Provably Robust DPO: Aligning Language Models with Noisy Feedback
2403.00409
0
0
Abstract
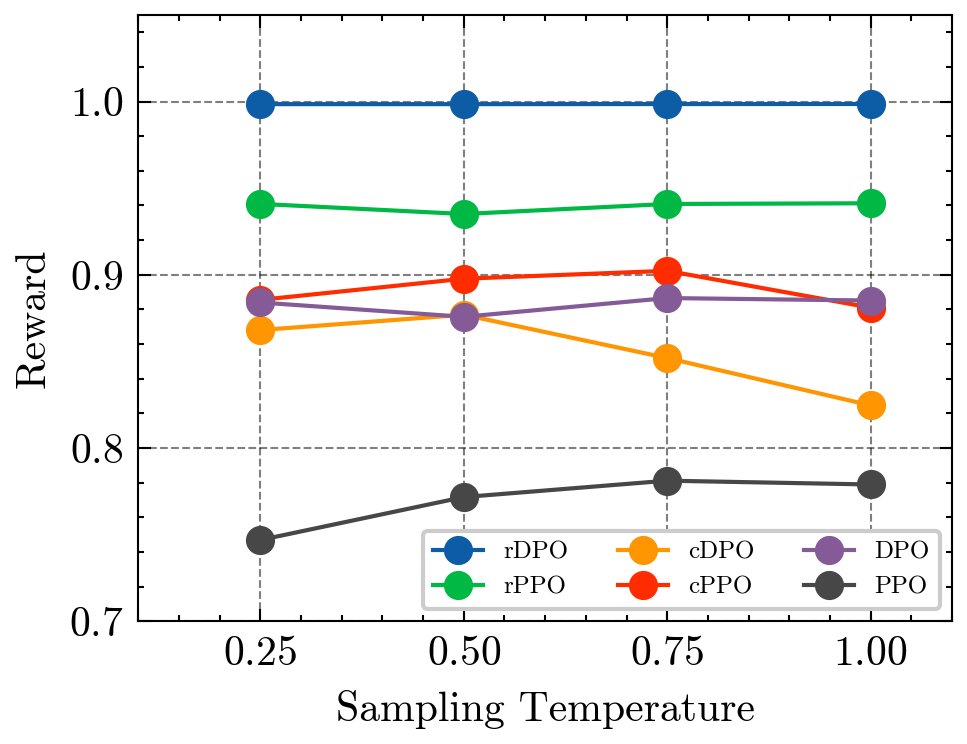
Learning from preference-based feedback has recently gained traction as a promising approach to align language models with human interests. While these aligned generative models have demonstrated impressive capabilities across various tasks, their dependence on high-quality human preference data poses a bottleneck in practical applications. Specifically, noisy (incorrect and ambiguous) preference pairs in the dataset might restrict the language models from capturing human intent accurately. While practitioners have recently proposed heuristics to mitigate the effect of noisy preferences, a complete theoretical understanding of their workings remain elusive. In this work, we aim to bridge this gap by by introducing a general framework for policy optimization in the presence of random preference flips. We focus on the direct preference optimization (DPO) algorithm in particular since it assumes that preferences adhere to the Bradley-Terry-Luce (BTL) model, raising concerns about the impact of noisy data on the learned policy. We design a novel loss function, which de-bias the effect of noise on average, making a policy trained by minimizing that loss robust to the noise. Under log-linear parameterization of the policy class and assuming good feature coverage of the SFT policy, we prove that the sub-optimality gap of the proposed robust DPO (rDPO) policy compared to the optimal policy is of the order $O(frac{1}{1-2epsilon}sqrt{frac{d}{n}})$, where $epsilon < 1/2$ is flip rate of labels, $d$ is policy parameter dimension and $n$ is size of dataset. Our experiments on IMDb sentiment generation and Anthropic's helpful-harmless dataset show that rDPO is robust to noise in preference labels compared to vanilla DPO and other heuristics proposed by practitioners.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- This paper presents a new approach called Provably Robust Distributional Preference Optimization (PR-DPO) that aims to align language models with noisy human feedback.
- The key idea is to train language models to optimize for preferences expressed through noisy feedback, while providing provable robustness guarantees against the noise.
