Toward Fairer Face Recognition Datasets
2406.16592
0
0
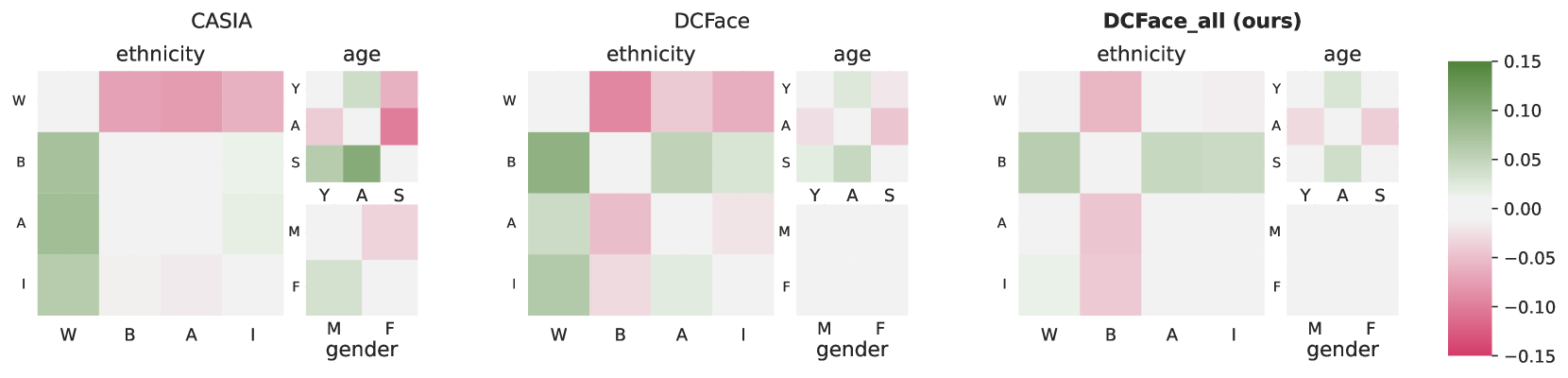
Abstract
Face recognition and verification are two computer vision tasks whose performance has progressed with the introduction of deep representations. However, ethical, legal, and technical challenges due to the sensitive character of face data and biases in real training datasets hinder their development. Generative AI addresses privacy by creating fictitious identities, but fairness problems persist. We promote fairness by introducing a demographic attributes balancing mechanism in generated training datasets. We experiment with an existing real dataset, three generated training datasets, and the balanced versions of a diffusion-based dataset. We propose a comprehensive evaluation that considers accuracy and fairness equally and includes a rigorous regression-based statistical analysis of attributes. The analysis shows that balancing reduces demographic unfairness. Also, a performance gap persists despite generation becoming more accurate with time. The proposed balancing method and comprehensive verification evaluation promote fairer and transparent face recognition and verification.
Create account to get full access
Overview
- This paper discusses the importance of developing fairer face recognition datasets to address biases in AI systems.
- The authors highlight the need for more diverse and representative datasets to improve the fairness and accuracy of face recognition algorithms.
- They review related work on improving dataset fairness and introduce their own approach to building more equitable face recognition datasets.
Plain English Explanation
Face recognition technology has become increasingly sophisticated, with applications ranging from security systems to photo tagging. However, many of the datasets used to train these AI models have been found to be biased, leading to disparities in performance across different demographic groups.
To address this issue, the researchers in this paper propose new approaches to building more representative and fair face recognition datasets. They review prior efforts to create synthetic datasets and improve fairness in computer vision models, and then outline their own method for assembling a more diverse and balanced dataset.
The key idea is to carefully curate the dataset to ensure it includes a wide range of faces from different ages, genders, skin tones, and other demographic factors. This helps reduce the risk of the AI system performing poorly on certain populations, a common problem known as algorithmic bias.
