To Each (Textual Sequence) Its Own: Improving Memorized-Data Unlearning in Large Language Models
2405.03097
0
0
💬
Abstract
LLMs have been found to memorize training textual sequences and regurgitate verbatim said sequences during text generation time. This fact is known to be the cause of privacy and related (e.g., copyright) problems. Unlearning in LLMs then takes the form of devising new algorithms that will properly deal with these side-effects of memorized data, while not hurting the model's utility. We offer a fresh perspective towards this goal, namely, that each textual sequence to be forgotten should be treated differently when being unlearned based on its degree of memorization within the LLM. We contribute a new metric for measuring unlearning quality, an adversarial attack showing that SOTA algorithms lacking this perspective fail for privacy, and two new unlearning methods based on Gradient Ascent and Task Arithmetic, respectively. A comprehensive performance evaluation across an extensive suite of NLP tasks then mapped the solution space, identifying the best solutions under different scales in model capacities and forget set sizes and quantified the gains of the new approaches.
Create account to get full access
Overview
- Large language models (LLMs) can memorize and regurgitate verbatim training text, leading to privacy and copyright issues.
- Unlearning aims to devise new algorithms to address these side-effects while preserving the model's utility.
- This paper proposes a novel perspective: each textual sequence to be forgotten should be treated differently based on its degree of memorization.
- The paper introduces a new metric for measuring unlearning quality, an adversarial attack, and two new unlearning methods.
- A comprehensive performance evaluation across NLP tasks maps the solution space and quantifies the gains of the new approaches.
Plain English Explanation
Rethinking Machine Unlearning in Large Language Models explores the issue of LLMs memorizing and reproducing verbatim training text, which can lead to privacy and copyright problems. The researchers argue that previous "unlearning" approaches, which aim to remove this memorized information, have not been effective enough.
The key insight is that not all memorized text is equally important to forget. Some sequences may be more deeply embedded in the model than others. The paper proposes treating each piece of text differently during the unlearning process, based on how much the model has memorized it.
The researchers introduce a new way to measure how well unlearning is working, as well as two new unlearning methods. One method uses a technique called "gradient ascent," while the other relies on "task arithmetic." The paper then evaluates these approaches across a wide range of language tasks to see how they perform under different conditions, like varying model sizes and amounts of text to be forgotten.
The goal is to find better solutions for removing unwanted memorized information from LLMs without compromising their overall usefulness. This is an important problem to solve as these models become more prevalent and influential.
Technical Explanation
Rethinking Machine Unlearning in Large Language Models addresses the issue of LLMs memorizing and reproducing verbatim training text, which can lead to privacy and copyright infringement. The researchers argue that previous "unlearning" approaches, which aim to remove this memorized information, have not been effective enough.
The key innovation is the insight that not all memorized text is equally important to forget. Some sequences may be more deeply embedded in the model than others. The paper proposes a new perspective where each piece of text to be forgotten is treated differently during the unlearning process, based on its degree of memorization.
The researchers introduce a new metric for measuring unlearning quality, which they use to evaluate an adversarial attack showing that state-of-the-art unlearning algorithms can fail to protect privacy. They then present two new unlearning methods: one based on Gradient Ascent and another on Task Arithmetic.
A comprehensive performance evaluation across an extensive suite of NLP tasks is used to map the solution space and quantify the gains of the new approaches. The results identify the best unlearning solutions under different scales in model capacities and forget set sizes.
Critical Analysis
Rethinking Machine Unlearning in Large Language Models makes a compelling case for the need to treat memorized text differently during the unlearning process. The proposed perspective and new techniques are a promising step forward in addressing the privacy and copyright issues caused by LLM memorization.
However, the paper does not fully explore the potential limitations or edge cases of the new methods. For example, it is unclear how the approaches would scale to extremely large language models or forget sets. Additionally, the paper does not address potential issues around the stability or robustness of the unlearning process.
Further research is needed to understand the broader implications and applicability of these techniques. Specifically, it would be valuable to see how they perform on real-world datasets and use cases, and to explore any trade-offs or unintended consequences that may arise.
Overall, this work represents an important contribution to the field of machine unlearning and document classification. The insights around differentiating memorized text could have broader applications beyond just LLMs, such as in the areas of tabular data and catastrophic forgetting.
