ToNER: Type-oriented Named Entity Recognition with Generative Language Model
2404.09145
0
0

Abstract
In recent years, the fine-tuned generative models have been proven more powerful than the previous tagging-based or span-based models on named entity recognition (NER) task. It has also been found that the information related to entities, such as entity types, can prompt a model to achieve NER better. However, it is not easy to determine the entity types indeed existing in the given sentence in advance, and inputting too many potential entity types would distract the model inevitably. To exploit entity types' merit on promoting NER task, in this paper we propose a novel NER framework, namely ToNER based on a generative model. In ToNER, a type matching model is proposed at first to identify the entity types most likely to appear in the sentence. Then, we append a multiple binary classification task to fine-tune the generative model's encoder, so as to generate the refined representation of the input sentence. Moreover, we add an auxiliary task for the model to discover the entity types which further fine-tunes the model to output more accurate results. Our extensive experiments on some NER benchmarks verify the effectiveness of our proposed strategies in ToNER that are oriented towards entity types' exploitation.
Create account to get full access
Overview
- This paper presents ToNER, a type-oriented named entity recognition (NER) model that leverages a generative language model to improve NER performance.
- ToNER aims to address the limitations of traditional NER models by incorporating type information into the recognition process, resulting in more accurate and context-sensitive entity identification.
- The authors propose a novel type-oriented decoding strategy and demonstrate the effectiveness of their approach on several benchmark NER datasets.
Plain English Explanation
Named entity recognition (NER) is the process of identifying and classifying important words or phrases in text, such as people, organizations, locations, and other entities. Traditional NER models often struggle to accurately recognize entities, especially in complex or ambiguous contexts.
The ToNER model proposed in this paper tries to address these limitations by incorporating information about the "type" of entity being recognized. For example, instead of just identifying a word as a "person", ToNER would also recognize the specific type of person, such as an actor, politician, or scientist.
By considering entity types during the recognition process, ToNER can make more informed and context-sensitive decisions about which words or phrases represent meaningful entities. This type-oriented approach allows the model to better understand the relationships between different entities and their roles within the text.
The researchers demonstrate that ToNER outperforms traditional NER models on several common benchmark datasets, indicating that the type-oriented approach can lead to significant improvements in entity recognition accuracy.
Technical Explanation
The key innovation in the ToNER model is the incorporation of type information into the named entity recognition process. Traditional NER models typically use a sequence labeling approach, where each word in the input text is assigned a label (such as "person", "organization", or "location"). ToNER, on the other hand, takes a type-oriented approach, where the model first predicts the type of entity and then generates the corresponding text.
To achieve this, ToNER uses a generative language model as its foundation. The model is trained on a large corpus of text data, which allows it to learn the patterns and relationships between different entity types and their associated text. During inference, ToNER first predicts the type of entity, and then generates the corresponding text using the language model.
The authors propose a novel type-oriented decoding strategy that guides the language model to generate entity text that is consistent with the predicted entity type. This approach helps to ensure that the generated entities are both accurate and contextually appropriate.
The researchers evaluate ToNER on several benchmark NER datasets, including [internal link: https://aimodels.fyi/papers/arxiv/ltner-large-language-model-tagging-named-entity], [internal link: https://aimodels.fyi/papers/arxiv/intent-detection-entity-extraction-from-biomedical-literature], and [internal link: https://aimodels.fyi/papers/arxiv/hybrid-multi-stage-decoding-few-shot-ner]. The results show that ToNER outperforms traditional NER models, particularly in scenarios where the entities are more complex or ambiguous.
Critical Analysis
The ToNER model represents a promising approach to improving named entity recognition by incorporating type information into the recognition process. The type-oriented decoding strategy is a novel and intriguing concept that could have broader applications beyond NER tasks.
However, the paper does not deeply address the potential limitations or challenges of the ToNER model. For example, the authors do not discuss how the model might perform on more specialized or domain-specific datasets, or how it might handle rare or novel entity types.
Additionally, the paper would benefit from a more thorough discussion of the tradeoffs and potential downsides of the type-oriented approach. While the results are promising, it's important to consider whether the added complexity of the model might outweigh the performance gains in certain scenarios.
Further research could also explore the interpretability and explainability of the ToNER model, as understanding the reasoning behind the type predictions and text generation could be valuable for practical applications. [internal link: https://aimodels.fyi/papers/arxiv/scanner-knowledge-enhanced-approach-robust-multi-modal], [internal link: https://aimodels.fyi/papers/arxiv/few-shot-name-entity-recognition-stackoverflow]
Conclusion
The ToNER model presented in this paper represents a significant advancement in named entity recognition by incorporating type information into the recognition process. The type-oriented decoding strategy allows the model to make more informed and contextual decisions about the entities present in text, leading to improved accuracy and performance.
