Towards Avoiding the Data Mess: Industry Insights from Data Mesh Implementations

0
📊
Sign in to get full access
Overview
- Organizations are increasingly data-driven, but current data architectures struggle to keep up with the scale and scope of data and analytics needs.
- Data mesh is a novel concept for decentralized, distributed enterprise data management, but lacks empirical insights from industry.
- This research aims to understand the motivations, challenges, implementation strategies, business impact, and archetypes of data mesh adoption.
Plain English Explanation
As organizations rely more on data and artificial intelligence, they want to become more data-driven. However, their current data management systems are often not designed to handle the massive amounts of data and complex analytics requirements they now face. In fact, these existing architectures frequently fail to deliver the promised benefits.
Data mesh is a new approach to enterprise data management that is decentralized and distributed, rather than centralized. It's a socio-technical concept, meaning it involves both technological and organizational changes. Since data mesh is a relatively new idea, there isn't much real-world experience and insight available about how organizations are actually implementing it.
This research tries to fill that gap by interviewing 15 industry experts. The findings show that organizations struggle with the shift to shared responsibility for developing, providing, and maintaining "data products" under data mesh. They also have trouble fully understanding the overall concept.
The researchers provide some strategies that may help organizations implement data mesh more successfully. These include setting up a cross-domain steering committee, closely monitoring how data products are used, achieving quick wins early on, and using small, dedicated teams to prioritize data products. The paper also suggests two general "archetypes" or models that organizations could follow, while acknowledging that the specifics will vary based on each organization's needs.
Overall, this research offers preliminary guidance to help researchers and professionals navigate the adoption of the data mesh approach, which is becoming increasingly important as organizations strive to unlock more value from their data.
Technical Explanation
The researchers conducted 15 semi-structured interviews with industry experts to better understand the motivations, challenges, implementation strategies, business impact, and potential archetypes associated with adopting a data mesh approach to enterprise data management.
Key findings include:
- Organizations struggle with the transition to the federated governance model of data mesh, as well as the shift in responsibility for developing, providing, and maintaining "data products."
- There is often a lack of comprehension around the overall data mesh concept among stakeholders.
To address these challenges, the researchers suggest several implementation strategies:
- Introducing a cross-domain steering unit to coordinate data mesh efforts
- Closely observing how data products are used in practice
- Creating quick wins in the early phases of data mesh adoption
- Favoring small, dedicated teams that prioritize high-quality data products
The paper also proposes two general archetypes or models that organizations could follow when implementing data mesh, while acknowledging that the specific approach will depend on each organization's unique needs and context.
The researchers note that as the data mesh concept is still relatively new, their findings provide preliminary guidelines to help researchers and professionals navigate the successful adoption of this emerging approach to enterprise data management.
Critical Analysis
The researchers acknowledge that as the data mesh concept is still novel, there is a lack of empirical insights from real-world implementations. Their study relies on interviews with industry experts, which provide valuable qualitative data, but may not fully capture the nuances and complexities of data mesh adoption in practice.
Additionally, the proposed implementation strategies and archetypes are high-level and may require further refinement and validation as organizations continue to experiment with data mesh. The paper does not delve deeply into the technical details or architectural considerations of data mesh, which would be an important area for future research.
There is also an opportunity to explore the relationship between data mesh and other emerging data management and analytics paradigms, such as multi-source data fusion, federated analytics, and edge computing for data quality. Understanding how data mesh fits into the broader landscape of data-driven innovation could provide additional insights.
Overall, this research offers a valuable starting point for understanding the practical realities of data mesh adoption, but further empirical studies and deeper technical analysis will be necessary to fully realize the potential of this emerging data management paradigm.
Conclusion
As organizations strive to become more data-driven, the data mesh concept represents a novel approach to enterprise data management that aims to address the shortcomings of traditional, centralized architectures. This research provides preliminary insights into the motivations, challenges, and implementation strategies associated with data mesh adoption, based on interviews with industry experts.
The findings suggest that while data mesh offers promising benefits, organizations often struggle with the transition to a more federated governance model and the shift in responsibility for data products. The researchers propose several strategies to help overcome these challenges, as well as two potential archetypes for data mesh implementation.