Conclusion
Rethinking Machine Unlearning in Large Language Models presents a novel perspective on addressing the privacy and copyright issues caused by LLMs memorizing and reproducing verbatim training text. The key insight is that not all memorized text is equally important to forget, and the paper proposes treating each sequence differently based on its degree of memorization.
The researchers introduce new metrics, attack methods, and unlearning techniques to tackle this problem. Their comprehensive evaluation shows the potential of these approaches to identify better solutions for removing unwanted memorized information while preserving the overall utility of LLMs.
This work represents an important step forward in the field of machine unlearning and has broader implications for how we manage and protect sensitive data in the age of increasingly powerful language models. As these models become more ubiquitous, developing effective unlearning strategies will only become more crucial for maintaining privacy, security, and ethical AI development.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
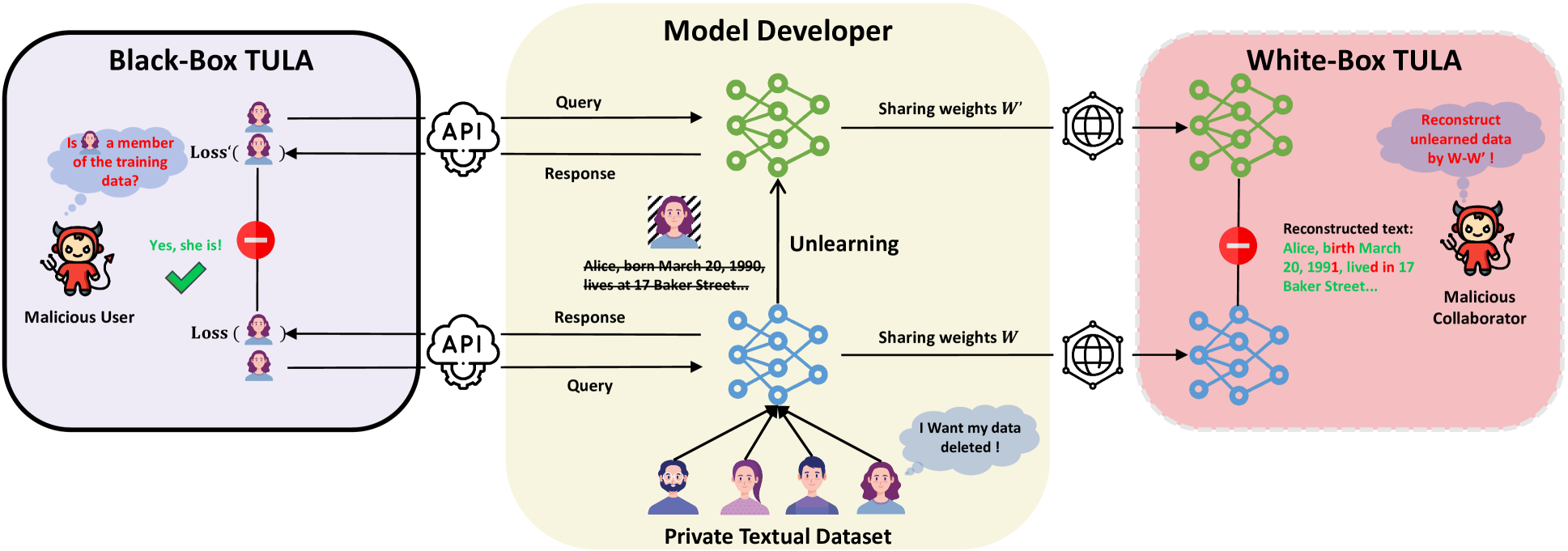
Textual Unlearning Gives a False Sense of Unlearning
Jiacheng Du, Zhibo Wang, Kui Ren
0
0
Language models (LMs) are susceptible to memorizing training data, including a large amount of private or copyright-protected content. To safeguard the right to be forgotten (RTBF), machine unlearning has emerged as a promising method for LMs to efficiently forget sensitive training content and mitigate knowledge leakage risks. However, despite its good intentions, could the unlearning mechanism be counterproductive? In this paper, we propose the Textual Unlearning Leakage Attack (TULA), where an adversary can infer information about the unlearned data only by accessing the models before and after unlearning. Furthermore, we present variants of TULA in both black-box and white-box scenarios. Through various experimental results, we critically demonstrate that machine unlearning amplifies the risk of knowledge leakage from LMs. Specifically, TULA can increase an adversary's ability to infer membership information about the unlearned data by more than 20% in black-box scenario. Moreover, TULA can even reconstruct the unlearned data directly with more than 60% accuracy with white-box access. Our work is the first to reveal that machine unlearning in LMs can inversely create greater knowledge risks and inspire the development of more secure unlearning mechanisms.
