Towards a Brazilian History Knowledge Graph
2403.19856
1
0
🛠️
Abstract
This short paper describes the first steps in a project to construct a knowledge graph for Brazilian history based on the Brazilian Dictionary of Historical Biographies (DHBB) and Wikipedia/Wikidata. We contend that large repositories of Brazilian-named entities (people, places, organizations, and political events and movements) would be beneficial for extracting information from Portuguese texts. We show that many of the terms/entities described in the DHBB do not have corresponding concepts (or Q items) in Wikidata, the largest structured database of entities associated with Wikipedia. We describe previous work on extracting information from the DHBB and outline the steps to construct a Wikidata-based historical knowledge graph.
Get summaries of the top AI research delivered straight to your inbox:
Introduction
The paper discusses the task of automatically constructing a knowledge graph from text, with a specific focus on Brazilian recent history as described in the Dicionário Histórico Biográfico Brasileiro (DHBB), which is a Brazilian Historical-Biographical Dictionary. The authors aim to deploy recent natural language processing (NLP) techniques to process the DHBB corpus and develop a knowledge graph for Brazilian recent history.
Section 2 describes the DHBB dictionary and its maintenance over the years, explicitly stating the goal of the paper. Section 3 reports on previous works that applied NLP techniques to the DHBB. Section 4 discusses why the DHBB is maintained as a self-contained project at the Getulio Vargas Foundation, rather than being ingested into Wikipedia.
Section 5 presents the authors' strategy for mapping the titles of DHBB articles to Wikidata entries, highlighting the most relevant issues and evaluating their mapping approach. The paper concludes with final considerations in Section 6.
The DHBB corpus
The paper discusses the Brazilian Historical-Biographical Dictionary (DHBB), an encyclopedic resource providing organized and systematic information about notable personalities and events in recent Brazilian history. The DHBB covers the period starting from the "Revolução de 1930" (1930s Revolution), a significant political upheaval in Brazil.
The DHBB currently contains 7,863 entries, with over 6,800 biographies and around 1,000 thematic entries on institutions, organizations, and events. It was initiated and is maintained by CPDOC (Centro de Pesquisa e Documentação de História Contemporânea do Brasil), an organization within the Fundação Getúlio Vargas (FGV), dedicated to preserving historical documents and developing research tools for Brazilian cultural heritage.
The first edition of the DHBB was published in 1984, with major updates in 2010, 2014, and 2015. The 2010 update made the contents fully available online, while the 2014 update involved collaboration with researchers from the School of Applied Mathematics (EMAp) to store the contents in a GitHub repository.
The DHBB aims to provide objective and unbiased entries, avoiding ideological or personal judgments. CPDOC researchers carefully revise all entries to ensure accuracy and consistent style.
The thematic entries, which describe political parties, movements, organizations, events, constitutions, laws, and foreign relations topics, are of particular interest in this work. The goal is to ensure that named entities detected in the DHBB corpus are present in Wikidata, or else complete Wikidata to serve as a backbone for a Knowledge Graph for Brazilian History.
However, the authors were surprised to find that many named entities from the DHBB entry titles could not be automatically mapped to Wikidata, suggesting potential disambiguation challenges.
Previous work
The provided text discusses various computational linguistics research projects that utilize the Dictionary of the History of Brazil (DHBB) as a primary source of information about Brazilian history. It highlights the following key points:
- Early exploration of the DHBB using tools like FreeLing and OpenWN-PT, a Portuguese version of WordNet (De Paiva et al., 2014).
- Research on extracting semantic information from appositives in the DHBB (Higuchi et al., 2018).
- Distant reading of the DHBB corpus to extract information without reading individual entries, identifying around 48,500 persons, 27,500 organizations, 5,000 places, and 36,900 other named entities (Higuchi et al., 2019).
- Investigation of different tools and methods for detecting errors in the syntactical processing of the DHBB corpus, including differences in sentence segmentation and tokenization (Ribeiro et al., 2020).
- Exploration of topics like the age of entrance in Brazilian politics, academic backgrounds of politicians, and family ties among political elites using the DHBB corpus (Higuchi et al., 2022).
- Observation that existing lexical resources may lack terms specific to Brazilian culture, highlighting the need for culture-specific knowledge graphs (de Paiva et al., 2022).
The text emphasizes the DHBB as a valuable resource for computational linguistics research in understanding Brazilian history and culture, and the ongoing efforts to extract and analyze information from this vast corpus.
Wikipedia vs. Wikidata
The text discusses the origins and growth of Wikipedia, a free online encyclopedia written and maintained by volunteers. It highlights that while the English Wikipedia has over 6.7 million articles, other language editions like the Portuguese Wikipedia have significantly fewer articles despite Portuguese being the 8th most spoken language globally with around 263 million native speakers.
