Annotation Errors and NER: A Study with OntoNotes 5.0
2406.19172
0
0
📈
Abstract
Named Entity Recognition (NER) is a well-studied problem in NLP. However, there is much less focus on studying NER datasets, compared to developing new NER models. In this paper, we employed three simple techniques to detect annotation errors in the OntoNotes 5.0 corpus for English NER, which is the largest available NER corpus for English. Our techniques corrected ~10% of the sentences in train/dev/test data. In terms of entity mentions, we corrected the span and/or type of ~8% of mentions in the dataset, while adding/deleting/splitting/merging a few more. These are large numbers of changes, considering the size of OntoNotes. We used three NER libraries to train, evaluate and compare the models trained with the original and the re-annotated datasets, which showed an average improvement of 1.23% in overall F-scores, with large (>10%) improvements for some of the entity types. While our annotation error detection methods are not exhaustive and there is some manual annotation effort involved, they are largely language agnostic and can be employed with other NER datasets, and other sequence labelling tasks.
Create account to get full access
Overview
- This paper investigates annotation errors in Named Entity Recognition (NER) systems, using the OntoNotes 5.0 dataset as a case study.
- The researchers aim to understand the nature and prevalence of different types of annotation errors, and how they impact NER model performance.
- The findings from this study can help improve the quality of NER datasets and the robustness of NER models.
Plain English Explanation
The paper examines the errors that can occur when labeling and classifying named entities in text, using a popular dataset called OntoNotes 5.0 as an example. Named entities are things like people, organizations, locations, and other proper nouns that are important for understanding the meaning of a piece of text.
The researchers looked at what kinds of mistakes are commonly made when annotating or labeling these named entities, and how those errors affect the performance of natural language processing models that are trained to recognize named entities. By understanding the nature and prevalence of these annotation errors, the goal is to improve the quality of named entity datasets and make the models that use them more accurate and reliable.
This is an important task because named entity recognition is a fundamental building block for many language understanding applications, from search engines to question-answering systems. If the training data has errors, it can lead to models that make mistakes in the real world. By identifying and addressing these issues, the research can help create better natural language processing systems.
Technical Explanation
The paper presents a fine-grained error analysis of named entity recognition (NER) systems using the OntoNotes 5.0 dataset. The researchers manually annotated a subset of the OntoNotes 5.0 dataset to identify different types of annotation errors, such as missing entities, incorrect entity boundaries, and entity type confusions.
They then trained a state-of-the-art NER model on the original and corrected versions of the dataset, and analyzed the model's performance on each type of error. The results show that certain error types, like incorrect boundaries, have a larger impact on model performance than others, like missing entities.
The paper also discusses strategies for augmenting NER datasets to address these issues, such as using large language models to automatically identify and correct annotation errors. Additionally, the researchers introduce a new multilingual speech dataset for NER, which can help assess the generalization of NER models across different languages and modalities.
Critical Analysis
The paper provides a valuable contribution to the understanding of annotation errors in NER datasets and their impact on model performance. The fine-grained analysis of different error types and their relative importance is a strength of the work.
However, the paper does not discuss the potential limitations of the manual annotation process used to identify errors, which could introduce its own biases or inconsistencies. Additionally, the evaluation is limited to the OntoNotes 5.0 dataset, and it would be interesting to see how the findings generalize to other NER datasets, especially those in different languages.
The proposed strategies for dataset augmentation and the introduction of the multilingual speech dataset are promising directions, but more research is needed to fully validate their effectiveness in improving NER model robustness and generalization.
Conclusion
This paper provides a detailed analysis of annotation errors in named entity recognition datasets, using the OntoNotes 5.0 corpus as a case study. The researchers identified various types of errors and quantified their impact on NER model performance. The insights from this work can inform the development of more robust and reliable named entity recognition systems, which are crucial for many natural language processing applications.
By understanding the nature and prevalence of annotation errors, researchers and practitioners can work to improve the quality of training data and, in turn, the performance of NER models in real-world settings. This is an important step towards building more accurate and trustworthy language understanding technologies.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🔎
CoNLL#: Fine-grained Error Analysis and a Corrected Test Set for CoNLL-03 English
Andrew Rueda, Elena 'Alvarez Mellado, Constantine Lignos
0
0
Modern named entity recognition systems have steadily improved performance in the age of larger and more powerful neural models. However, over the past several years, the state-of-the-art has seemingly hit another plateau on the benchmark CoNLL-03 English dataset. In this paper, we perform a deep dive into the test outputs of the highest-performing NER models, conducting a fine-grained evaluation of their performance by introducing new document-level annotations on the test set. We go beyond F1 scores by categorizing errors in order to interpret the true state of the art for NER and guide future work. We review previous attempts at correcting the various flaws of the test set and introduce CoNLL#, a new corrected version of the test set that addresses its systematic and most prevalent errors, allowing for low-noise, interpretable error analysis.
