TorchGT: A Holistic System for Large-scale Graph Transformer Training

0

Sign in to get full access
Overview
- TorchGT is a holistic system for large-scale graph transformer training.
- It provides a comprehensive solution for efficiently training graph transformer models on large-scale datasets.
Plain English Explanation
TorchGT: A Holistic System for Large-scale Graph Transformer Training is a research paper that presents a system called TorchGT, which is designed to make it easier and more efficient to train graph transformer models on large datasets.
Graph Transformers: Graph transformers are a type of deep learning model that can effectively capture the complex relationships and patterns in graph-structured data, such as social networks, biological networks, or transportation networks. However, training these models on large-scale graphs can be computationally intensive and challenging.
TorchGT System: The TorchGT system aims to address these challenges by providing a comprehensive solution for large-scale graph transformer training. It includes several key components:
-
Efficient Graph Representation: TorchGT uses a novel graph representation that can efficiently store and manipulate large-scale graph data, enabling faster training and inference.
-
Parallelized Training: The system leverages parallel computing resources, such as GPUs, to speed up the training process, allowing for faster model development and experimentation.
-
Optimized Memory Management: TorchGT includes advanced memory management techniques to reduce the memory footprint of the training process, making it possible to train larger models on limited hardware resources.
-
Seamless Integration: The system is designed to seamlessly integrate with the popular PyTorch deep learning framework, allowing researchers and practitioners to easily incorporate graph transformers into their existing workflows.
By addressing these key challenges, the TorchGT system aims to make it easier for researchers and developers to work with large-scale graph data and train powerful graph transformer models more efficiently.
Technical Explanation
The TorchGT: A Holistic System for Large-scale Graph Transformer Training paper presents a comprehensive system for training graph transformer models on large-scale datasets.
Efficient Graph Representation: The authors introduce a novel graph representation that can efficiently store and manipulate large-scale graph data. This representation is designed to reduce memory usage and enable faster processing of graph data during training and inference.
Parallelized Training: The TorchGT system leverages parallel computing resources, such as GPUs, to speed up the training process. By distributing the training workload across multiple devices, the system can significantly reduce the time required to train graph transformer models, especially on large-scale datasets.
Optimized Memory Management: The paper describes advanced memory management techniques used in TorchGT to reduce the memory footprint of the training process. This allows the system to train larger models on limited hardware resources, expanding the range of graph transformer applications.
Seamless Integration: TorchGT is designed to seamlessly integrate with the PyTorch deep learning framework, making it easy for researchers and practitioners to incorporate graph transformers into their existing workflows. This integration simplifies the process of working with graph data and enables the use of graph transformers in a wide range of applications.
Critical Analysis
The TorchGT system presented in the paper addresses several key challenges in large-scale graph transformer training, and the proposed solutions seem promising. However, the paper does not provide a comprehensive evaluation of the system's performance compared to other existing approaches.
While the authors demonstrate the efficiency of TorchGT on various datasets, it would be helpful to see a more thorough comparison with other state-of-the-art graph transformer frameworks or alternative methods for large-scale graph processing. This would help readers better understand the relative strengths and weaknesses of the TorchGT system.
Additionally, the paper does not discuss potential limitations or caveats of the proposed system. It would be valuable to understand any scenarios or applications where TorchGT may not perform as well, or any known issues or trade-offs that users should be aware of.
Conclusion
The TorchGT: A Holistic System for Large-scale Graph Transformer Training paper presents a comprehensive system for efficiently training graph transformer models on large-scale datasets. By addressing key challenges in graph representation, parallel training, memory management, and framework integration, TorchGT aims to make it easier for researchers and practitioners to work with large-scale graph data and develop powerful graph-based models.
While the proposed solutions seem promising, a more thorough evaluation and discussion of potential limitations would strengthen the paper and provide readers with a more well-rounded understanding of the system's capabilities and trade-offs. Overall, the TorchGT system represents an important contribution to the field of large-scale graph transformer research and development.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
TorchGT: A Holistic System for Large-scale Graph Transformer Training
Meng Zhang, Jie Sun, Qinghao Hu, Peng Sun, Zeke Wang, Yonggang Wen, Tianwei Zhang
Graph Transformer is a new architecture that surpasses GNNs in graph learning. While there emerge inspiring algorithm advancements, their practical adoption is still limited, particularly on real-world graphs involving up to millions of nodes. We observe existing graph transformers fail on large-scale graphs mainly due to heavy computation, limited scalability and inferior model quality. Motivated by these observations, we propose TorchGT, the first efficient, scalable, and accurate graph transformer training system. TorchGT optimizes training at different levels. At algorithm level, by harnessing the graph sparsity, TorchGT introduces a Dual-interleaved Attention which is computation-efficient and accuracy-maintained. At runtime level, TorchGT scales training across workers with a communication-light Cluster-aware Graph Parallelism. At kernel level, an Elastic Computation Reformation further optimizes the computation by reducing memory access latency in a dynamic way. Extensive experiments demonstrate that TorchGT boosts training by up to 62.7x and supports graph sequence lengths of up to 1M.
Read more7/22/2024
📊
0
AnchorGT: Efficient and Flexible Attention Architecture for Scalable Graph Transformers
Wenhao Zhu, Guojie Song, Liang Wang, Shaoguo Liu
Graph Transformers (GTs) have significantly advanced the field of graph representation learning by overcoming the limitations of message-passing graph neural networks (GNNs) and demonstrating promising performance and expressive power. However, the quadratic complexity of self-attention mechanism in GTs has limited their scalability, and previous approaches to address this issue often suffer from expressiveness degradation or lack of versatility. To address this issue, we propose AnchorGT, a novel attention architecture for GTs with global receptive field and almost linear complexity, which serves as a flexible building block to improve the scalability of a wide range of GT models. Inspired by anchor-based GNNs, we employ structurally important $k$-dominating node set as anchors and design an attention mechanism that focuses on the relationship between individual nodes and anchors, while retaining the global receptive field for all nodes. With its intuitive design, AnchorGT can easily replace the attention module in various GT models with different network architectures and structural encodings, resulting in reduced computational overhead without sacrificing performance. In addition, we theoretically prove that AnchorGT attention can be strictly more expressive than Weisfeiler-Lehman test, showing its superiority in representing graph structures. Our experiments on three state-of-the-art GT models demonstrate that their AnchorGT variants can achieve better results while being faster and significantly more memory efficient.
Read more5/7/2024