The text suggests that while not all Brazilian politicians and municipalities may be notable enough for individual Wikipedia pages, they should ideally be part of Wikidata, a structured knowledge base aiming to be as comprehensive as possible. The author aims to map named entities from the DHBB (a Brazilian history corpus) to Wikidata, starting with thematic and biographical entries using the wikimapper tool.
The text emphasizes that while the information in DHBB is of high quality, researchers may not want to replicate their work on Wikipedia due to copyright concerns. However, the entities (historical characters, locations, organizations, events) referenced in these works should be available in the structured format of Wikidata.
Mapping Historical Brazilian Entities
The paper discusses the challenges of mapping titles from the Digital Dictionary of Brazilian Biography (DHBB) to Wikidata, a free and open knowledge base. Key points:
-
Out of 973 thematic entry titles in the DHBB, only 498 (51%) could be mapped to Wikidata items automatically using existing tools.
-
Examples of problematic cases include entries for entities that no longer exist, sub-entities mentioned within larger Wikipedia pages, misspellings, and naming ambiguities.
-
For biographical entries (6,980 total), only 38% did not get an automatic Wikidata mapping. However, upon human evaluation, many of these mappings proved incorrect.
-
A random sample evaluation revealed around 30% of unmapped entries (thematic and biographical) could actually be found manually in Wikidata. Conversely, 16-34% of the automatic mappings were incorrect.
-
The authors aim to crowdsource improving the mappings and adding missing entries to Wikidata, an effort useful for preserving Brazilian historical knowledge.
-
Overall, Wikidata appears lacking in coverage of Brazilian entities, organizations, and events, necessitating significant manual effort to represent this information adequately.
Conclusion
The provided text highlights the importance of building knowledge graphs for academic subjects like contemporary Brazilian history and modern Brazilian art to preserve cultural heritage. Projects such as the DHBB (Digital Dictionary of Brazilian Biography) and the 'Enciclopédia Cultural Itaú' are valuable resources, but their information needs to be connected and structured to enable querying and reasoning.
Linking DHBB entries to Wikipedia and Wikidata can improve their visibility in search engine results and make the wealth of information more widely accessible. Currently, the information contained in DHBB is not being shared as widely as desired.
The proposed project aims to add DHBB information to Wikidata, making it more broadly available. This approach is presented as a straightforward way to enhance the dissemination of this cultural knowledge.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Cross-Data Knowledge Graph Construction for LLM-enabled Educational Question-Answering System: A~Case~Study~at~HCMUT
Tuan Bui, Oanh Tran, Phuong Nguyen, Bao Ho, Long Nguyen, Thang Bui, Tho Quan
0
0
In today's rapidly evolving landscape of Artificial Intelligence, large language models (LLMs) have emerged as a vibrant research topic. LLMs find applications in various fields and contribute significantly. Despite their powerful language capabilities, similar to pre-trained language models (PLMs), LLMs still face challenges in remembering events, incorporating new information, and addressing domain-specific issues or hallucinations. To overcome these limitations, researchers have proposed Retrieval-Augmented Generation (RAG) techniques, some others have proposed the integration of LLMs with Knowledge Graphs (KGs) to provide factual context, thereby improving performance and delivering more accurate feedback to user queries. Education plays a crucial role in human development and progress. With the technology transformation, traditional education is being replaced by digital or blended education. Therefore, educational data in the digital environment is increasing day by day. Data in higher education institutions are diverse, comprising various sources such as unstructured/structured text, relational databases, web/app-based API access, etc. Constructing a Knowledge Graph from these cross-data sources is not a simple task. This article proposes a method for automatically constructing a Knowledge Graph from multiple data sources and discusses some initial applications (experimental trials) of KG in conjunction with LLMs for question-answering tasks.