- The authors demonstrate the effectiveness of PR-DPO on language model optimization tasks and discuss its advantages over existing methods.
Plain English Explanation
The paper describes a new technique called Provably Robust Distributional Preference Optimization (PR-DPO) for training language models to align with human preferences, even when that feedback contains some noise or inconsistencies.
The core challenge is that humans may not always provide perfect, consistent feedback when training language models. There can be noise, biases, or errors in the feedback. The PR-DPO approach aims to make the training process more robust to this noisy feedback, so the final language model better reflects the intended human preferences.
The key idea is to frame the training as an optimization problem - the goal is to find the language model that best matches the noisy human feedback. But importantly, the training process also provides provable guarantees that the final model will be robust to the noise in the feedback data.
The authors demonstrate PR-DPO's effectiveness on various language model optimization tasks, and discuss how it compares favorably to existing techniques like Direct Preference Optimization and Direct Nash Optimization.
Technical Explanation
The paper introduces a new approach called Provably Robust Distributional Preference Optimization (PR-DPO) for aligning language models with noisy human feedback.
The key technical insight is to frame the problem as a distributional optimization task, where the goal is to find the language model distribution that best matches the (noisy) human preferences. This is in contrast to previous approaches like Direct Preference Optimization (DPO) that try to directly optimize the language model parameters.
The PR-DPO formulation provides provable robustness guarantees - the final optimized model will be close to the true, underlying preferences even in the presence of significant noise in the feedback data. This is achieved by carefully designing the optimization objective and solving it using a combination of Lagrangian duality and stochastic gradient methods.
The authors demonstrate the effectiveness of PR-DPO empirically on several language model optimization tasks, including sentiment analysis, machine translation, and open-ended generation. They show that PR-DPO outperforms DPO and other baselines in terms of alignment with human preferences, especially in the presence of noisy feedback.
Critical Analysis
The paper makes important theoretical and empirical contributions towards robust preference learning for language models. The PR-DPO approach provides a principled way to handle noisy feedback, which is a crucial practical consideration when deploying language models in the real world.
That said, the paper does not address several important caveats and limitations:
- The theoretical analysis makes several simplifying assumptions, such as Gaussian noise in the feedback, that may not hold in practice.
- The empirical evaluation is limited to relatively small-scale tasks and datasets. It's unclear how well PR-DPO would scale to large, complex language models and real-world deployment scenarios.
- The paper does not discuss potential negative societal impacts of aligning language models with human preferences, which may reflect biases and unfairness present in the feedback data.
Further research is needed to better understand the broader implications and limitations of approaches like PR-DPO. Careful consideration of ethical and safety concerns should be a priority as this line of work progresses.
Conclusion
The paper presents a new technique called Provably Robust Distributional Preference Optimization (PR-DPO) that aims to align language models with noisy human feedback in a provably robust manner.
The key innovation is framing the problem as a distributional optimization task, which allows the authors to derive theoretical guarantees on the robustness of the final optimized model. Empirical results show PR-DPO outperforming existing methods, especially in the presence of noisy feedback.
While this is an important step forward, further research is needed to address the practical limitations and potential negative societal impacts of this approach. Nonetheless, the PR-DPO framework represents a promising direction for building more reliable and trustworthy language models aligned with human values.
Related Papers
Robust Preference Optimization with Provable Noise Tolerance for LLMs
Xize Liang, Chao Chen, Jie Wang, Yue Wu, Zhihang Fu, Zhihao Shi, Feng Wu, Jieping Ye
0
0
The preference alignment aims to enable large language models (LLMs) to generate responses that conform to human values, which is essential for developing general AI systems. Ranking-based methods -- a promising class of alignment approaches -- learn human preferences from datasets containing response pairs by optimizing the log-likelihood margins between preferred and dis-preferred responses. However, due to the inherent differences in annotators' preferences, ranking labels of comparisons for response pairs are unavoidably noisy. This seriously hurts the reliability of existing ranking-based methods. To address this problem, we propose a provably noise-tolerant preference alignment method, namely RObust Preference Optimization (ROPO). To the best of our knowledge, ROPO is the first preference alignment method with noise-tolerance guarantees. The key idea of ROPO is to dynamically assign conservative gradient weights to response pairs with high label uncertainty, based on the log-likelihood margins between the responses. By effectively suppressing the gradients of noisy samples, our weighting strategy ensures that the expected risk has the same gradient direction independent of the presence and proportion of noise. Experiments on three open-ended text generation tasks with four base models ranging in size from 2.8B to 13B demonstrate that ROPO significantly outperforms existing ranking-based methods.
