A Toolkit for Joint Speaker Diarization and Identification with Application to Speaker-Attributed ASR

0

Sign in to get full access
Overview
- This paper presents a toolkit for jointly performing speaker diarization and identification.
- The toolkit is designed to be used in speaker-attributed automatic speech recognition (ASR) applications.
- The system architecture includes components for speaker diarization, speaker identification, and speaker-attributed ASR.
- The toolkit is evaluated on various datasets and shown to outperform existing approaches.
Plain English Explanation
The paper describes a software toolkit that can [object Object] different speakers in an audio recording and [object Object] which parts of the recording belong to each speaker. This is known as speaker diarization. The toolkit can then [object Object] the recognized speech to the correct speaker, which is useful for speaker-attributed automatic speech recognition (ASR).
The toolkit has several components that work together to accomplish these tasks. First, it analyzes the audio to identify distinct speakers and the parts of the recording where each speaker is talking. Then, it matches each speaker's voice to a specific identity, so it knows which parts of the recording belong to which person. Finally, it takes the recognized speech and associates it with the correct speaker.
The researchers tested the toolkit on different datasets and found that it outperforms existing approaches for these speaker-related tasks. This could be useful for applications like [object Object] or [object Object], where it's important to know which person is saying what.
Technical Explanation
The paper describes a toolkit for joint speaker diarization and identification, with a focus on application to speaker-attributed automatic speech recognition (ASR). The system architecture consists of three main components:
- Speaker Diarization: This component analyzes the input audio to identify distinct speakers and the segments where each speaker is talking.
- Speaker Identification: This component matches the speaker segments to specific speaker identities, allowing the recognized speech to be attributed to the correct person.
- Speaker-Attributed ASR: This component takes the speaker diarization and identification results and associates the recognized speech with the correct speaker.
The authors evaluate the toolkit on various datasets, including meeting recordings and telephone conversations. They show that the joint diarization and identification approach outperforms existing sequential methods, leading to more accurate speaker-attributed ASR.
Critical Analysis
The paper presents a comprehensive toolkit for speaker-related tasks, and the authors have carefully evaluated its performance on multiple datasets. However, the paper does not discuss potential limitations or areas for future research.
One potential limitation could be the toolkit's performance on more challenging audio scenarios, such as overlapping speech, accented speech, or audio with background noise. The authors could have explored the system's robustness to these types of conditions.
Additionally, the paper does not mention the computational requirements or real-time processing capabilities of the toolkit. This information would be useful for understanding the practical deployment considerations.
Further research could explore ways to improve the toolkit's accuracy, efficiency, or generalization to a wider range of applications. The authors could also investigate the integration of the toolkit with other speech processing or natural language understanding components to enable more advanced applications.
Conclusion
This paper introduces a powerful toolkit for joint speaker diarization and identification, with a focus on improving speaker-attributed ASR. The toolkit's modular architecture and strong performance on various datasets suggest it could be a valuable tool for applications that require accurate speaker information, such as meeting transcription, call center analysis, and human-computer interaction. While the paper does not discuss all potential limitations, it represents an important contribution to the field of speaker-related speech processing.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
A Toolkit for Joint Speaker Diarization and Identification with Application to Speaker-Attributed ASR
Giovanni Morrone, Enrico Zovato, Fabio Brugnara, Enrico Sartori, Leonardo Badino
We present a modular toolkit to perform joint speaker diarization and speaker identification. The toolkit can leverage on multiple models and algorithms which are defined in a configuration file. Such flexibility allows our system to work properly in various conditions (e.g., multiple registered speakers' sets, acoustic conditions and languages) and across application domains (e.g. media monitoring, institutional, speech analytics). In this demonstration we show a practical use-case in which speaker-related information is used jointly with automatic speech recognition engines to generate speaker-attributed transcriptions. To achieve that, we employ a user-friendly web-based interface to process audio and video inputs with the chosen configuration.
Read more9/10/2024

