AI-Face: A Million-Scale Demographically Annotated AI-Generated Face Dataset and Fairness Benchmark

0

Sign in to get full access
Overview
- This paper introduces a large-scale, demographically annotated dataset of AI-generated face images called AI-Face.
- The dataset is designed to serve as a benchmark for evaluating the fairness and bias of computer vision models that work with facial images.
- The paper also presents findings from using AI-Face to assess the fairness of several state-of-the-art face recognition and generation models.
Plain English Explanation
The researchers have created a massive dataset of artificial face images, called AI-Face, that is carefully labeled with demographic information about the people depicted. This dataset is intended to be used as a tool for testing whether AI systems that work with facial images are fair and unbiased, or if they exhibit problematic biases.
Facial recognition and generation models are increasingly being used in high-stakes applications like surveillance, security, and hiring. However, these models have been shown to perform poorly on certain demographic groups, like women and racial minorities. The AI-Face dataset provides a standardized benchmark that researchers and developers can use to evaluate the fairness of their AI facial analysis systems.
By using AI-Face to assess several leading face recognition and generation models, the researchers found evidence of significant demographic biases. This highlights the need for more comprehensive fairness testing and mitigation strategies as these AI technologies become more widely deployed.
Technical Explanation
The AI-Face dataset contains over 1 million synthetic face images, generated using state-of-the-art AI models. Each image is annotated with demographic information like age, gender, and race/ethnicity. This allows the dataset to be used to assess how well facial analysis models perform across different demographic groups.
The researchers used AI-Face to evaluate the fairness of several facial recognition and generation models, including FaceNet, FairVision, and PULSE. They found that these models exhibited significant performance gaps between demographic groups, with lower accuracy on women, younger people, and racial minorities.
The authors also explored techniques for detecting AI-generated faces using AI-Face, and discussed the potential for using large, annotated synthetic datasets to improve the fairness of computer vision models.
Critical Analysis
The AI-Face dataset and benchmark represent an important step towards more comprehensive fairness evaluation of facial analysis technologies. By using a large, carefully curated dataset of synthetic faces, the researchers were able to uncover significant demographic biases in state-of-the-art models.
However, the paper does not address the limitations of using synthetic data to evaluate real-world system performance. While AI-Face can reveal potential fairness issues, it is unclear how well the findings would translate to models deployed in the field. More research is needed to understand how to effectively bridge the gap between synthetic and real-world facial data.
Additionally, the paper provides limited insight into the root causes of the observed biases. Understanding the precise factors contributing to demographic disparities is crucial for developing effective mitigation strategies. Future work could delve deeper into the model architectures, training data, and other factors shaping the fairness characteristics of facial analysis systems.
Conclusion
The AI-Face dataset and benchmark represent an important advancement in the effort to ensure fairness in facial analysis technologies. By providing a large-scale, annotated dataset of synthetic faces, the researchers have enabled more comprehensive and rigorous fairness testing than was previously possible.
The findings from using AI-Face to evaluate several leading facial recognition and generation models highlight the persistence of demographic biases in these systems. This underscores the critical need for continued research and development of fairness-aware computer vision techniques as these technologies become more widely deployed in high-stakes applications.