By building fairer face recognition datasets, the researchers hope to create AI models that are more accurate and equitable for all users. This could have important implications for applications like surveillance, content moderation, and assistive technologies, where fair and unbiased performance is critical.
Technical Explanation
The paper begins by discussing the growing prevalence of face recognition technology and the importance of ensuring these systems are fair and unbiased. The authors note that many commonly used face recognition datasets, such as Labeled Faces in the Wild and MegaFace, have been shown to exhibit significant demographic imbalances and biases.
To address this issue, the researchers propose a framework for building more representative and equitable face recognition datasets. Their approach involves carefully curating the dataset to ensure it includes a diverse range of faces across various attributes, such as age, gender, skin tone, and ethnicity.
The authors review prior work on improving dataset fairness, including efforts to create synthetic face datasets and enhance fairness in computer vision models. They then outline their own methodology for assembling a more balanced and diverse face recognition dataset, which includes techniques for ensuring adequate representation of underrepresented groups and addressing potential biases in the data collection and annotation processes.
The paper presents the results of several experiments evaluating the fairness and performance of face recognition models trained on the authors' dataset compared to existing benchmarks. The findings suggest that the proposed approach can lead to significant improvements in fairness and accuracy, particularly for demographic groups that are typically underrepresented in face recognition datasets.
Critical Analysis
The paper makes a compelling case for the importance of developing fairer face recognition datasets to address the issue of algorithmic bias. The authors' proposed framework for curating more representative and diverse datasets is a promising approach that could have significant implications for improving the fairness and performance of face recognition systems.
One potential limitation of the research is the reliance on self-reported demographic information, which may not always be accurate or comprehensive. The authors acknowledge this issue and suggest that future work should explore alternative methods for obtaining more reliable demographic data, such as through expert annotations or automated detection algorithms.
Additionally, the paper does not delve into the potential privacy and ethical concerns associated with the collection and use of face recognition data, particularly for underrepresented or marginalized groups. As the authors note, these are important considerations that warrant further exploration and discussion within the research community.
Overall, this paper represents an important contribution to the ongoing efforts to address bias and fairness in AI systems. By highlighting the need for more representative and equitable face recognition datasets, the authors have laid the groundwork for future research and development in this critical area.
Conclusion
This paper underscores the importance of developing fairer and more representative face recognition datasets to mitigate the issue of algorithmic bias in AI systems. The authors propose a framework for curating diverse and balanced datasets, which they demonstrate can lead to significant improvements in the fairness and performance of face recognition models.
The findings of this research have important implications for a wide range of applications that rely on face recognition technology, from security and surveillance systems to social media and content moderation. By addressing the fundamental issue of dataset bias, the authors have laid the foundation for the creation of AI models that are more accurate, equitable, and inclusive for all users.
As the use of face recognition technology continues to grow, it is crucial that researchers and developers prioritize the development of fair and unbiased systems. This paper represents an important step forward in this direction, and its insights and methodologies will be valuable for guiding future work in this critical area of AI research.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

AI-Face: A Million-Scale Demographically Annotated AI-Generated Face Dataset and Fairness Benchmark
Li Lin, Santosh, Xin Wang, Shu Hu
0
0
AI-generated faces have enriched human life, such as entertainment, education, and art. However, they also pose misuse risks. Therefore, detecting AI-generated faces becomes crucial, yet current detectors show biased performance across different demographic groups. Mitigating biases can be done by designing algorithmic fairness methods, which usually require demographically annotated face datasets for model training. However, no existing dataset comprehensively encompasses both demographic attributes and diverse generative methods, which hinders the development of fair detectors for AI-generated faces. In this work, we introduce the AI-Face dataset, the first million-scale demographically annotated AI-generated face image dataset, including real faces, faces from deepfake videos, and faces generated by Generative Adversarial Networks and Diffusion Models. Based on this dataset, we conduct the first comprehensive fairness benchmark to assess various AI face detectors and provide valuable insights and findings to promote the future fair design of AI face detectors. Our AI-Face dataset and benchmark code are publicly available at https://github.com/Purdue-M2/AI-Face-FairnessBench.