4/16/2024
BanglaAutoKG: Automatic Bangla Knowledge Graph Construction with Semantic Neural Graph Filtering
Azmine Toushik Wasi, Taki Hasan Rafi, Raima Islam, Dong-Kyu Chae
0
0
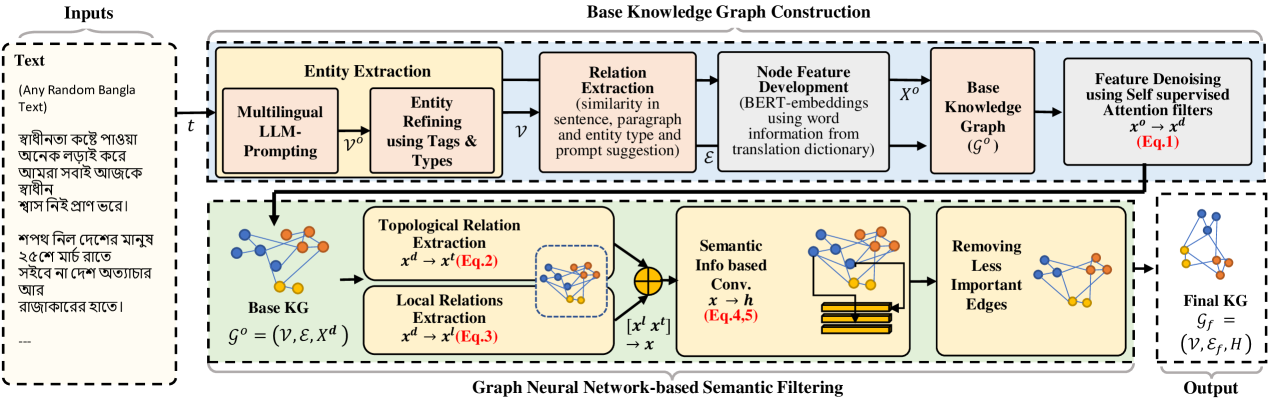
Knowledge Graphs (KGs) have proven essential in information processing and reasoning applications because they link related entities and give context-rich information, supporting efficient information retrieval and knowledge discovery; presenting information flow in a very effective manner. Despite being widely used globally, Bangla is relatively underrepresented in KGs due to a lack of comprehensive datasets, encoders, NER (named entity recognition) models, POS (part-of-speech) taggers, and lemmatizers, hindering efficient information processing and reasoning applications in the language. Addressing the KG scarcity in Bengali, we propose BanglaAutoKG, a pioneering framework that is able to automatically construct Bengali KGs from any Bangla text. We utilize multilingual LLMs to understand various languages and correlate entities and relations universally. By employing a translation dictionary to identify English equivalents and extracting word features from pre-trained BERT models, we construct the foundational KG. To reduce noise and align word embeddings with our goal, we employ graph-based polynomial filters. Lastly, we implement a GNN-based semantic filter, which elevates contextual understanding and trims unnecessary edges, culminating in the formation of the definitive KG. Empirical findings and case studies demonstrate the universal effectiveness of our model, capable of autonomously constructing semantically enriched KGs from any text.
4/8/2024
Automated Construction of Theme-specific Knowledge Graphs
Linyi Ding, Sizhe Zhou, Jinfeng Xiao, Jiawei Han
0
0
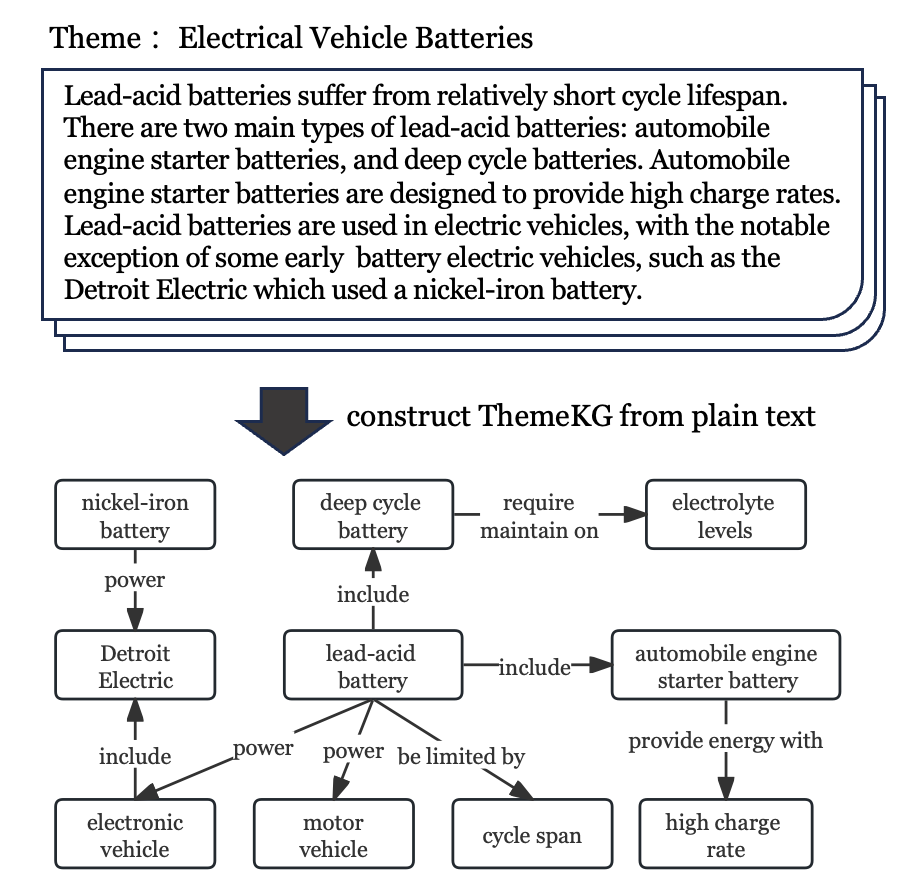
Despite widespread applications of knowledge graphs (KGs) in various tasks such as question answering and intelligent conversational systems, existing KGs face two major challenges: information granularity and deficiency in timeliness. These hinder considerably the retrieval and analysis of in-context, fine-grained, and up-to-date knowledge from KGs, particularly in highly specialized themes (e.g., specialized scientific research) and rapidly evolving contexts (e.g., breaking news or disaster tracking). To tackle such challenges, we propose a theme-specific knowledge graph (i.e., ThemeKG), a KG constructed from a theme-specific corpus, and design an unsupervised framework for ThemeKG construction (named