BanglaAutoKG: Automatic Bangla Knowledge Graph Construction with Semantic Neural Graph Filtering
2404.03528
0
0
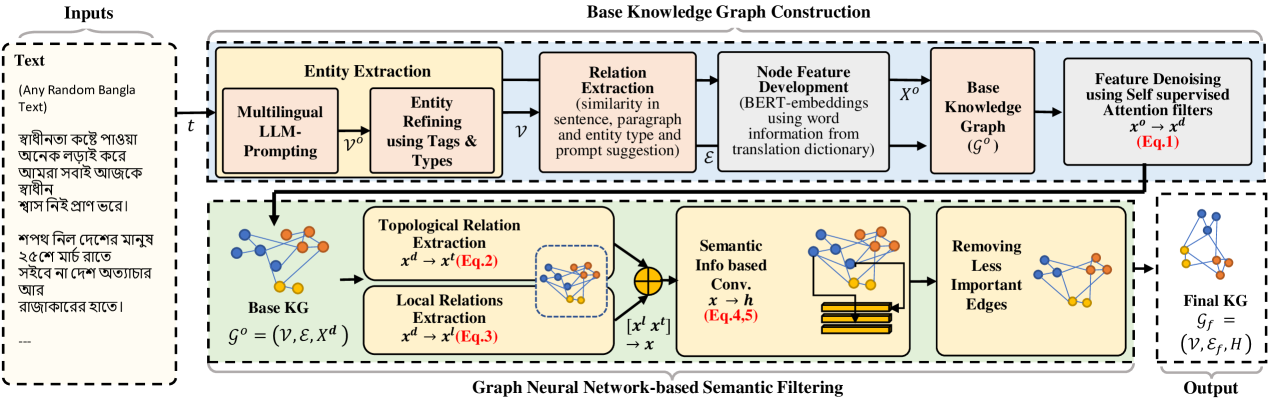
Abstract
Knowledge Graphs (KGs) have proven essential in information processing and reasoning applications because they link related entities and give context-rich information, supporting efficient information retrieval and knowledge discovery; presenting information flow in a very effective manner. Despite being widely used globally, Bangla is relatively underrepresented in KGs due to a lack of comprehensive datasets, encoders, NER (named entity recognition) models, POS (part-of-speech) taggers, and lemmatizers, hindering efficient information processing and reasoning applications in the language. Addressing the KG scarcity in Bengali, we propose BanglaAutoKG, a pioneering framework that is able to automatically construct Bengali KGs from any Bangla text. We utilize multilingual LLMs to understand various languages and correlate entities and relations universally. By employing a translation dictionary to identify English equivalents and extracting word features from pre-trained BERT models, we construct the foundational KG. To reduce noise and align word embeddings with our goal, we employ graph-based polynomial filters. Lastly, we implement a GNN-based semantic filter, which elevates contextual understanding and trims unnecessary edges, culminating in the formation of the definitive KG. Empirical findings and case studies demonstrate the universal effectiveness of our model, capable of autonomously constructing semantically enriched KGs from any text.
Create account to get full access
Overview
- This research paper, titled "BanglaAutoKG: Automatic Bangla Knowledge Graph Construction with Semantic Neural Graph Filtering", presents a method for automatically constructing a knowledge graph for the Bangla language.
- The knowledge graph is a structured representation of knowledge that can be used for various applications, such as question answering, information retrieval, and recommender systems.
- The proposed approach, BanglaAutoKG, combines natural language processing techniques with semantic neural graph filtering to extract entities, relations, and facts from Bangla text and organize them into a knowledge graph.
Plain English Explanation
The paper describes a system that can automatically build a knowledge graph for the Bangla language. A knowledge graph is a way of organizing information in a structured format, like a map of related concepts and how they connect. This can be useful for a variety of applications, like helping computers better understand and respond to questions.
The BanglaAutoKG system takes Bangla text as input and uses natural language processing techniques to identify the key entities (like people, places, or things) and the relationships between them. It then uses a "semantic neural graph filtering" approach to organize this information into a coherent knowledge graph. This helps ensure the graph captures the meaning and context of the information, not just the raw facts.
The goal is to make it easier to work with Bangla language data and enable new AI-powered applications that can understand and reason about Bangla language and knowledge. This could be beneficial for Bangla-speaking communities and researchers working on Bangla language technologies.
