Toward efficient resource utilization at edge nodes in federated learning
2309.10367
0
0
Abstract
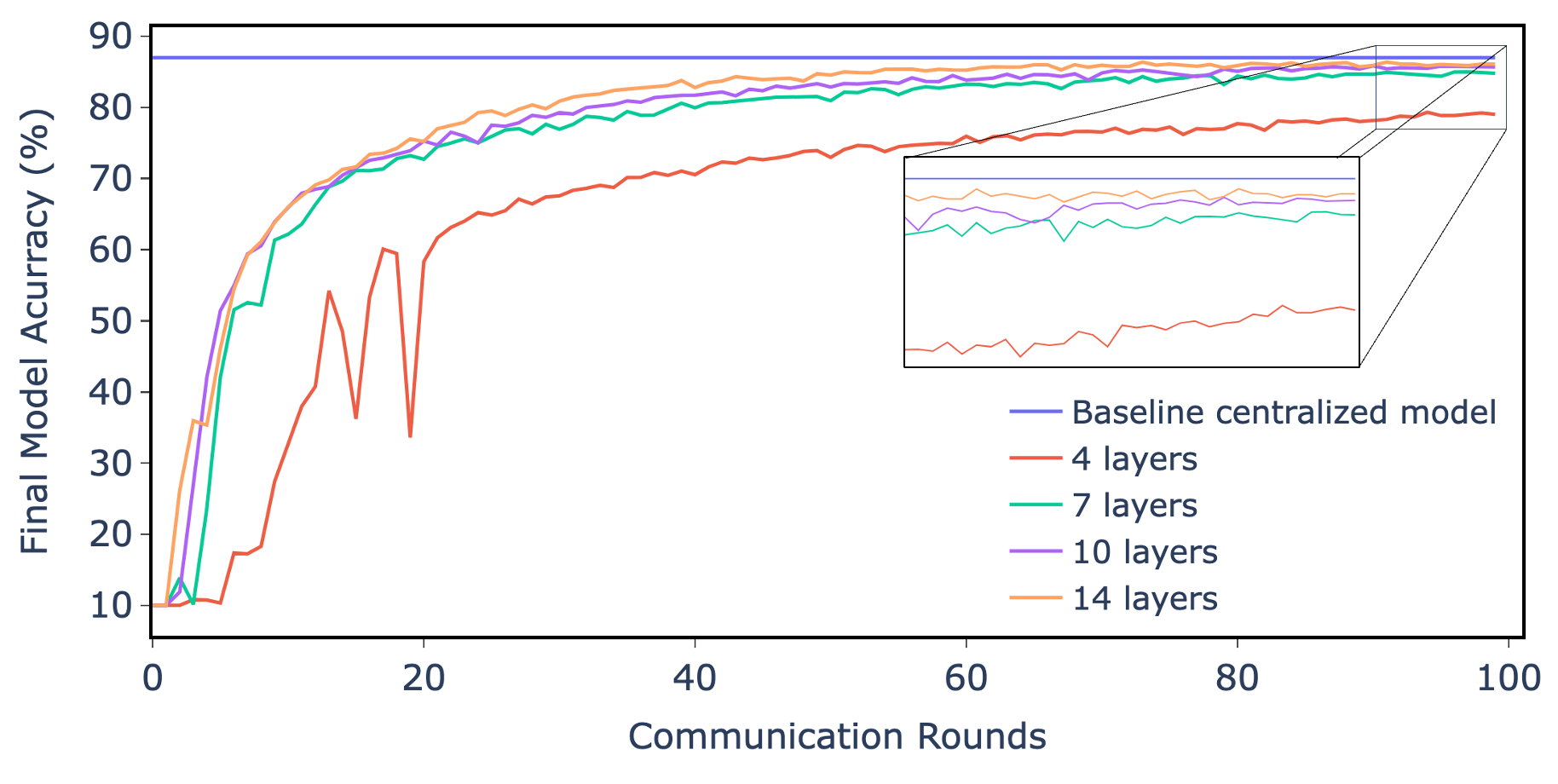
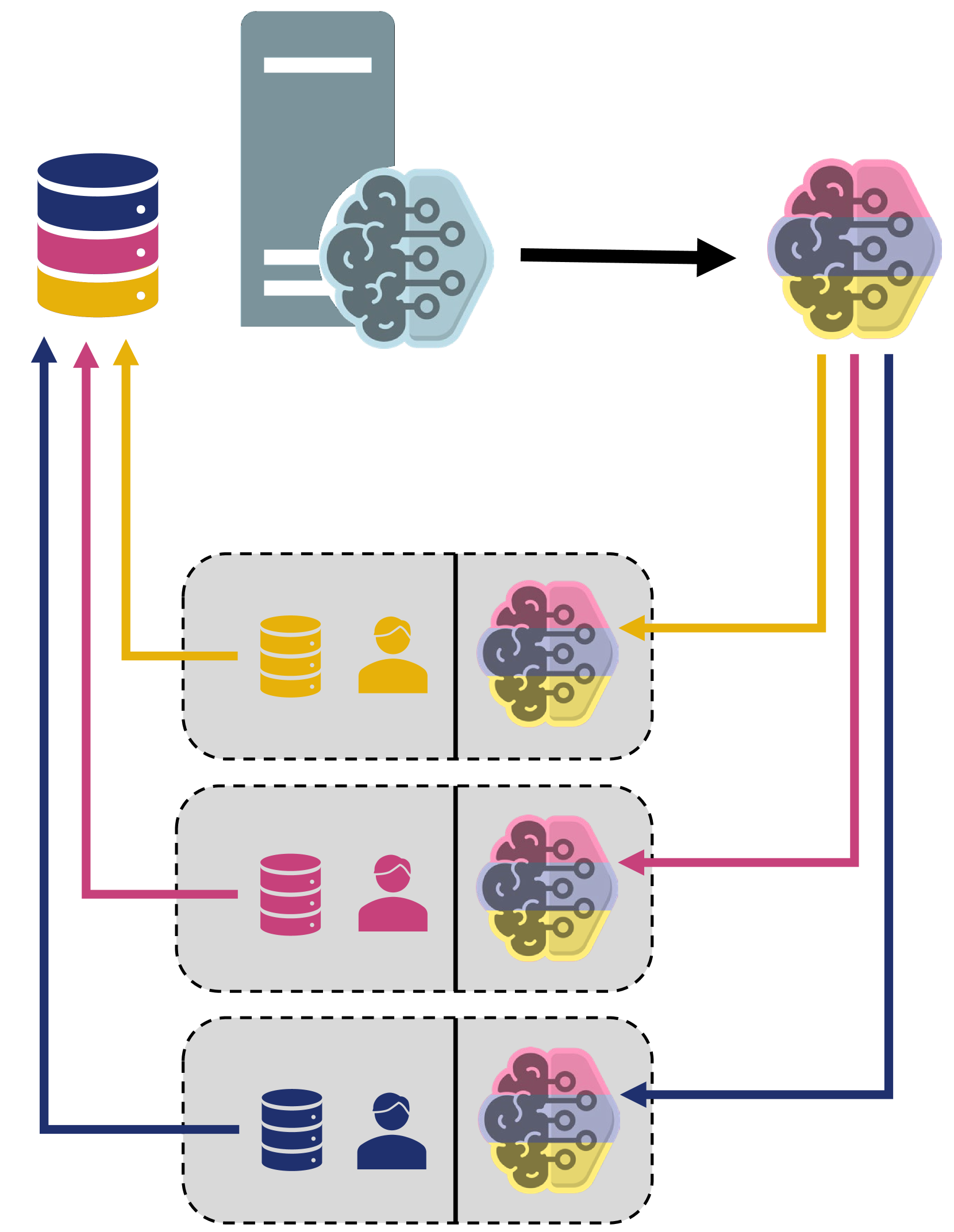
Federated learning (FL) enables edge nodes to collaboratively contribute to constructing a global model without sharing their data. This is accomplished by devices computing local, private model updates that are then aggregated by a server. However, computational resource constraints and network communication can become a severe bottleneck for larger model sizes typical for deep learning applications. Edge nodes tend to have limited hardware resources (RAM, CPU), and the network bandwidth and reliability at the edge is a concern for scaling federated fleet applications. In this paper, we propose and evaluate a FL strategy inspired by transfer learning in order to reduce resource utilization on devices, as well as the load on the server and network in each global training round. For each local model update, we randomly select layers to train, freezing the remaining part of the model. In doing so, we can reduce both server load and communication costs per round by excluding all untrained layer weights from being transferred to the server. The goal of this study is to empirically explore the potential trade-off between resource utilization on devices and global model convergence under the proposed strategy. We implement the approach using the federated learning framework FEDn. A number of experiments were carried out over different datasets (CIFAR-10, CASA, and IMDB), performing different tasks using different deep-learning model architectures. Our results show that training the model partially can accelerate the training process, efficiently utilizes resources on-device, and reduce the data transmission by around 75% and 53% when we train 25%, and 50% of the model layers, respectively, without harming the resulting global model accuracy.