Overall, the AI-Face dataset and the insights gleaned from its use are a valuable contribution to the ongoing pursuit of equitable and responsible AI systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
AI-Face: A Million-Scale Demographically Annotated AI-Generated Face Dataset and Fairness Benchmark
Li Lin, Santosh, Xin Wang, Shu Hu
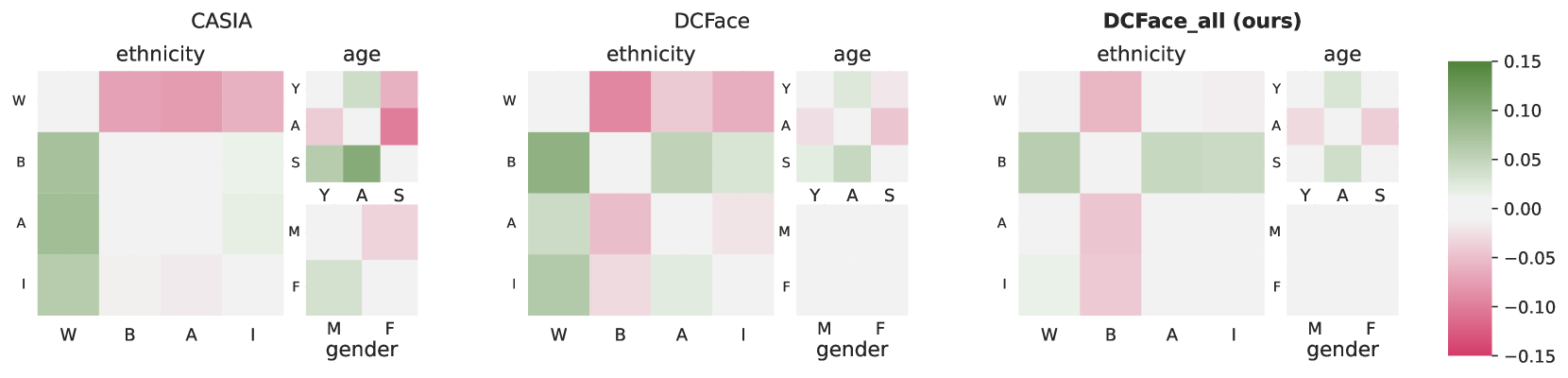
AI-generated faces have enriched human life, such as entertainment, education, and art. However, they also pose misuse risks. Therefore, detecting AI-generated faces becomes crucial, yet current detectors show biased performance across different demographic groups. Mitigating biases can be done by designing algorithmic fairness methods, which usually require demographically annotated face datasets for model training. However, no existing dataset comprehensively encompasses both demographic attributes and diverse generative methods, which hinders the development of fair detectors for AI-generated faces. In this work, we introduce the AI-Face dataset, the first million-scale demographically annotated AI-generated face image dataset, including real faces, faces from deepfake videos, and faces generated by Generative Adversarial Networks and Diffusion Models. Based on this dataset, we conduct the first comprehensive fairness benchmark to assess various AI face detectors and provide valuable insights and findings to promote the future fair design of AI face detectors. Our AI-Face dataset and benchmark code are publicly available at https://github.com/Purdue-M2/AI-Face-FairnessBench.
Read more6/5/2024
0
Toward Fairer Face Recognition Datasets
Alexandre Fournier-Mongieux, Michael Soumm, Adrian Popescu, Bertrand Luvison, Herv'e Le Borgne
Face recognition and verification are two computer vision tasks whose performance has progressed with the introduction of deep representations. However, ethical, legal, and technical challenges due to the sensitive character of face data and biases in real training datasets hinder their development. Generative AI addresses privacy by creating fictitious identities, but fairness problems persist. We promote fairness by introducing a demographic attributes balancing mechanism in generated training datasets. We experiment with an existing real dataset, three generated training datasets, and the balanced versions of a diffusion-based dataset. We propose a comprehensive evaluation that considers accuracy and fairness equally and includes a rigorous regression-based statistical analysis of attributes. The analysis shows that balancing reduces demographic unfairness. Also, a performance gap persists despite generation becoming more accurate with time. The proposed balancing method and comprehensive verification evaluation promote fairer and transparent face recognition and verification.
Read more6/26/2024

0
FineFACE: Fair Facial Attribute Classification Leveraging Fine-grained Features
Ayesha Manzoor, Ajita Rattani
Published research highlights the presence of demographic bias in automated facial attribute classification algorithms, particularly impacting women and individuals with darker skin tones. Existing bias mitigation techniques typically require demographic annotations and often obtain a trade-off between fairness and accuracy, i.e., Pareto inefficiency. Facial attributes, whether common ones like gender or others such as chubby or high cheekbones, exhibit high interclass similarity and intraclass variation across demographics leading to unequal accuracy. This requires the use of local and subtle cues using fine-grained analysis for differentiation. This paper proposes a novel approach to fair facial attribute classification by framing it as a fine-grained classification problem. Our approach effectively integrates both low-level local features (like edges and color) and high-level semantic features (like shapes and structures) through cross-layer mutual attention learning. Here, shallow to deep CNN layers function as experts, offering category predictions and attention regions. An exhaustive evaluation on facial attribute annotated datasets demonstrates that our FineFACE model improves accuracy by 1.32% to 1.74% and fairness by 67% to 83.6%, over the SOTA bias mitigation techniques. Importantly, our approach obtains a Pareto-efficient balance between accuracy and fairness between demographic groups. In addition, our approach does not require demographic annotations and is applicable to diverse downstream classification tasks. To facilitate reproducibility, the code and dataset information is available at https://github.com/VCBSL-Fairness/FineFACE.