0
Hypergraph Transformer for Semi-Supervised Classification
Zexi Liu, Bohan Tang, Ziyuan Ye, Xiaowen Dong, Siheng Chen, Yanfeng Wang
Hypergraphs play a pivotal role in the modelling of data featuring higher-order relations involving more than two entities. Hypergraph neural networks emerge as a powerful tool for processing hypergraph-structured data, delivering remarkable performance across various tasks, e.g., hypergraph node classification. However, these models struggle to capture global structural information due to their reliance on local message passing. To address this challenge, we propose a novel hypergraph learning framework, HyperGraph Transformer (HyperGT). HyperGT uses a Transformer-based neural network architecture to effectively consider global correlations among all nodes and hyperedges. To incorporate local structural information, HyperGT has two distinct designs: i) a positional encoding based on the hypergraph incidence matrix, offering valuable insights into node-node and hyperedge-hyperedge interactions; and ii) a hypergraph structure regularization in the loss function, capturing connectivities between nodes and hyperedges. Through these designs, HyperGT achieves comprehensive hypergraph representation learning by effectively incorporating global interactions while preserving local connectivity patterns. Extensive experiments conducted on real-world hypergraph node classification tasks showcase that HyperGT consistently outperforms existing methods, establishing new state-of-the-art benchmarks. Ablation studies affirm the effectiveness of the individual designs of our model.
Read more6/4/2024
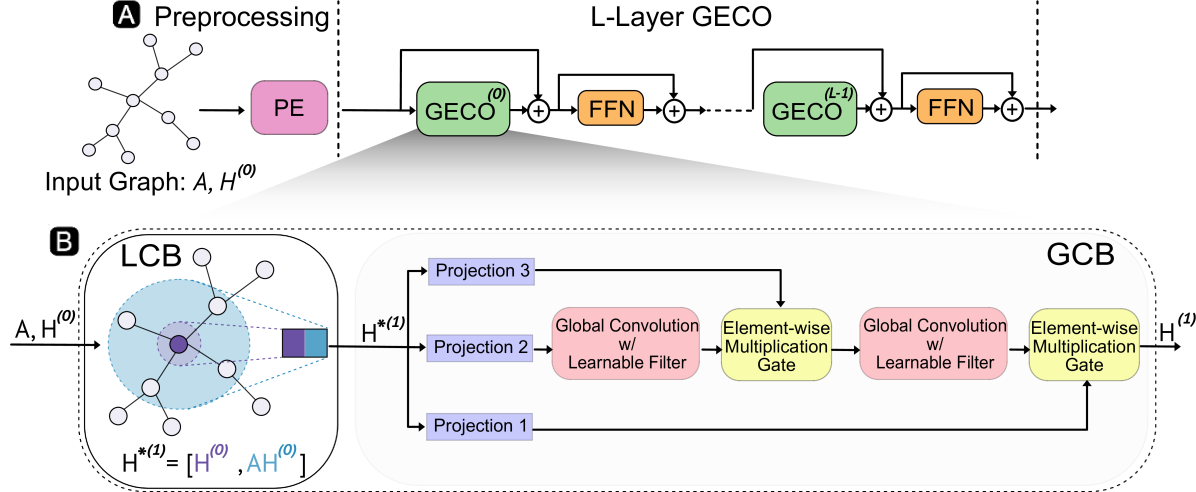
0
A Scalable and Effective Alternative to Graph Transformers
Kaan Sancak, Zhigang Hua, Jin Fang, Yan Xie, Andrey Malevich, Bo Long, Muhammed Fatih Balin, Umit V. c{C}atalyurek
Graph Neural Networks (GNNs) have shown impressive performance in graph representation learning, but they face challenges in capturing long-range dependencies due to their limited expressive power. To address this, Graph Transformers (GTs) were introduced, utilizing self-attention mechanism to effectively model pairwise node relationships. Despite their advantages, GTs suffer from quadratic complexity w.r.t. the number of nodes in the graph, hindering their applicability to large graphs. In this work, we present Graph-Enhanced Contextual Operator (GECO), a scalable and effective alternative to GTs that leverages neighborhood propagation and global convolutions to effectively capture local and global dependencies in quasilinear time. Our study on synthetic datasets reveals that GECO reaches 169x speedup on a graph with 2M nodes w.r.t. optimized attention. Further evaluations on diverse range of benchmarks showcase that GECO scales to large graphs where traditional GTs often face memory and time limitations. Notably, GECO consistently achieves comparable or superior quality compared to baselines, improving the SOTA up to 4.5%, and offering a scalable and effective solution for large-scale graph learning.
Read more6/19/2024