Create account to get full access
Overview
- This paper explores ways to improve resource utilization at edge nodes in federated learning, a machine learning technique where a shared model is trained across multiple devices without sharing the underlying data.
- The key ideas include optimizing the distribution of training data across devices, adaptively adjusting the amount of local training based on device capabilities, and efficiently estimating the data distribution on edge nodes.
Plain English Explanation
Federated learning allows multiple devices like phones or sensors to collaboratively train a machine learning model without sharing their private data. This is useful for applications like virtual assistants or healthcare monitoring, where the data needs to stay on the user's device. However, the available computing power and network bandwidth on these edge devices can vary a lot, which can make it challenging to use federated learning efficiently.
This paper proposes several techniques to address this issue. First, it looks at ways to distribute the training data more evenly across the devices to avoid some devices getting overwhelmed. Second, it suggests adaptively adjusting the amount of local training done on each device based on their available resources. And third, it explores efficiently estimating the data distribution on the edge devices to help coordinate the overall training process.
The goal of these techniques is to make federated learning work better on a wide range of edge devices, from powerful smartphones to low-cost sensors, by making the best use of their available computing power and network connections. This could enable new applications that rely on privacy-preserving machine learning at the edge.
Technical Explanation
The paper first provides an overview of federated learning and related schemes, such as FedAvg and AdaptSFL, that aim to improve resource utilization.
It then proposes three main contributions:
-
Efficient data distribution: The authors develop a method to estimate the data distribution on edge nodes and use this to allocate training data more evenly across devices, avoiding overloading some nodes.
-
Adaptive local training: Building on AdaptSFL, the paper presents an approach to dynamically adjust the amount of local training done on each device based on its available resources, improving overall efficiency.
-
Resource-aware heterogeneous federated learning: The authors propose a neural network-based method to estimate the data distribution on edge nodes, which can then be used to coordinate the federated learning process and better utilize device resources.
The paper evaluates these techniques on several benchmark datasets and edge device configurations, demonstrating improvements in training time, model accuracy, and resource utilization compared to existing federated learning approaches.
Critical Analysis
The paper makes a thoughtful effort to address the challenge of efficiently utilizing edge node resources in federated learning. The proposed techniques, such as adaptive local training and efficient data distribution estimation, seem well-designed and potentially impactful.
However, the evaluation is limited to simulated edge device scenarios, and it's unclear how these methods would perform in real-world deployments with heterogeneous, dynamic device populations and unpredictable network conditions. Further research is needed to understand the practical limitations and trade-offs of these approaches.
Additionally, the paper does not discuss potential privacy or security implications of the proposed techniques. Federated learning is motivated by privacy preservation, so it's important to ensure that these resource optimization methods do not inadvertently introduce new vulnerabilities or compromise the confidentiality of user data.
Overall, this paper presents a promising direction for improving federated learning efficiency, but additional work is needed to fully validate the approach and address potential concerns around real-world deployment and privacy preservation.
Conclusion
This paper explores several techniques to enhance resource utilization at edge nodes in federated learning, a privacy-preserving machine learning paradigm. By optimizing data distribution, adapting local training, and efficiently estimating data distributions, the proposed methods aim to make federated learning more practical and effective on a wide range of edge devices.