While the paper does not address all potential limitations, the core idea behind ToNER is compelling and could have far-reaching implications for natural language processing tasks beyond just NER. As the field of AI continues to advance, incorporating more semantic and contextual information into language models will likely be a key area of research and development.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Fighting Against the Repetitive Training and Sample Dependency Problem in Few-shot Named Entity Recognition
Chang Tian, Wenpeng Yin, Dan Li, Marie-Francine Moens
0
0
Few-shot named entity recognition (NER) systems recognize entities using a few labeled training examples. The general pipeline consists of a span detector to identify entity spans in text and an entity-type classifier to assign types to entities. Current span detectors rely on extensive manual labeling to guide training. Almost every span detector requires initial training on basic span features followed by adaptation to task-specific features. This process leads to repetitive training of the basic span features among span detectors. Additionally, metric-based entity-type classifiers, such as prototypical networks, typically employ a specific metric that gauges the distance between the query sample and entity-type referents, ultimately assigning the most probable entity type to the query sample. However, these classifiers encounter the sample dependency problem, primarily stemming from the limited samples available for each entity-type referent. To address these challenges, we proposed an improved few-shot NER pipeline. First, we introduce a steppingstone span detector that is pre-trained on open-domain Wikipedia data. It can be used to initialize the pipeline span detector to reduce the repetitive training of basic features. Second, we leverage a large language model (LLM) to set reliable entity-type referents, eliminating reliance on few-shot samples of each type. Our model exhibits superior performance with fewer training steps and human-labeled data compared with baselines, as demonstrated through extensive experiments on various datasets. Particularly in fine-grained few-shot NER settings, our model outperforms strong baselines, including ChatGPT. We will publicly release the code, datasets, LLM outputs, and model checkpoints.
6/21/2024
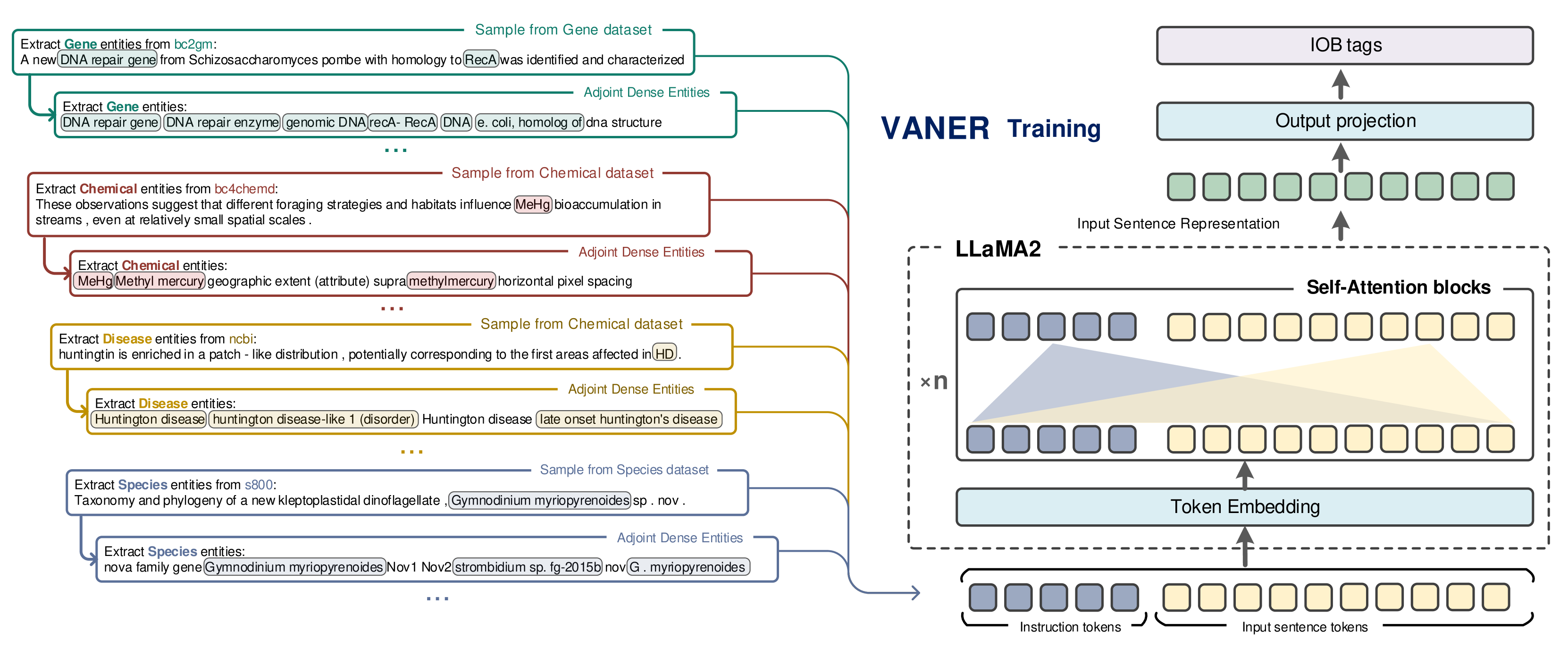
VANER: Leveraging Large Language Model for Versatile and Adaptive Biomedical Named Entity Recognition
Junyi Biana, Weiqi Zhai, Xiaodi Huang, Jiaxuan Zheng, Shanfeng Zhu
0
0
Prevalent solution for BioNER involves using representation learning techniques coupled with sequence labeling. However, such methods are inherently task-specific, demonstrate poor generalizability, and often require dedicated model for each dataset. To leverage the versatile capabilities of recently remarkable large language models (LLMs), several endeavors have explored generative approaches to entity extraction. Yet, these approaches often fall short of the effectiveness of previouly sequence labeling approaches. In this paper, we utilize the open-sourced LLM LLaMA2 as the backbone model, and design specific instructions to distinguish between different types of entities and datasets. By combining the LLM's understanding of instructions with sequence labeling techniques, we use mix of datasets to train a model capable of extracting various types of entities. Given that the backbone LLMs lacks specialized medical knowledge, we also integrate external entity knowledge bases and employ instruction tuning to compel the model to densely recognize carefully curated entities. Our model VANER, trained with a small partition of parameters, significantly outperforms previous LLMs-based models and, for the first time, as a model based on LLM, surpasses the majority of conventional state-of-the-art BioNER systems, achieving the highest F1 scores across three datasets.