6/5/2024
🖼️
SDFD: Building a Versatile Synthetic Face Image Dataset with Diverse Attributes
Georgia Baltsou, Ioannis Sarridis, Christos Koutlis, Symeon Papadopoulos
0
0
AI systems rely on extensive training on large datasets to address various tasks. However, image-based systems, particularly those used for demographic attribute prediction, face significant challenges. Many current face image datasets primarily focus on demographic factors such as age, gender, and skin tone, overlooking other crucial facial attributes like hairstyle and accessories. This narrow focus limits the diversity of the data and consequently the robustness of AI systems trained on them. This work aims to address this limitation by proposing a methodology for generating synthetic face image datasets that capture a broader spectrum of facial diversity. Specifically, our approach integrates a systematic prompt formulation strategy, encompassing not only demographics and biometrics but also non-permanent traits like make-up, hairstyle, and accessories. These prompts guide a state-of-the-art text-to-image model in generating a comprehensive dataset of high-quality realistic images and can be used as an evaluation set in face analysis systems. Compared to existing datasets, our proposed dataset proves equally or more challenging in image classification tasks while being much smaller in size.
4/30/2024

Benchmarking the Fairness of Image Upsampling Methods
Mike Laszkiewicz, Imant Daunhawer, Julia E. Vogt, Asja Fischer, Johannes Lederer
0
0
Recent years have witnessed a rapid development of deep generative models for creating synthetic media, such as images and videos. While the practical applications of these models in everyday tasks are enticing, it is crucial to assess the inherent risks regarding their fairness. In this work, we introduce a comprehensive framework for benchmarking the performance and fairness of conditional generative models. We develop a set of metrics$unicode{x2013}$inspired by their supervised fairness counterparts$unicode{x2013}$to evaluate the models on their fairness and diversity. Focusing on the specific application of image upsampling, we create a benchmark covering a wide variety of modern upsampling methods. As part of the benchmark, we introduce UnfairFace, a subset of FairFace that replicates the racial distribution of common large-scale face datasets. Our empirical study highlights the importance of using an unbiased training set and reveals variations in how the algorithms respond to dataset imbalances. Alarmingly, we find that none of the considered methods produces statistically fair and diverse results. All experiments can be reproduced using our provided repository.
5/1/2024

FairVision: Equitable Deep Learning for Eye Disease Screening via Fair Identity Scaling
Yan Luo, Muhammad Osama Khan, Yu Tian, Min Shi, Zehao Dou, Tobias Elze, Yi Fang, Mengyu Wang
0
0
Equity in AI for healthcare is crucial due to its direct impact on human well-being. Despite advancements in 2D medical imaging fairness, the fairness of 3D models remains underexplored, hindered by the small sizes of 3D fairness datasets. Since 3D imaging surpasses 2D imaging in SOTA clinical care, it is critical to understand the fairness of these 3D models. To address this research gap, we conduct the first comprehensive study on the fairness of 3D medical imaging models across multiple protected attributes. Our investigation spans both 2D and 3D models and evaluates fairness across five architectures on three common eye diseases, revealing significant biases across race, gender, and ethnicity. To alleviate these biases, we propose a novel fair identity scaling (FIS) method that improves both overall performance and fairness, outperforming various SOTA fairness methods. Moreover, we release Harvard-FairVision, the first large-scale medical fairness dataset with 30,000 subjects featuring both 2D and 3D imaging data and six demographic identity attributes. Harvard-FairVision provides labels for three major eye disorders affecting about 380 million people worldwide, serving as a valuable resource for both 2D and 3D fairness learning. Our code and dataset are publicly accessible at url{https://ophai.hms.harvard.edu/datasets/harvard-fairvision30k}.
4/15/2024