If successful, these innovations could unlock new applications of privacy-preserving AI at the edge, such as personalized virtual assistants, distributed healthcare monitoring, and smart city sensing. However, further research is needed to understand the real-world feasibility and potential security/privacy trade-offs of these approaches.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
📊
Enhancing Efficiency in Multidevice Federated Learning through Data Selection
Fan Mo, Mohammad Malekzadeh, Soumyajit Chatterjee, Fahim Kawsar, Akhil Mathur
0
0
Federated learning (FL) in multidevice environments creates new opportunities to learn from a vast and diverse amount of private data. Although personal devices capture valuable data, their memory, computing, connectivity, and battery resources are often limited. Since deep neural networks (DNNs) are the typical machine learning models employed in FL, there are demands for integrating ubiquitous constrained devices into the training process of DNNs. In this paper, we develop an FL framework to incorporate on-device data selection on such constrained devices, which allows partition-based training of a DNN through collaboration between constrained devices and resourceful devices of the same client. Evaluations on five benchmark DNNs and six benchmark datasets across different modalities show that, on average, our framework achieves ~19% higher accuracy and ~58% lower latency; compared to the baseline FL without our implemented strategies. We demonstrate the effectiveness of our FL framework when dealing with imbalanced data, client participation heterogeneity, and various mobility patterns. As a benchmark for the community, our code is available at https://github.com/dr-bell/data-centric-federated-learning
4/11/2024
Federated Learning: A Cutting-Edge Survey of the Latest Advancements and Applications
Azim Akhtarshenas, Mohammad Ali Vahedifar, Navid Ayoobi, Behrouz Maham, Tohid Alizadeh, Sina Ebrahimi, David L'opez-P'erez
0
0
Robust machine learning (ML) models can be developed by leveraging large volumes of data and distributing the computational tasks across numerous devices or servers. Federated learning (FL) is a technique in the realm of ML that facilitates this goal by utilizing cloud infrastructure to enable collaborative model training among a network of decentralized devices. Beyond distributing the computational load, FL targets the resolution of privacy issues and the reduction of communication costs simultaneously. To protect user privacy, FL requires users to send model updates rather than transmitting large quantities of raw and potentially confidential data. Specifically, individuals train ML models locally using their own data and then upload the results in the form of weights and gradients to the cloud for aggregation into the global model. This strategy is also advantageous in environments with limited bandwidth or high communication costs, as it prevents the transmission of large data volumes. With the increasing volume of data and rising privacy concerns, alongside the emergence of large-scale ML models like Large Language Models (LLMs), FL presents itself as a timely and relevant solution. It is therefore essential to review current FL algorithms to guide future research that meets the rapidly evolving ML demands. This survey provides a comprehensive analysis and comparison of the most recent FL algorithms, evaluating them on various fronts including mathematical frameworks, privacy protection, resource allocation, and applications. Beyond summarizing existing FL methods, this survey identifies potential gaps, open areas, and future challenges based on the performance reports and algorithms used in recent studies. This survey enables researchers to readily identify existing limitations in the FL field for further exploration.
5/28/2024
🤯
AdaptSFL: Adaptive Split Federated Learning in Resource-constrained Edge Networks
Zheng Lin, Guanqiao Qu, Wei Wei, Xianhao Chen, Kin K. Leung
0
0
The increasing complexity of deep neural networks poses significant barriers to democratizing them to resource-limited edge devices. To address this challenge, split federated learning (SFL) has emerged as a promising solution by of floading the primary training workload to a server via model partitioning while enabling parallel training among edge devices. However, although system optimization substantially influences the performance of SFL under resource-constrained systems, the problem remains largely uncharted. In this paper, we provide a convergence analysis of SFL which quantifies the impact of model splitting (MS) and client-side model aggregation (MA) on the learning performance, serving as a theoretical foundation. Then, we propose AdaptSFL, a novel resource-adaptive SFL framework, to expedite SFL under resource-constrained edge computing systems. Specifically, AdaptSFL adaptively controls client-side MA and MS to balance communication-computing latency and training convergence. Extensive simulations across various datasets validate that our proposed AdaptSFL framework takes considerably less time to achieve a target accuracy than benchmarks, demonstrating the effectiveness of the proposed strategies.
5/24/2024
🧠
Resource-Aware Heterogeneous Federated Learning using Neural Architecture Search
Sixing Yu, J. Pablo Mu~noz, Ali Jannesari
0
0
Federated Learning (FL) is extensively used to train AI/ML models in distributed and privacy-preserving settings. Participant edge devices in FL systems typically contain non-independent and identically distributed (Non-IID) private data and unevenly distributed computational resources. Preserving user data privacy while optimizing AI/ML models in a heterogeneous federated network requires us to address data and system/resource heterogeneity. To address these challenges, we propose Resource-aware Federated Learning (RaFL). RaFL allocates resource-aware specialized models to edge devices using Neural Architecture Search (NAS) and allows heterogeneous model architecture deployment by knowledge extraction and fusion. Combining NAS and FL enables on-demand customized model deployment for resource-diverse edge devices. Furthermore, we propose a multi-model architecture fusion scheme allowing the aggregation of the distributed learning results. Results demonstrate RaFL's superior resource efficiency compared to SoTA.
5/2/2024