6/21/2024

Avoiding Copyright Infringement via Machine Unlearning
Guangyao Dou, Zheyuan Liu, Qing Lyu, Kaize Ding, Eric Wong
0
0
Pre-trained Large Language Models (LLMs) have demonstrated remarkable capabilities but also pose risks by learning and generating copyrighted material, leading to significant legal and ethical concerns. To address these issues, it is critical for model owners to be able to unlearn copyrighted content at various time steps. We explore the setting of sequential unlearning, where copyrighted content is removed over multiple time steps - a scenario that has not been rigorously addressed. To tackle this challenge, we propose Stable Sequential Unlearning (SSU), a novel unlearning framework for LLMs, designed to have a more stable process to remove copyrighted content from LLMs throughout different time steps using task vectors, by incorporating additional random labeling loss and applying gradient-based weight saliency mapping. Experiments demonstrate that SSU finds a good balance between unlearning efficacy and maintaining the model's general knowledge compared to existing baselines.
6/18/2024

Machine Unlearning in Large Language Models
Saaketh Koundinya Gundavarapu, Shreya Agarwal, Arushi Arora, Chandana Thimmalapura Jagadeeshaiah
0
0
Machine unlearning, a novel area within artificial intelligence, focuses on addressing the challenge of selectively forgetting or reducing undesirable knowledge or behaviors in machine learning models, particularly in the context of large language models (LLMs). This paper introduces a methodology to align LLMs, such as Open Pre-trained Transformer Language Models, with ethical, privacy, and safety standards by leveraging the gradient ascent algorithm for knowledge unlearning. Our approach aims to selectively erase or modify learned information in LLMs, targeting harmful responses and copyrighted content. This paper presents a dual-pronged approach to enhance the ethical and safe behavior of large language models (LLMs) by addressing the issues of harmful responses and copyrighted content. To mitigate harmful responses, we applied gradient ascent on the PKU dataset, achieving a 75% reduction in harmful responses for Open Pre-trained Transformer Language Models (OPT1.3b and OPT2.7b) citet{zhang2022opt} while retaining previous knowledge using the TruthfulQA dataset citet{DBLP:journals/corr/abs-2109-07958}. For handling copyrighted content, we constructed a custom dataset based on the Lord of the Rings corpus and aligned LLMs (OPT1.3b and OPT2.7b) citet{zhang2022opt} through LoRA: Low-Rank Adaptation of Large Language Models citet{DBLP:journals/corr/abs-2106-09685} finetuning. Subsequently, we employed gradient ascent to unlearn the Lord of the Rings content, resulting in a remarkable reduction in the presence of copyrighted material. To maintain a diverse knowledge base, we utilized the Book Corpus dataset. Additionally, we propose a new evaluation technique for assessing the effectiveness of harmful unlearning.
5/27/2024

Rethinking Machine Unlearning for Large Language Models
Sijia Liu, Yuanshun Yao, Jinghan Jia, Stephen Casper, Nathalie Baracaldo, Peter Hase, Xiaojun Xu, Yuguang Yao, Hang Li, Kush R. Varshney, Mohit Bansal, Sanmi Koyejo, Yang Liu
0
0
We explore machine unlearning (MU) in the domain of large language models (LLMs), referred to as LLM unlearning. This initiative aims to eliminate undesirable data influence (e.g., sensitive or illegal information) and the associated model capabilities, while maintaining the integrity of essential knowledge generation and not affecting causally unrelated information. We envision LLM unlearning becoming a pivotal element in the life-cycle management of LLMs, potentially standing as an essential foundation for developing generative AI that is not only safe, secure, and trustworthy, but also resource-efficient without the need of full retraining. We navigate the unlearning landscape in LLMs from conceptual formulation, methodologies, metrics, and applications. In particular, we highlight the often-overlooked aspects of existing LLM unlearning research, e.g., unlearning scope, data-model interaction, and multifaceted efficacy assessment. We also draw connections between LLM unlearning and related areas such as model editing, influence functions, model explanation, adversarial training, and reinforcement learning. Furthermore, we outline an effective assessment framework for LLM unlearning and explore its applications in copyright and privacy safeguards and sociotechnical harm reduction.
4/8/2024