Efficient Data Distribution Estimation for Accelerated Federated Learning

0

Sign in to get full access
Overview
- This paper presents a novel approach to accelerate the convergence of federated learning by efficiently estimating the data distribution across client devices.
- The key idea is to leverage heterogeneity-aware clustering to identify client subgroups with similar data distributions, enabling faster model updates and improved overall performance.
- The proposed method outperforms existing federated learning techniques on various benchmark tasks, demonstrating its effectiveness in tackling the challenges of data heterogeneity in real-world federated settings.
Plain English Explanation
Federated learning is a powerful technique that allows multiple devices, such as smartphones or IoT sensors, to collaboratively train a machine learning model without sharing their raw data. This is particularly useful when the data is sensitive or distributed across many locations.
However, one major challenge in federated learning is that the data on each device can be quite different, a problem known as data heterogeneity. This can slow down the training process and reduce the overall performance of the model.
This paper introduces a new approach to address this challenge. The key idea is to first group the devices into clusters based on the similarity of their data distributions. This allows the system to identify subgroups of devices that have more homogeneous data, and then optimize the model updates for each subgroup separately.
By taking this heterogeneity-aware approach, the federated learning process can converge much faster, leading to improved model performance compared to standard federated learning techniques. This is particularly important in real-world applications where data may be highly diverse across different devices or locations.
Technical Explanation
The paper proposes a Heterogeneity-aware cluster based Federated Learning approach to accelerate the convergence of federated learning. The key idea is to leverage heterogeneity-aware clustering to identify client subgroups with similar data distributions, enabling faster model updates and improved overall performance.
Specifically, the method first estimates the data distribution on each client device using a lightweight neural network. It then clusters the clients based on the similarity of their data distributions, forming subgroups of devices with more homogeneous data.
During the federated learning process, the server performs separate model updates for each client subgroup, taking advantage of the reduced data heterogeneity within each cluster. This ranking-based client selection approach leads to faster convergence and better final model performance compared to standard federated learning techniques.
The paper evaluates the proposed method on several federated learning benchmark tasks, demonstrating its effectiveness in tackling the challenges of data heterogeneity in real-world federated settings. The results show that the heterogeneity-aware clustering can significantly accelerate the convergence of hybrid federated learning compared to existing approaches.
Critical Analysis
The paper presents a promising approach to addressing the critical challenge of data heterogeneity in federated learning. By introducing a heterogeneity-aware clustering mechanism, the method is able to identify client subgroups with more similar data distributions, enabling faster model updates and improved performance.
One potential limitation of the proposed technique is the reliance on a lightweight neural network to estimate the data distributions on each client device. While this approach is designed to be efficient, it may not capture the full complexity of the data distributions, particularly for highly diverse datasets. Further research could explore alternative distribution estimation techniques, such as nonparametric density estimation methods, to improve the accuracy of the clustering process.
Additionally, the paper does not extensively explore the scalability of the approach as the number of client devices increases. In real-world federated learning scenarios, the number of participating devices can be quite large, and the computational and communication overhead of the clustering process may become a bottleneck. Investigating strategies to efficiently handle large-scale federated learning systems would be a valuable direction for future work.
Overall, the paper presents a compelling and well-executed approach to accelerating federated learning in the face of data heterogeneity. The heterogeneity-aware clustering technique is a promising contribution to the field, and the empirical results demonstrate its effectiveness. Further research to address the potential limitations and scale the method to larger settings could greatly enhance its practical impact.
Conclusion
This paper introduces a novel approach to accelerate the convergence of federated learning by efficiently estimating the data distribution across client devices. The key innovation is the use of heterogeneity-aware clustering to identify client subgroups with similar data distributions, enabling faster model updates and improved overall performance.
The proposed method outperforms existing federated learning techniques on various benchmark tasks, demonstrating its effectiveness in tackling the challenges of data heterogeneity in real-world federated settings. This work represents an important step forward in enhancing the efficiency and practical applicability of federated learning, which has significant implications for privacy-preserving machine learning in a wide range of domains.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Efficient Data Distribution Estimation for Accelerated Federated Learning