Technical Explanation
The BanglaAutoKG system consists of three main components: entity extraction, relation extraction, and semantic neural graph filtering.
The entity extraction component uses natural language processing techniques like named entity recognition to identify key entities mentioned in the Bangla text. The relation extraction component then analyzes the text to determine how these entities are related to one another, extracting the relevant relationships.
The novel contribution of this work is the semantic neural graph filtering component. This takes the extracted entities and relations and organizes them into a knowledge graph structure. It does this by using a neural network model to evaluate the semantic coherence and plausibility of the connections between entities. This helps ensure the final knowledge graph captures the underlying meaning and context, not just superficial associations.
The authors evaluate their approach on a Bangla corpus and show that BanglaAutoKG outperforms baseline methods in constructing a high-quality knowledge graph. This demonstrates the value of incorporating semantic understanding into the knowledge graph construction process.
Critical Analysis
The paper provides a thorough technical description of the BanglaAutoKG system and its components. However, there are a few potential limitations and areas for further exploration:
-
The evaluation is limited to a single Bangla corpus, so the generalizability of the approach to other Bangla language domains is unclear. Expanding the evaluation to additional datasets could help assess the robustness of the system.
-
The authors do not provide a detailed error analysis or discussion of failure cases. Understanding the types of errors the system makes and their root causes could inform future improvements.
-
While the semantic neural graph filtering is an innovative contribution, the paper does not extensively compare it to alternative knowledge graph construction techniques, such as knowledge-aware recommender systems or LLM-based knowledge extraction frameworks. A more comprehensive benchmarking against state-of-the-art methods could better situate the strengths and limitations of this approach.
Overall, the BanglaAutoKG system represents a promising step towards more robust and semantically-grounded knowledge graph construction for the Bangla language. Further research and evaluation could help solidify its position as a valuable tool for Bangla language AI applications.
Conclusion
This paper presents BanglaAutoKG, a novel system for automatically constructing a knowledge graph from Bangla text. The key innovation is the use of semantic neural graph filtering to organize the extracted entities and relations in a way that captures the underlying meaning and context, not just surface-level associations.
The authors demonstrate the effectiveness of this approach through evaluations on a Bangla corpus, showing that BanglaAutoKG outperforms baseline methods. This work has important implications for developing knowledge-powered AI applications for Bangla-speaking communities, such as question answering, information retrieval, and recommender systems.
While the paper provides a solid technical foundation, further research is needed to assess the generalizability of the approach, understand its failure modes, and benchmark it against alternative knowledge graph construction techniques. Nonetheless, BanglaAutoKG represents a significant step forward in building robust, semantically-grounded knowledge representations for the Bangla language.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🛸
Accelerating Medical Knowledge Discovery through Automated Knowledge Graph Generation and Enrichment
Mutahira Khalid, Raihana Rahman, Asim Abbas, Sushama Kumari, Iram Wajahat, Syed Ahmad Chan Bukhari
0
0
Knowledge graphs (KGs) serve as powerful tools for organizing and representing structured knowledge. While their utility is widely recognized, challenges persist in their automation and completeness. Despite efforts in automation and the utilization of expert-created ontologies, gaps in connectivity remain prevalent within KGs. In response to these challenges, we propose an innovative approach termed ``Medical Knowledge Graph Automation (M-KGA). M-KGA leverages user-provided medical concepts and enriches them semantically using BioPortal ontologies, thereby enhancing the completeness of knowledge graphs through the integration of pre-trained embeddings. Our approach introduces two distinct methodologies for uncovering hidden connections within the knowledge graph: a cluster-based approach and a node-based approach. Through rigorous testing involving 100 frequently occurring medical concepts in Electronic Health Records (EHRs), our M-KGA framework demonstrates promising results, indicating its potential to address the limitations of existing knowledge graph automation techniques.