5/21/2024

ToNER: Type-oriented Named Entity Recognition with Generative Language Model
Guochao Jiang, Ziqin Luo, Yuchen Shi, Dixuan Wang, Jiaqing Liang, Deqing Yang
0
0
In recent years, the fine-tuned generative models have been proven more powerful than the previous tagging-based or span-based models on named entity recognition (NER) task. It has also been found that the information related to entities, such as entity types, can prompt a model to achieve NER better. However, it is not easy to determine the entity types indeed existing in the given sentence in advance, and inputting too many potential entity types would distract the model inevitably. To exploit entity types' merit on promoting NER task, in this paper we propose a novel NER framework, namely ToNER based on a generative model. In ToNER, a type matching model is proposed at first to identify the entity types most likely to appear in the sentence. Then, we append a multiple binary classification task to fine-tune the generative model's encoder, so as to generate the refined representation of the input sentence. Moreover, we add an auxiliary task for the model to discover the entity types which further fine-tunes the model to output more accurate results. Our extensive experiments on some NER benchmarks verify the effectiveness of our proposed strategies in ToNER that are oriented towards entity types' exploitation.
6/12/2024
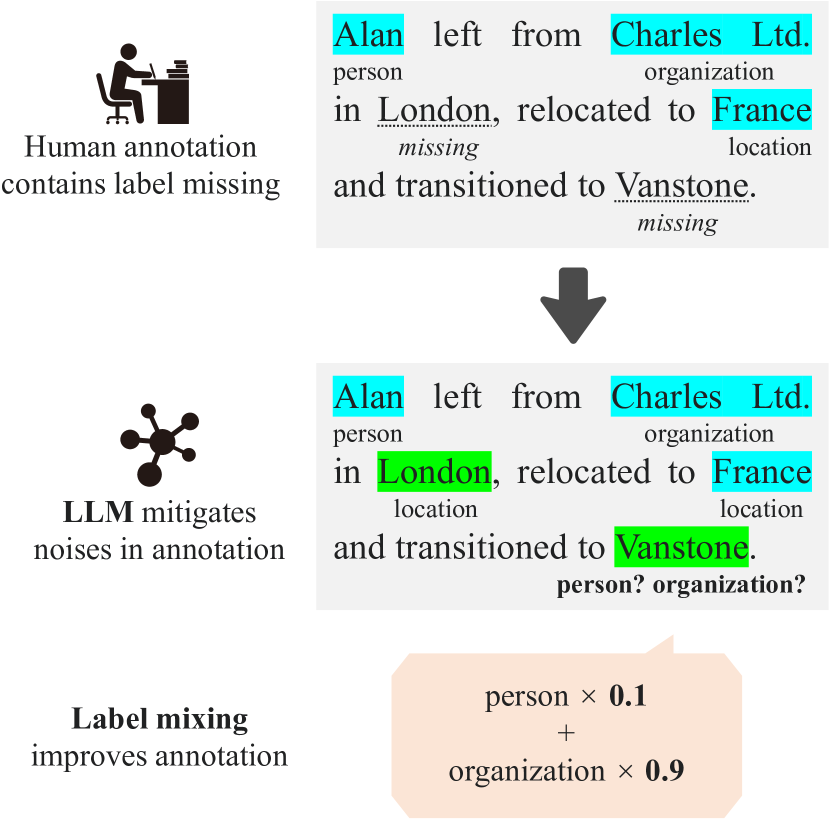
Augmenting NER Datasets with LLMs: Towards Automated and Refined Annotation
Yuji Naraki, Ryosuke Yamaki, Yoshikazu Ikeda, Takafumi Horie, Hiroki Naganuma
0
0
In the field of Natural Language Processing (NLP), Named Entity Recognition (NER) is recognized as a critical technology, employed across a wide array of applications. Traditional methodologies for annotating datasets for NER models are challenged by high costs and variations in dataset quality. This research introduces a novel hybrid annotation approach that synergizes human effort with the capabilities of Large Language Models (LLMs). This approach not only aims to ameliorate the noise inherent in manual annotations, such as omissions, thereby enhancing the performance of NER models, but also achieves this in a cost-effective manner. Additionally, by employing a label mixing strategy, it addresses the issue of class imbalance encountered in LLM-based annotations. Through an analysis across multiple datasets, this method has been consistently shown to provide superior performance compared to traditional annotation methods, even under constrained budget conditions. This study illuminates the potential of leveraging LLMs to improve dataset quality, introduces a novel technique to mitigate class imbalances, and demonstrates the feasibility of achieving high-performance NER in a cost-effective way.
4/3/2024

MSNER: A Multilingual Speech Dataset for Named Entity Recognition
Quentin Meeus, Marie-Francine Moens, Hugo Van hamme
0
0
While extensively explored in text-based tasks, Named Entity Recognition (NER) remains largely neglected in spoken language understanding. Existing resources are limited to a single, English-only dataset. This paper addresses this gap by introducing MSNER, a freely available, multilingual speech corpus annotated with named entities. It provides annotations to the VoxPopuli dataset in four languages (Dutch, French, German, and Spanish). We have also releasing an efficient annotation tool that leverages automatic pre-annotations for faster manual refinement. This results in 590 and 15 hours of silver-annotated speech for training and validation, alongside a 17-hour, manually-annotated evaluation set. We further provide an analysis comparing silver and gold annotations. Finally, we present baseline NER models to stimulate further research on this newly available dataset.
5/21/2024