure unlearning mechanisms.
Create account to get full access
Overview
- Explores the concept of "textual unlearning" in large language models (LLMs) and how it can create a false sense of unlearning
- Discusses the limitations of relying solely on textual information for unlearning, highlighting the need for a more comprehensive approach
Plain English Explanation
The paper examines the concept of "textual unlearning" in large language models (LLMs), which refers to the process of removing or forgetting specific information from the model's training data. The researchers argue that relying solely on textual unlearning can give a false sense of unlearning, as the model may still retain information in other forms, such as embeddings or representations.
The paper suggests that a more comprehensive approach is needed to truly unlearn information, one that goes beyond just removing textual data. This is particularly important in the context of LLMs, which can learn and retain a vast amount of information from their training data, not all of which is easily accessible or removable through textual unlearning.
The researchers highlight the need for further research and development of more effective unlearning techniques that can address the limitations of textual unlearning. This is crucial as LLMs become more widely adopted and the importance of ensuring the responsible and ethical development of these models becomes increasingly paramount.
Technical Explanation
The paper explores the concept of "textual unlearning" in large language models (LLMs), which refers to the process of removing or forgetting specific information from the model's training data. The researchers argue that this approach can give a false sense of unlearning, as the model may still retain information in other forms, such as embeddings or representations.
To investigate this phenomenon, the authors conduct experiments on several LLMs, including BERT, GPT-2, and T5. They use various techniques to assess the model's ability to unlearn specific information, such as probing the model's outputs and analyzing its internal representations.
The results of the experiments demonstrate that while textual unlearning can be effective in removing certain types of information from the model's outputs, it does not necessarily eliminate the underlying representations or embeddings that the model has learned. This means that the model may still retain knowledge or biases that are not directly reflected in its textual outputs.
The paper also discusses the implications of these findings for the development of more effective unlearning techniques, such as those proposed in Towards Natural Machine Unlearning and Avoiding Copyright Infringement via Machine Unlearning. The authors emphasize the need for a more comprehensive approach to unlearning that goes beyond just removing textual data, and that considers the various forms of information that can be encoded in LLMs.
Critical Analysis
The paper raises important concerns about the limitations of relying solely on textual unlearning for large language models (LLMs). The researchers make a compelling case that the underlying representations and embeddings of the model can persist even after textual unlearning, potentially leading to a false sense of unlearning.
One potential limitation of the study is the scope of the experiments, which focused on a limited set of LLMs and unlearning techniques. It would be interesting to see if the findings hold true for a wider range of models and unlearning approaches, particularly those that leverage more advanced techniques like Towards Natural Machine Unlearning.
Additionally, the paper does not delve deeply into the potential implications of this false sense of unlearning, such as the risks of deploying LLMs that may still retain unwanted information or biases. Further research could explore the real-world consequences of this issue and ways to mitigate them.
Overall, the paper makes a valuable contribution to the ongoing discussions around machine unlearning and the responsible development of LLMs. The findings highlight the need for more comprehensive and rigorous approaches to unlearning that go beyond just textual information, and the authors rightly call for continued innovation in this important area of research.
Conclusion
The paper "Textual Unlearning Gives a False Sense of Unlearning" sheds light on the limitations of relying solely on textual unlearning for large language models (LLMs). The researchers demonstrate that while textual unlearning can be effective in removing certain types of information from the model's outputs, the underlying representations and embeddings may still retain knowledge or biases, leading to a false sense of unlearning.
This work underscores the need for more comprehensive and effective unlearning techniques that can address the complexities of the information encoded in LLMs. As these models continue to grow in importance and influence, ensuring their responsible and ethical development becomes increasingly crucial. The insights from this paper and the proposed directions for future research can help drive the advancement of machine unlearning capabilities, ultimately contributing to the development of more trustworthy and transparent AI systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
💬
To Each (Textual Sequence) Its Own: Improving Memorized-Data Unlearning in Large Language Models
George-Octavian Barbulescu, Peter Triantafillou
0
0
LLMs have been found to memorize training textual sequences and regurgitate verbatim said sequences during text generation time. This fact is known to be the cause of privacy and related (e.g., copyright) problems. Unlearning in LLMs then takes the form of devising new algorithms that will properly deal with these side-effects of memorized data, while not hurting the model's utility. We offer a fresh perspective towards this goal, namely, that each textual sequence to be forgotten should be treated differently when being unlearned based on its degree of memorization within the LLM. We contribute a new metric for measuring unlearning quality, an adversarial attack showing that SOTA algorithms lacking this perspective fail for privacy, and two new unlearning methods based on Gradient Ascent and Task Arithmetic, respectively. A comprehensive performance evaluation across an extensive suite of NLP tasks then mapped the solution space, identifying the best solutions under different scales in model capacities and forget set sizes and quantified the gains of the new approaches.
5/7/2024