5/7/2024
Automated Construction of Theme-specific Knowledge Graphs
Linyi Ding, Sizhe Zhou, Jinfeng Xiao, Jiawei Han
0
0
Despite widespread applications of knowledge graphs (KGs) in various tasks such as question answering and intelligent conversational systems, existing KGs face two major challenges: information granularity and deficiency in timeliness. These hinder considerably the retrieval and analysis of in-context, fine-grained, and up-to-date knowledge from KGs, particularly in highly specialized themes (e.g., specialized scientific research) and rapidly evolving contexts (e.g., breaking news or disaster tracking). To tackle such challenges, we propose a theme-specific knowledge graph (i.e., ThemeKG), a KG constructed from a theme-specific corpus, and design an unsupervised framework for ThemeKG construction (named TKGCon). The framework takes raw theme-specific corpus and generates a high-quality KG that includes salient entities and relations under the theme. Specifically, we start with an entity ontology of the theme from Wikipedia, based on which we then generate candidate relations by Large Language Models (LLMs) to construct a relation ontology. To parse the documents from the theme corpus, we first map the extracted entity pairs to the ontology and retrieve the candidate relations. Finally, we incorporate the context and ontology to consolidate the relations for entity pairs. We observe that directly prompting GPT-4 for theme-specific KG leads to inaccurate entities (such as two main types as one entity in the query result) and unclear (such as is, has) or wrong relations (such as have due to, to start). In contrast, by constructing the theme-specific KG step by step, our model outperforms GPT-4 and could consistently identify accurate entities and relations. Experimental results also show that our framework excels in evaluations compared with various KG construction baselines.
5/1/2024

Leveraging Large Language Models for Semantic Query Processing in a Scholarly Knowledge Graph
Runsong Jia, Bowen Zhang, Sergio J. Rodr'iguez M'endez, Pouya G. Omran
0
0
The proposed research aims to develop an innovative semantic query processing system that enables users to obtain comprehensive information about research works produced by Computer Science (CS) researchers at the Australian National University (ANU). The system integrates Large Language Models (LLMs) with the ANU Scholarly Knowledge Graph (ASKG), a structured repository of all research-related artifacts produced at ANU in the CS field. Each artifact and its parts are represented as textual nodes stored in a Knowledge Graph (KG). To address the limitations of traditional scholarly KG construction and utilization methods, which often fail to capture fine-grained details, we propose a novel framework that integrates the Deep Document Model (DDM) for comprehensive document representation and the KG-enhanced Query Processing (KGQP) for optimized complex query handling. DDM enables a fine-grained representation of the hierarchical structure and semantic relationships within academic papers, while KGQP leverages the KG structure to improve query accuracy and efficiency with LLMs. By combining the ASKG with LLMs, our approach enhances knowledge utilization and natural language understanding capabilities. The proposed system employs an automatic LLM-SPARQL fusion to retrieve relevant facts and textual nodes from the ASKG. Initial experiments demonstrate that our framework is superior to baseline methods in terms of accuracy retrieval and query efficiency. We showcase the practical application of our framework in academic research scenarios, highlighting its potential to revolutionize scholarly knowledge management and discovery. This work empowers researchers to acquire and utilize knowledge from documents more effectively and provides a foundation for developing precise and reliable interactions with LLMs.
5/27/2024

Cross-Data Knowledge Graph Construction for LLM-enabled Educational Question-Answering System: A~Case~Study~at~HCMUT
Tuan Bui, Oanh Tran, Phuong Nguyen, Bao Ho, Long Nguyen, Thang Bui, Tho Quan
0
0
In today's rapidly evolving landscape of Artificial Intelligence, large language models (LLMs) have emerged as a vibrant research topic. LLMs find applications in various fields and contribute significantly. Despite their powerful language capabilities, similar to pre-trained language models (PLMs), LLMs still face challenges in remembering events, incorporating new information, and addressing domain-specific issues or hallucinations. To overcome these limitations, researchers have proposed Retrieval-Augmented Generation (RAG) techniques, some others have proposed the integration of LLMs with Knowledge Graphs (KGs) to provide factual context, thereby improving performance and delivering more accurate feedback to user queries. Education plays a crucial role in human development and progress. With the technology transformation, traditional education is being replaced by digital or blended education. Therefore, educational data in the digital environment is increasing day by day. Data in higher education institutions are diverse, comprising various sources such as unstructured/structured text, relational databases, web/app-based API access, etc. Constructing a Knowledge Graph from these cross-data sources is not a simple task. This article proposes a method for automatically constructing a Knowledge Graph from multiple data sources and discusses some initial applications (experimental trials) of KG in conjunction with LLMs for question-answering tasks.
4/16/2024