4/30/2024
📈
Annotation Errors and NER: A Study with OntoNotes 5.0
Gabriel Bernier-Colborne, Sowmya Vajjala
0
0
Named Entity Recognition (NER) is a well-studied problem in NLP. However, there is much less focus on studying NER datasets, compared to developing new NER models. In this paper, we employed three simple techniques to detect annotation errors in the OntoNotes 5.0 corpus for English NER, which is the largest available NER corpus for English. Our techniques corrected ~10% of the sentences in train/dev/test data. In terms of entity mentions, we corrected the span and/or type of ~8% of mentions in the dataset, while adding/deleting/splitting/merging a few more. These are large numbers of changes, considering the size of OntoNotes. We used three NER libraries to train, evaluate and compare the models trained with the original and the re-annotated datasets, which showed an average improvement of 1.23% in overall F-scores, with large (>10%) improvements for some of the entity types. While our annotation error detection methods are not exhaustive and there is some manual annotation effort involved, they are largely language agnostic and can be employed with other NER datasets, and other sequence labelling tasks.
6/28/2024
💬
2M-NER: Contrastive Learning for Multilingual and Multimodal NER with Language and Modal Fusion
Dongsheng Wang, Xiaoqin Feng, Zeming Liu, Chuan Wang
0
0
Named entity recognition (NER) is a fundamental task in natural language processing that involves identifying and classifying entities in sentences into pre-defined types. It plays a crucial role in various research fields, including entity linking, question answering, and online product recommendation. Recent studies have shown that incorporating multilingual and multimodal datasets can enhance the effectiveness of NER. This is due to language transfer learning and the presence of shared implicit features across different modalities. However, the lack of a dataset that combines multilingualism and multimodality has hindered research exploring the combination of these two aspects, as multimodality can help NER in multiple languages simultaneously. In this paper, we aim to address a more challenging task: multilingual and multimodal named entity recognition (MMNER), considering its potential value and influence. Specifically, we construct a large-scale MMNER dataset with four languages (English, French, German and Spanish) and two modalities (text and image). To tackle this challenging MMNER task on the dataset, we introduce a new model called 2M-NER, which aligns the text and image representations using contrastive learning and integrates a multimodal collaboration module to effectively depict the interactions between the two modalities. Extensive experimental results demonstrate that our model achieves the highest F1 score in multilingual and multimodal NER tasks compared to some comparative and representative baselines. Additionally, in a challenging analysis, we discovered that sentence-level alignment interferes a lot with NER models, indicating the higher level of difficulty in our dataset.
4/29/2024