Rethinking Machine Unlearning for Large Language Models
Sijia Liu, Yuanshun Yao, Jinghan Jia, Stephen Casper, Nathalie Baracaldo, Peter Hase, Xiaojun Xu, Yuguang Yao, Hang Li, Kush R. Varshney, Mohit Bansal, Sanmi Koyejo, Yang Liu
0
0
We explore machine unlearning (MU) in the domain of large language models (LLMs), referred to as LLM unlearning. This initiative aims to eliminate undesirable data influence (e.g., sensitive or illegal information) and the associated model capabilities, while maintaining the integrity of essential knowledge generation and not affecting causally unrelated information. We envision LLM unlearning becoming a pivotal element in the life-cycle management of LLMs, potentially standing as an essential foundation for developing generative AI that is not only safe, secure, and trustworthy, but also resource-efficient without the need of full retraining. We navigate the unlearning landscape in LLMs from conceptual formulation, methodologies, metrics, and applications. In particular, we highlight the often-overlooked aspects of existing LLM unlearning research, e.g., unlearning scope, data-model interaction, and multifaceted efficacy assessment. We also draw connections between LLM unlearning and related areas such as model editing, influence functions, model explanation, adversarial training, and reinforcement learning. Furthermore, we outline an effective assessment framework for LLM unlearning and explore its applications in copyright and privacy safeguards and sociotechnical harm reduction.
4/8/2024

Machine Unlearning in Large Language Models
Saaketh Koundinya Gundavarapu, Shreya Agarwal, Arushi Arora, Chandana Thimmalapura Jagadeeshaiah
0
0
Machine unlearning, a novel area within artificial intelligence, focuses on addressing the challenge of selectively forgetting or reducing undesirable knowledge or behaviors in machine learning models, particularly in the context of large language models (LLMs). This paper introduces a methodology to align LLMs, such as Open Pre-trained Transformer Language Models, with ethical, privacy, and safety standards by leveraging the gradient ascent algorithm for knowledge unlearning. Our approach aims to selectively erase or modify learned information in LLMs, targeting harmful responses and copyrighted content. This paper presents a dual-pronged approach to enhance the ethical and safe behavior of large language models (LLMs) by addressing the issues of harmful responses and copyrighted content. To mitigate harmful responses, we applied gradient ascent on the PKU dataset, achieving a 75% reduction in harmful responses for Open Pre-trained Transformer Language Models (OPT1.3b and OPT2.7b) citet{zhang2022opt} while retaining previous knowledge using the TruthfulQA dataset citet{DBLP:journals/corr/abs-2109-07958}. For handling copyrighted content, we constructed a custom dataset based on the Lord of the Rings corpus and aligned LLMs (OPT1.3b and OPT2.7b) citet{zhang2022opt} through LoRA: Low-Rank Adaptation of Large Language Models citet{DBLP:journals/corr/abs-2106-09685} finetuning. Subsequently, we employed gradient ascent to unlearn the Lord of the Rings content, resulting in a remarkable reduction in the presence of copyrighted material. To maintain a diverse knowledge base, we utilized the Book Corpus dataset. Additionally, we propose a new evaluation technique for assessing the effectiveness of harmful unlearning.
5/27/2024

New!UnUnlearning: Unlearning is not sufficient for content regulation in advanced generative AI
Ilia Shumailov, Jamie Hayes, Eleni Triantafillou, Guillermo Ortiz-Jimenez, Nicolas Papernot, Matthew Jagielski, Itay Yona, Heidi Howard, Eugene Bagdasaryan
0
0
Exact unlearning was first introduced as a privacy mechanism that allowed a user to retract their data from machine learning models on request. Shortly after, inexact schemes were proposed to mitigate the impractical costs associated with exact unlearning. More recently unlearning is often discussed as an approach for removal of impermissible knowledge i.e. knowledge that the model should not possess such as unlicensed copyrighted, inaccurate, or malicious information. The promise is that if the model does not have a certain malicious capability, then it cannot be used for the associated malicious purpose. In this paper we revisit the paradigm in which unlearning is used for in Large Language Models (LLMs) and highlight an underlying inconsistency arising from in-context learning. Unlearning can be an effective control mechanism for the training phase, yet it does not prevent the model from performing an impermissible act during inference. We introduce a concept of ununlearning, where unlearned knowledge gets reintroduced in-context, effectively rendering the model capable of behaving as if it knows the forgotten knowledge. As a result, we argue that content filtering for impermissible knowledge will be required and even exact unlearning schemes are not enough for effective content regulation. We discuss feasibility of ununlearning for modern LLMs and examine broader implications.
7/2/2024