Read more9/2/2024
0
A Large-scale Universal Evaluation Benchmark For Face Forgery Detection
Yijun Bei, Hengrui Lou, Jinsong Geng, Erteng Liu, Lechao Cheng, Jie Song, Mingli Song, Zunlei Feng
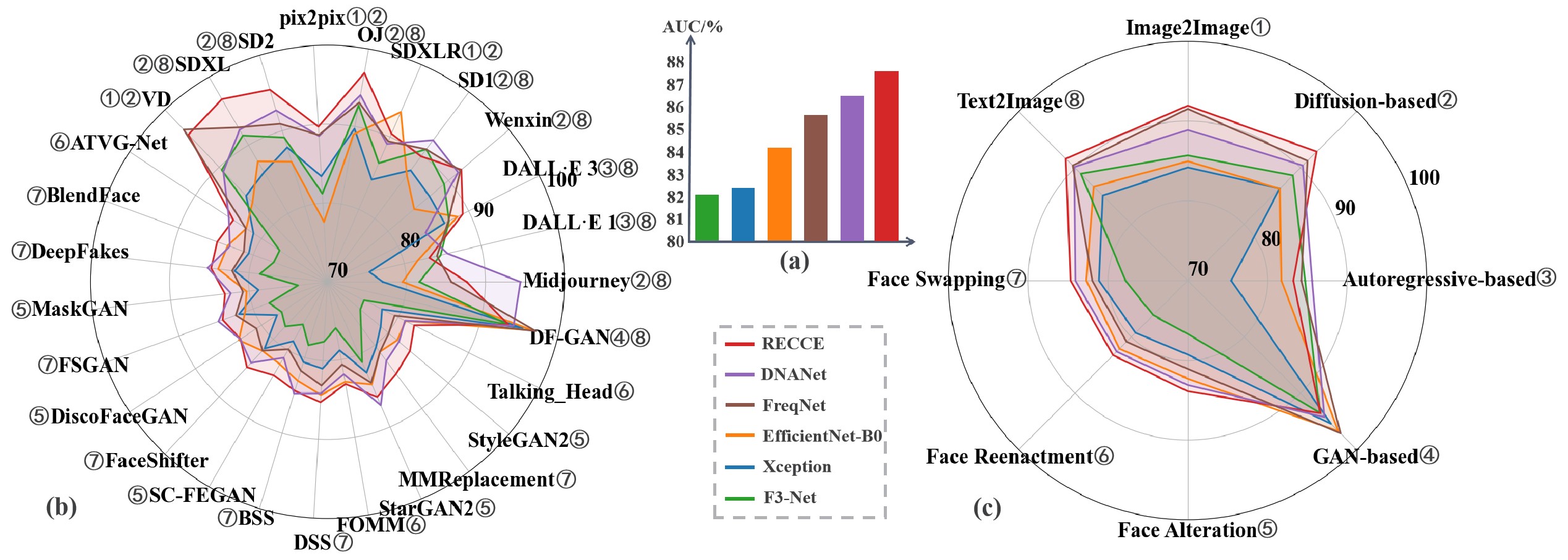
With the rapid development of AI-generated content (AIGC) technology, the production of realistic fake facial images and videos that deceive human visual perception has become possible. Consequently, various face forgery detection techniques have been proposed to identify such fake facial content. However, evaluating the effectiveness and generalizability of these detection techniques remains a significant challenge. To address this, we have constructed a large-scale evaluation benchmark called DeepFaceGen, aimed at quantitatively assessing the effectiveness of face forgery detection and facilitating the iterative development of forgery detection technology. DeepFaceGen consists of 776,990 real face image/video samples and 773,812 face forgery image/video samples, generated using 34 mainstream face generation techniques. During the construction process, we carefully consider important factors such as content diversity, fairness across ethnicities, and availability of comprehensive labels, in order to ensure the versatility and convenience of DeepFaceGen. Subsequently, DeepFaceGen is employed in this study to evaluate and analyze the performance of 13 mainstream face forgery detection techniques from various perspectives. Through extensive experimental analysis, we derive significant findings and propose potential directions for future research. The code and dataset for DeepFaceGen are available at https://github.com/HengruiLou/DeepFaceGen.
Read more6/17/2024