0
3D-Speaker-Toolkit: An Open Source Toolkit for Multi-modal Speaker Verification and Diarization
Yafeng Chen, Siqi Zheng, Hui Wang, Luyao Cheng, Tinglong Zhu, Rongjie Huang, Chong Deng, Qian Chen, Shiliang Zhang, Wen Wang, Xihao Li
We introduce 3D-Speaker-Toolkit, an open-source toolkit for multimodal speaker verification and diarization, designed for meeting the needs of academic researchers and industrial practitioners. The 3D-Speaker-Toolkit adeptly leverages the combined strengths of acoustic, semantic, and visual data, seamlessly fusing these modalities to offer robust speaker recognition capabilities. The acoustic module extracts speaker embeddings from acoustic features, employing both fully-supervised and self-supervised learning approaches. The semantic module leverages advanced language models to comprehend the substance and context of spoken language, thereby augmenting the system's proficiency in distinguishing speakers through linguistic patterns. The visual module applies image processing technologies to scrutinize facial features, which bolsters the precision of speaker diarization in multi-speaker environments. Collectively, these modules empower the 3D-Speaker-Toolkit to achieve substantially improved accuracy and reliability in speaker-related tasks. With 3D-Speaker-Toolkit, we establish a new benchmark for multimodal speaker analysis. The toolkit also includes a handful of open-source state-of-the-art models and a large-scale dataset containing over 10,000 speakers. The toolkit is publicly available at https://github.com/modelscope/3D-Speaker.
Read more9/18/2024
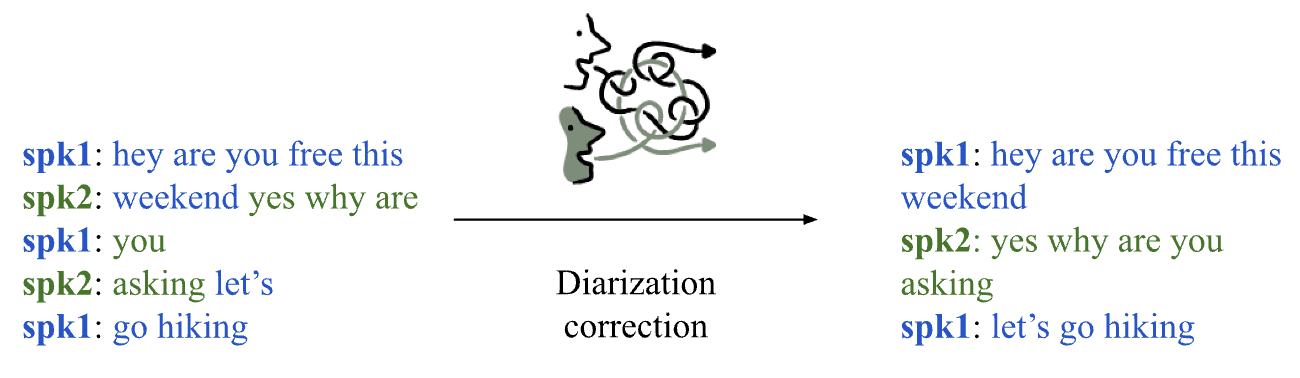
0
LLM-based speaker diarization correction: A generalizable approach
Georgios Efstathiadis, Vijay Yadav, Anzar Abbas
Speaker diarization is necessary for interpreting conversations transcribed using automated speech recognition (ASR) tools. Despite significant developments in diarization methods, diarization accuracy remains an issue. Here, we investigate the use of large language models (LLMs) for diarization correction as a post-processing step. LLMs were fine-tuned using the Fisher corpus, a large dataset of transcribed conversations. The ability of the models to improve diarization accuracy in a holdout dataset from the Fisher corpus as well as an independent dataset was measured. We report that fine-tuned LLMs can markedly improve diarization accuracy. However, model performance is constrained to transcripts produced using the same ASR tool as the transcripts used for fine-tuning, limiting generalizability. To address this constraint, an ensemble model was developed by combining weights from three separate models, each fine-tuned using transcripts from a different ASR tool. The ensemble model demonstrated better overall performance than each of the ASR-specific models, suggesting that a generalizable and ASR-agnostic approach may be achievable. We have made the weights of these models publicly available on HuggingFace at https://huggingface.co/bklynhlth.
Read more9/17/2024

0
Improving Speaker Assignment in Speaker-Attributed ASR for Real Meeting Applications
Can Cui (MULTISPEECH), Imran Ahamad Sheikh (MULTISPEECH), Mostafa Sadeghi (MULTISPEECH), Emmanuel Vincent (MULTISPEECH)
Past studies on end-to-end meeting transcription have focused on model architecture and have mostly been evaluated on simulated meeting data. We present a novel study aiming to optimize the use of a Speaker-Attributed ASR (SA-ASR) system in real-life scenarios, such as the AMI meeting corpus, for improved speaker assignment of speech segments. First, we propose a pipeline tailored to real-life applications involving Voice Activity Detection (VAD), Speaker Diarization (SD), and SA-ASR. Second, we advocate using VAD output segments to fine-tune the SA-ASR model, considering that it is also applied to VAD segments during test, and show that this results in a relative reduction of Speaker Error Rate (SER) up to 28%. Finally, we explore strategies to enhance the extraction of the speaker embedding templates used as inputs by the SA-ASR system. We show that extracting them from SD output rather than annotated speaker segments results in a relative SER reduction up to 20%.
Read more9/6/2024