These insights can serve as a starting point for researchers and professionals navigating the adoption of data mesh. However, as the concept is still relatively new, further empirical studies and technical analyses will be necessary to fully understand the long-term implications and best practices for successful data mesh implementation across diverse organizational contexts.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
📊
0
Towards Avoiding the Data Mess: Industry Insights from Data Mesh Implementations
Jan Bode, Niklas Kuhl, Dominik Kreuzberger, Sebastian Hirschl, Carsten Holtmann
With the increasing importance of data and artificial intelligence, organizations strive to become more data-driven. However, current data architectures are not necessarily designed to keep up with the scale and scope of data and analytics use cases. In fact, existing architectures often fail to deliver the promised value associated with them. Data mesh is a socio-technical, decentralized, distributed concept for enterprise data management. As the concept of data mesh is still novel, it lacks empirical insights from the field. Specifically, an understanding of the motivational factors for introducing data mesh, the associated challenges, implementation strategies, its business impact, and potential archetypes is missing. To address this gap, we conduct 15 semi-structured interviews with industry experts. Our results show, among other insights, that organizations have difficulties with the transition toward federated governance associated with the data mesh concept, the shift of responsibility for the development, provision, and maintenance of data products, and the comprehension of the overall concept. In our work, we derive multiple implementation strategies and suggest organizations introduce a cross-domain steering unit, observe the data product usage, create quick wins in the early phases, and favor small dedicated teams that prioritize data products. While we acknowledge that organizations need to apply implementation strategies according to their individual needs, we also deduct two archetypes that provide suggestions in more detail. Our findings synthesize insights from industry experts and provide researchers and professionals with preliminary guidelines for the successful adoption of data mesh.
Read more6/7/2024
✅
0
Service Mesh: Architectures, Applications, and Implementations
Behrooz Farkiani, Raj Jain
The scalability and flexibility of microservice architecture have led to major changes in cloud-native application architectures. However, the complexity of managing thousands of small services written in different languages and handling the exchange of data between them have caused significant management challenges. Service mesh is a promising solution that could mitigate these problems by introducing an overlay layer on top of the services. In this paper, we first study the architecture and components of service mesh architecture. Then, we review two important service mesh implementations and discuss how the service mesh could be helpful in other areas, including 5G.
Read more5/24/2024
📊
0
Data Issues in Industrial AI System: A Meta-Review and Research Strategy
Xuejiao Li, Cheng Yang, Charles M{o}ller, Jay Lee
In the era of Industry 4.0, artificial intelligence (AI) is assuming an increasingly pivotal role within industrial systems. Despite the recent trend within various industries to adopt AI, the actual adoption of AI is not as developed as perceived. A significant factor contributing to this lag is the data issues in AI implementation. How to address these data issues stands as a significant concern confronting both industry and academia. To address data issues, the first step involves mapping out these issues. Therefore, this study conducts a meta-review to explore data issues and methods within the implementation of industrial AI. Seventy-two data issues are identified and categorized into various stages of the data lifecycle, including data source and collection, data access and storage, data integration and interoperation, data pre-processing, data processing, data security and privacy, and AI technology adoption. Subsequently, the study analyzes the data requirements of various AI algorithms. Building on the aforementioned analyses, it proposes a data management framework, addressing how data issues can be systematically resolved at every stage of the data lifecycle. Finally, the study highlights future research directions. In doing so, this study enriches the existing body of knowledge and provides guidelines for professionals navigating the complex landscape of achieving data usability and usefulness in industrial AI.