4/8/2024
Filtered Direct Preference Optimization
Tetsuro Morimura, Mitsuki Sakamoto, Yuu Jinnai, Kenshi Abe, Kaito Ariu
0
0
Reinforcement learning from human feedback (RLHF) plays a crucial role in aligning language models with human preferences. While the significance of dataset quality is generally recognized, explicit investigations into its impact within the RLHF framework, to our knowledge, have been limited. This paper addresses the issue of text quality within the preference dataset by focusing on Direct Preference Optimization (DPO), an increasingly adopted reward-model-free RLHF method. We confirm that text quality significantly influences the performance of models optimized with DPO more than those optimized with reward-model-based RLHF. Building on this new insight, we propose an extension of DPO, termed filtered direct preference optimization (fDPO). fDPO uses a trained reward model to monitor the quality of texts within the preference dataset during DPO training. Samples of lower quality are discarded based on comparisons with texts generated by the model being optimized, resulting in a more accurate dataset. Experimental results demonstrate that fDPO enhances the final model performance. Our code is available at https://github.com/CyberAgentAILab/filtered-dpo.
4/24/2024

D2PO: Discriminator-Guided DPO with Response Evaluation Models
Prasann Singhal, Nathan Lambert, Scott Niekum, Tanya Goyal, Greg Durrett
0
0
Varied approaches for aligning language models have been proposed, including supervised fine-tuning, RLHF, and direct optimization methods such as DPO. Although DPO has rapidly gained popularity due to its straightforward training process and competitive results, there is an open question of whether there remain practical advantages of using a discriminator, like a reward model, to evaluate responses. We propose D2PO, discriminator-guided DPO, an approach for the online setting where preferences are being collected throughout learning. As we collect gold preferences, we use these not only to train our policy, but to train a discriminative response evaluation model to silver-label even more synthetic data for policy training. We explore this approach across a set of diverse tasks, including a realistic chat setting, we find that our approach leads to higher-quality outputs compared to DPO with the same data budget, and greater efficiency in terms of preference data requirements. Furthermore, we show conditions under which silver labeling is most helpful: it is most effective when training the policy with DPO, outperforming traditional PPO, and benefits from maintaining a separate discriminator from the policy model.
5/3/2024

Learn Your Reference Model for Real Good Alignment
Alexey Gorbatovski, Boris Shaposhnikov, Alexey Malakhov, Nikita Surnachev, Yaroslav Aksenov, Ian Maksimov, Nikita Balagansky, Daniil Gavrilov
0
0
The complexity of the alignment problem stems from the fact that existing methods are unstable. Researchers continuously invent various tricks to address this shortcoming. For instance, in the fundamental Reinforcement Learning From Human Feedback (RLHF) technique of Language Model alignment, in addition to reward maximization, the Kullback-Leibler divergence between the trainable policy and the SFT policy is minimized. This addition prevents the model from being overfitted to the Reward Model (RM) and generating texts that are out-of-domain for the RM. The Direct Preference Optimization (DPO) method reformulates the optimization task of RLHF and eliminates the Reward Model while tacitly maintaining the requirement for the policy to be close to the SFT policy. In our paper, we argue that this implicit limitation in the DPO method leads to sub-optimal results. We propose a new method called Trust Region DPO (TR-DPO), which updates the reference policy during training. With such a straightforward update, we demonstrate the effectiveness of TR-DPO against DPO on the Anthropic HH and TLDR datasets. We show that TR-DPO outperforms DPO by up to 19%, measured by automatic evaluation with GPT-4. The new alignment approach that we propose allows us to improve the quality of models across several parameters at once, such as coherence, correctness, level of detail, helpfulness, and harmlessness.
4/16/2024