Yuanli Wang, Lei Huang
Federated Learning(FL) is a privacy-preserving machine learning paradigm where a global model is trained in-situ across a large number of distributed edge devices. These systems are often comprised of millions of user devices and only a subset of available devices can be used for training in each epoch. Designing a device selection strategy is challenging, given that devices are highly heterogeneous in both their system resources and training data. This heterogeneity makes device selection very crucial for timely model convergence and sufficient model accuracy. To tackle the FL client heterogeneity problem, various client selection algorithms have been developed, showing promising performance improvement in terms of model coverage and accuracy. In this work, we study the overhead of client selection algorithms in a large scale FL environment. Then we propose an efficient data distribution summary calculation algorithm to reduce the overhead in a real-world large scale FL environment. The evaluation shows that our proposed solution could achieve up to 30x reduction in data summary time, and up to 360x reduction in clustering time.
Read more6/5/2024
📊
0
Enhancing Efficiency in Multidevice Federated Learning through Data Selection
Fan Mo, Mohammad Malekzadeh, Soumyajit Chatterjee, Fahim Kawsar, Akhil Mathur
Federated learning (FL) in multidevice environments creates new opportunities to learn from a vast and diverse amount of private data. Although personal devices capture valuable data, their memory, computing, connectivity, and battery resources are often limited. Since deep neural networks (DNNs) are the typical machine learning models employed in FL, there are demands for integrating ubiquitous constrained devices into the training process of DNNs. In this paper, we develop an FL framework to incorporate on-device data selection on such constrained devices, which allows partition-based training of a DNN through collaboration between constrained devices and resourceful devices of the same client. Evaluations on five benchmark DNNs and six benchmark datasets across different modalities show that, on average, our framework achieves ~19% higher accuracy and ~58% lower latency; compared to the baseline FL without our implemented strategies. We demonstrate the effectiveness of our FL framework when dealing with imbalanced data, client participation heterogeneity, and various mobility patterns. As a benchmark for the community, our code is available at https://github.com/dr-bell/data-centric-federated-learning
Read more4/11/2024
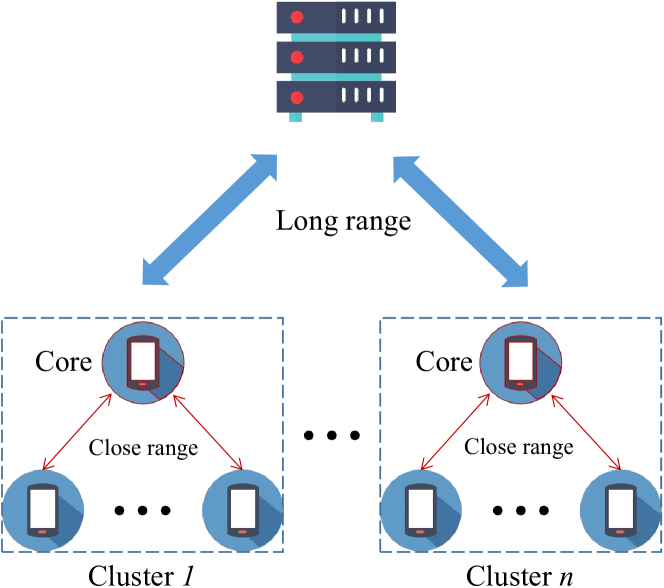
0
Efficient Model Compression for Hierarchical Federated Learning
Xi Zhu, Songcan Yu, Junbo Wang, Qinglin Yang
Federated learning (FL), as an emerging collaborative learning paradigm, has garnered significant attention due to its capacity to preserve privacy within distributed learning systems. In these systems, clients collaboratively train a unified neural network model using their local datasets and share model parameters rather than raw data, enhancing privacy. Predominantly, FL systems are designed for mobile and edge computing environments where training typically occurs over wireless networks. Consequently, as model sizes increase, the conventional FL frameworks increasingly consume substantial communication resources. To address this challenge and improve communication efficiency, this paper introduces a novel hierarchical FL framework that integrates the benefits of clustered FL and model compression. We present an adaptive clustering algorithm that identifies a core client and dynamically organizes clients into clusters. Furthermore, to enhance transmission efficiency, each core client implements a local aggregation with compression (LC aggregation) algorithm after collecting compressed models from other clients within the same cluster. Simulation results affirm that our proposed algorithms not only maintain comparable predictive accuracy but also significantly reduce energy consumption relative to existing FL mechanisms.
Read more5/29/2024

0
Ranking-based Client Selection with Imitation Learning for Efficient Federated Learning
Chunlin Tian, Zhan Shi, Xinpeng Qin, Li Li, Chengzhong Xu
Federated Learning (FL) enables multiple devices to collaboratively train a shared model while ensuring data privacy. The selection of participating devices in each training round critically affects both the model performance and training efficiency, especially given the vast heterogeneity in training capabilities and data distribution across devices. To address these challenges, we introduce a novel device selection solution called FedRank, which is an end-to-end, ranking-based approach that is pre-trained by imitation learning against state-of-the-art analytical approaches. It not only considers data and system heterogeneity at runtime but also adaptively and efficiently chooses the most suitable clients for model training. Specifically, FedRank views client selection in FL as a ranking problem and employs a pairwise training strategy for the smart selection process. Additionally, an imitation learning-based approach is designed to counteract the cold-start issues often seen in state-of-the-art learning-based approaches. Experimental results reveal that model~ boosts model accuracy by 5.2% to 56.9%, accelerates the training convergence up to $2.01 times$ and saves the energy consumption up to $40.1%$.
Read more5/8/2024