Towards Analyzing and Understanding the Limitations of DPO: A Theoretical Perspective
2404.04626
0
0
Abstract
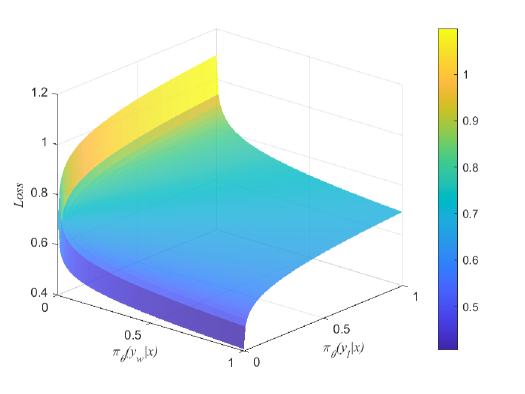
Direct Preference Optimization (DPO), which derives reward signals directly from pairwise preference data, has shown its effectiveness on aligning Large Language Models (LLMs) with human preferences. Despite its widespread use across various tasks, DPO has been criticized for its sensitivity to the SFT's effectiveness and its hindrance to the learning capacity towards human-preferred responses, leading to less satisfactory performance. To overcome those limitations, the theoretical understanding of DPO are indispensable but still lacking. To this end, we take a step towards theoretically analyzing and understanding the limitations of DPO. Specifically, we provide an analytical framework using the field theory to analyze the optimization process of DPO. By analyzing the gradient vector field of the DPO loss function, we find that the DPO loss function decreases the probability of producing human dispreferred data at a faster rate than it increases the probability of producing preferred data. This provides theoretical insights for understanding the limitations of DPO discovered in the related research experiments, thereby setting the foundation for its improvement.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- This paper explores the theoretical limitations of Direct Preference Optimization (DPO), a technique used in training large language models and other AI systems.
- DPO aims to optimize models to align with human preferences, but the authors argue that this approach has inherent limitations that need to be understood.
- The paper provides a formal analysis of DPO, identifying key constraints and challenges that arise when trying to optimize models for human preferences.
Plain English Explanation
The paper looks at a technique called Direct Preference Optimization (DPO) that is used to train large AI models, like language models, to better align with human preferences. The key idea behind DPO is to directly optimize the model to match what humans prefer, rather than just trying to imitate human behavior.
However, the authors argue that DPO has some fundamental limitations that need to be understood. Even though the goal is to make the AI systems more aligned with human values, the authors show that there are inherent constraints and challenges that arise when trying to optimize models in this way.
The paper provides a detailed mathematical and theoretical analysis to unpack these limitations of DPO. The goal is to help researchers and developers have a better understanding of what DPO can and cannot do, so they can make more informed choices about how to train and deploy these AI systems.
Technical Explanation
The paper presents a formal analysis of the limitations of Direct Preference Optimization (DPO) for training large AI models, like language models, to be aligned with human preferences.
The authors start by laying out the key concepts and assumptions underpinning DPO. They define the DPO objective function, which aims to directly optimize the model to match human preferences as expressed through pairwise comparisons or rankings of model outputs.
The core of the paper is a set of theoretical results that identify fundamental constraints and tradeoffs in DPO. For example, the authors show that the DPO objective can only be optimized up to an additive constant, meaning there are inherent ambiguities in the resulting model preferences. They also prove that DPO cannot guarantee globally optimal model alignment with human values.
The authors further analyze the role of noise and uncertainty in the human preference data used to train DPO models. They demonstrate limitations in the model's ability to be robust to such noise, which is a critical concern for real-world deployment.
Overall, the technical analysis provides a rigorous theoretical foundation for understanding the strengths and weaknesses of DPO as a technique for aligning large AI models with human values and preferences.
Critical Analysis
The paper makes an important contribution by systematically analyzing the limitations of Direct Preference Optimization (DPO) from a theoretical perspective. This is valuable, as DPO is an increasingly popular technique for training AI systems to be more aligned with human values.
The authors' formal analysis uncovers several key constraints and challenges that arise when trying to optimize models using DPO. For example, the inability to guarantee globally optimal alignment, the ambiguity in the resulting preferences, and the model's sensitivity to noise in the human preference data.
These limitations are significant and deserve close attention from researchers and developers working on AI alignment. The authors are right to point out that understanding these theoretical boundaries is crucial for making informed decisions about when and how to apply DPO in practice.
At the same time, the paper does not explore potential mitigation strategies or alternative approaches that could address some of the identified limitations. It would be helpful to see a discussion of complementary techniques or extensions to DPO that could help overcome the problems raised.
Additionally, the paper focuses solely on the theoretical analysis, without validating the findings through empirical experiments. Rigorous testing of the proposed constraints in realistic settings would further strengthen the credibility of the work.
Overall, this is an important contribution that provides a solid foundation for thinking critically about the use of DPO in AI alignment research and development. The insights offered should prompt deeper consideration of the tradeoffs and challenges involved in this approach.
Conclusion
This paper offers a detailed theoretical analysis of the limitations of Direct Preference Optimization (DPO), a technique used to train large AI models to align with human values and preferences.
The authors identify several key constraints and challenges inherent to the DPO approach, including the inability to guarantee globally optimal model alignment, ambiguities in the resulting preferences, and sensitivity to noise in the human preference data.
These findings are significant, as DPO is increasingly being used to develop AI systems that are more in tune with human values. Understanding the theoretical boundaries of this technique is crucial for making informed decisions about its appropriate use and for exploring complementary approaches that could address the identified limitations.