TKGCon). The framework takes raw theme-specific corpus and generates a high-quality KG that includes salient entities and relations under the theme. Specifically, we start with an entity ontology of the theme from Wikipedia, based on which we then generate candidate relations by Large Language Models (LLMs) to construct a relation ontology. To parse the documents from the theme corpus, we first map the extracted entity pairs to the ontology and retrieve the candidate relations. Finally, we incorporate the context and ontology to consolidate the relations for entity pairs. We observe that directly prompting GPT-4 for theme-specific KG leads to inaccurate entities (such as two main types as one entity in the query result) and unclear (such as is, has) or wrong relations (such as have due to, to start). In contrast, by constructing the theme-specific KG step by step, our model outperforms GPT-4 and could consistently identify accurate entities and relations. Experimental results also show that our framework excels in evaluations compared with various KG construction baselines.
5/1/2024
Harmonizing Human Insights and AI Precision: Hand in Hand for Advancing Knowledge Graph Task
Shurong Wang, Yufei Zhang, Xuliang Huang, Hongwei Wang
0
0
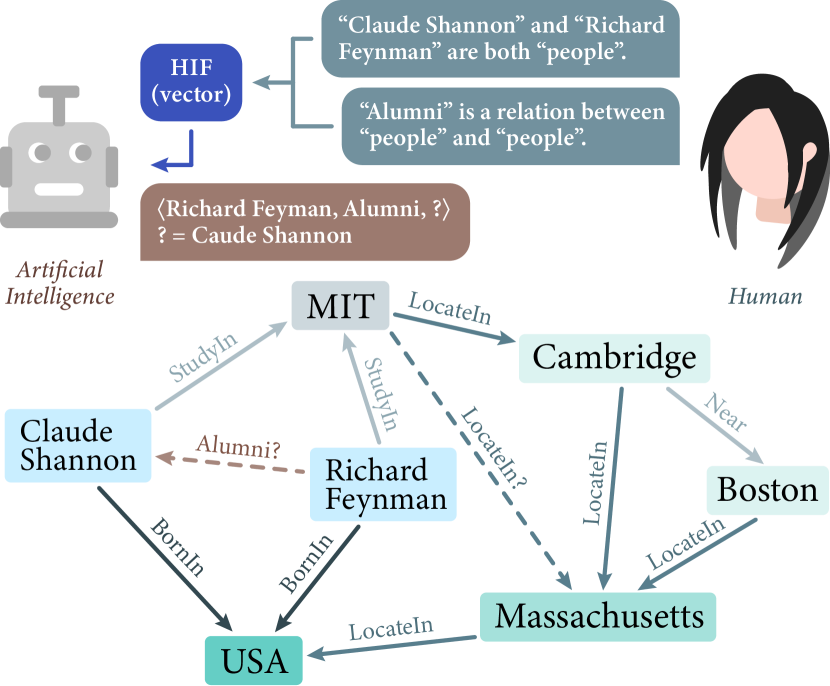
Knowledge graph embedding (KGE) has caught significant interest for its effectiveness in knowledge graph completion (KGC), specifically link prediction (LP), with recent KGE models cracking the LP benchmarks. Despite the rapidly growing literature, insufficient attention has been paid to the cooperation between humans and AI on KG. However, humans' capability to analyze graphs conceptually may further improve the efficacy of KGE models with semantic information. To this effect, we carefully designed a human-AI team (HAIT) system dubbed KG-HAIT, which harnesses the human insights on KG by leveraging fully human-designed ad-hoc dynamic programming (DP) on KG to produce human insightful feature (HIF) vectors that capture the subgraph structural feature and semantic similarities. By integrating HIF vectors into the training of KGE models, notable improvements are observed across various benchmarks and metrics, accompanied by accelerated model convergence. Our results underscore the effectiveness of human-designed DP in the task of LP, emphasizing the pivotal role of collaboration between humans and AI on KG. We open avenues for further exploration and innovation through KG-HAIT, paving the way towards more effective and insightful KG analysis techniques.
5/16/2024