Read more6/26/2024
0
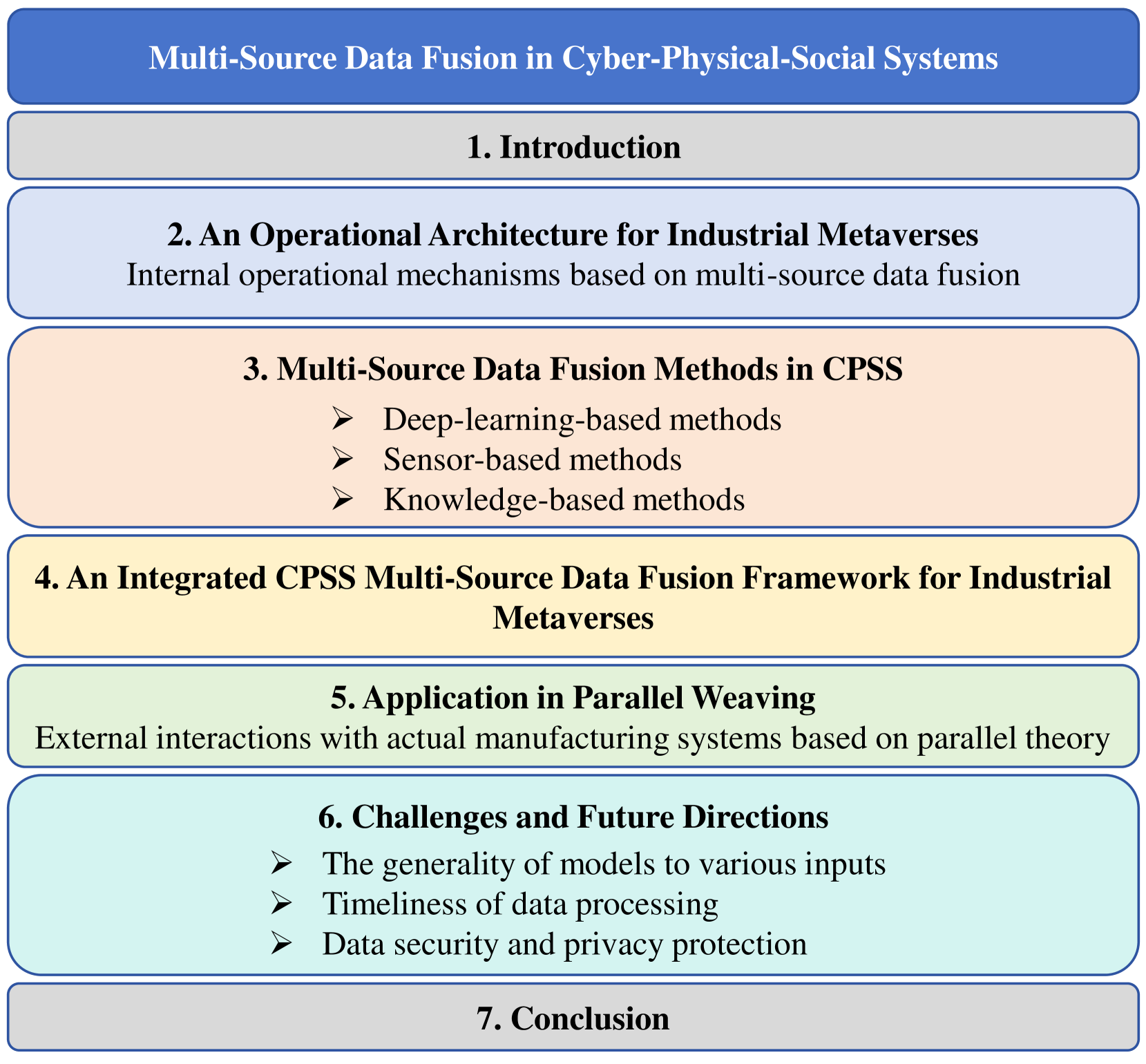
The Survey on Multi-Source Data Fusion in Cyber-Physical-Social Systems:Foundational Infrastructure for Industrial Metaverses and Industries 5.0
Xiao Wang, Yutong Wang, Jing Yang, Xiaofeng Jia, Lijun Li, Weiping Ding, Fei-Yue Wang
As the concept of Industries 5.0 develops, industrial metaverses are expected to operate in parallel with the actual industrial processes to offer ``Human-Centric Safe, Secure, Sustainable, Sensitive, Service, and Smartness ``6S manufacturing solutions. Industrial metaverses not only visualize the process of productivity in a dynamic and evolutional way, but also provide an immersive laboratory experimental environment for optimizing and remodeling the process. Besides, the customized user needs that are hidden in social media data can be discovered by social computing technologies, which introduces an input channel for building the whole social manufacturing process including industrial metaverses. This makes the fusion of multi-source data cross Cyber-Physical-Social Systems (CPSS) the foundational and key challenge. This work firstly proposes a multi-source-data-fusion-driven operational architecture for industrial metaverses on the basis of conducting a comprehensive literature review on the state-of-the-art multi-source data fusion methods. The advantages and disadvantages of each type of method are analyzed by considering the fusion mechanisms and application scenarios. Especially, we combine the strengths of deep learning and knowledge graphs in scalability and parallel computation to enable our proposed framework the ability of prescriptive optimization and evolution. This integration can address the shortcomings of deep learning in terms of explainability and fact fabrication, as well as overcoming the incompleteness and the challenges of construction and maintenance inherent in knowledge graphs. The effectiveness of the proposed architecture is validated through a parallel weaving case study. In the end, we discuss the challenges and future directions of multi-source data fusion cross CPSS for industrial metaverses and social manufacturing in Industries 5.0.
Read more4/12/2024