While the paper is focused on the theoretical analysis, the insights provided should prompt further empirical research and the development of mitigation strategies to enhance the capabilities and robustness of DPO-based AI alignment efforts. Ultimately, this work contributes to a more nuanced and critical understanding of the challenges involved in aligning powerful AI systems with human values.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
Insights into Alignment: Evaluating DPO and its Variants Across Multiple Tasks
Amir Saeidi, Shivanshu Verma, Chitta Baral
0
0
Large Language Models (LLMs) have demonstrated remarkable performance across a spectrum of tasks. Recently, Direct Preference Optimization (DPO) has emerged as an RL-free approach to optimize the policy model on human preferences. However, several limitations hinder the widespread adoption of this method. To address these shortcomings, various versions of DPO have been introduced. Yet, a comprehensive evaluation of these variants across diverse tasks is still lacking. In this study, we aim to bridge this gap by investigating the performance of alignment methods across three distinct scenarios: (1) keeping the Supervised Fine-Tuning (SFT) part, (2) skipping the SFT part, and (3) skipping the SFT part and utilizing an instruction-tuned model. Furthermore, we explore the impact of different training sizes on their performance. Our evaluation spans a range of tasks including dialogue systems, reasoning, mathematical problem-solving, question answering, truthfulness, and multi-task understanding, encompassing 13 benchmarks such as MT-Bench, Big Bench, and Open LLM Leaderboard. Key observations reveal that alignment methods achieve optimal performance with smaller training data subsets, exhibit limited effectiveness in reasoning tasks yet significantly impact mathematical problem-solving, and employing an instruction-tuned model notably influences truthfulness. We anticipate that our findings will catalyze further research aimed at developing more robust models to address alignment challenges.
4/24/2024
Filtered Direct Preference Optimization
Tetsuro Morimura, Mitsuki Sakamoto, Yuu Jinnai, Kenshi Abe, Kaito Ariu
0
0
Reinforcement learning from human feedback (RLHF) plays a crucial role in aligning language models with human preferences. While the significance of dataset quality is generally recognized, explicit investigations into its impact within the RLHF framework, to our knowledge, have been limited. This paper addresses the issue of text quality within the preference dataset by focusing on Direct Preference Optimization (DPO), an increasingly adopted reward-model-free RLHF method. We confirm that text quality significantly influences the performance of models optimized with DPO more than those optimized with reward-model-based RLHF. Building on this new insight, we propose an extension of DPO, termed filtered direct preference optimization (fDPO). fDPO uses a trained reward model to monitor the quality of texts within the preference dataset during DPO training. Samples of lower quality are discarded based on comparisons with texts generated by the model being optimized, resulting in a more accurate dataset. Experimental results demonstrate that fDPO enhances the final model performance. Our code is available at https://github.com/CyberAgentAILab/filtered-dpo.
4/24/2024
Provably Robust DPO: Aligning Language Models with Noisy Feedback
Sayak Ray Chowdhury, Anush Kini, Nagarajan Natarajan
0
0
Learning from preference-based feedback has recently gained traction as a promising approach to align language models with human interests. While these aligned generative models have demonstrated impressive capabilities across various tasks, their dependence on high-quality human preference data poses a bottleneck in practical applications. Specifically, noisy (incorrect and ambiguous) preference pairs in the dataset might restrict the language models from capturing human intent accurately. While practitioners have recently proposed heuristics to mitigate the effect of noisy preferences, a complete theoretical understanding of their workings remain elusive. In this work, we aim to bridge this gap by by introducing a general framework for policy optimization in the presence of random preference flips. We focus on the direct preference optimization (DPO) algorithm in particular since it assumes that preferences adhere to the Bradley-Terry-Luce (BTL) model, raising concerns about the impact of noisy data on the learned policy. We design a novel loss function, which de-bias the effect of noise on average, making a policy trained by minimizing that loss robust to the noise. Under log-linear parameterization of the policy class and assuming good feature coverage of the SFT policy, we prove that the sub-optimality gap of the proposed robust DPO (rDPO) policy compared to the optimal policy is of the order $O(frac{1}{1-2epsilon}sqrt{frac{d}{n}})$, where $epsilon < 1/2$ is flip rate of labels, $d$ is policy parameter dimension and $n$ is size of dataset. Our experiments on IMDb sentiment generation and Anthropic's helpful-harmless dataset show that rDPO is robust to noise in preference labels compared to vanilla DPO and other heuristics proposed by practitioners.
4/15/2024

D2PO: Discriminator-Guided DPO with Response Evaluation Models
Prasann Singhal, Nathan Lambert, Scott Niekum, Tanya Goyal, Greg Durrett
0
0
Varied approaches for aligning language models have been proposed, including supervised fine-tuning, RLHF, and direct optimization methods such as DPO. Although DPO has rapidly gained popularity due to its straightforward training process and competitive results, there is an open question of whether there remain practical advantages of using a discriminator, like a reward model, to evaluate responses. We propose D2PO, discriminator-guided DPO, an approach for the online setting where preferences are being collected throughout learning. As we collect gold preferences, we use these not only to train our policy, but to train a discriminative response evaluation model to silver-label even more synthetic data for policy training. We explore this approach across a set of diverse tasks, including a realistic chat setting, we find that our approach leads to higher-quality outputs compared to DPO with the same data budget, and greater efficiency in terms of preference data requirements. Furthermore, we show conditions under which silver labeling is most helpful: it is most effective when training the policy with DPO, outperforming traditional PPO, and benefits from maintaining a separate discriminator from the policy model.
5/3/2024