Towards Democratizing Multilingual Large Language Models For Medicine Through A Two-Stage Instruction Fine-tuning Approach

0

Sign in to get full access
Overview
- This paper proposes a two-stage instruction fine-tuning approach to democratize multilingual large language models (LLMs) for medical applications.
- The researchers aimed to make high-quality multilingual LLMs accessible to a broader audience, including those without large compute resources or specialized ML expertise.
- The approach involves first fine-tuning an LLM on general language understanding tasks, then further fine-tuning it on domain-specific medical tasks.
Plain English Explanation
The researchers wanted to make powerful language models that can understand and work with multiple languages more widely available for use in medical applications. These large language models (LLMs) are incredibly capable, but they often require significant computing power and specialized machine learning knowledge to use effectively.
To address this, the researchers developed a two-stage approach to fine-tune these LLMs. First, they would fine-tune the models on general language understanding tasks to improve their basic abilities. Then, they would fine-tune them again, this time on domain-specific medical tasks, to give them specialized medical knowledge and capabilities.
The goal was to create multilingual LLMs that could be more easily accessed and used by a broader range of people, including those without extensive machine learning expertise or access to powerful computing resources. This could help democratize the use of these advanced language technologies in important medical applications.
Technical Explanation
The paper's key technical contributions are:
-
A two-stage instruction fine-tuning approach to train multilingual LLMs for medical applications:
- Stage 1: Fine-tune the LLM on general language understanding tasks to improve its core capabilities.
- Stage 2: Further fine-tune the LLM on domain-specific medical tasks to imbue it with specialized medical knowledge and skills.
-
Experiments demonstrating the effectiveness of this approach on several multilingual LLM architectures, including mT5 and mBERT.
-
An analysis of the performance and efficiency gains achieved through this two-stage fine-tuning, making these powerful language models more accessible to a broader user base.
Critical Analysis
The researchers acknowledge several caveats and areas for further research in their paper:
- The efficacy of the two-stage approach may vary depending on the specific LLM architecture and the availability of high-quality domain-specific training data.
- The paper focuses on general medical applications, but the approach may need to be adapted for more specialized medical domains (e.g., radiology, pathology).
- The researchers did not explore the potential fairness and bias issues that could arise from using large, powerful language models, even with domain-specific fine-tuning.
Additionally, one could question whether the proposed approach truly "democratizes" access to these LLMs, as it still requires significant computational resources and ML expertise to implement the two-stage fine-tuning process. Further research may be needed to explore more accessible ways of leveraging these advanced language technologies for medical applications.
Conclusion
This paper presents a promising two-stage instruction fine-tuning approach to make high-quality multilingual large language models more accessible for medical applications. By first improving the models' general language understanding and then fine-tuning them on domain-specific medical tasks, the researchers aimed to create powerful yet more widely usable language technologies.
If successful, this work could help expand the adoption of advanced language models in important medical domains, potentially leading to improved clinical decision support, more efficient medical documentation, and better patient outcomes. However, the researchers acknowledge the need to further address potential limitations and biases in their approach.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Towards Democratizing Multilingual Large Language Models For Medicine Through A Two-Stage Instruction Fine-tuning Approach
Meng Zhou, Surajsinh Parmar, Anubhav Bhatti
Open-source, multilingual medical large language models (LLMs) have the potential to serve linguistically diverse populations across different regions. Adapting generic LLMs for healthcare often requires continual pretraining, but this approach is computationally expensive and sometimes impractical. Instruction fine-tuning on a specific task may not always guarantee optimal performance due to the lack of broader domain knowledge that the model needs to understand and reason effectively in diverse scenarios. To address these challenges, we introduce two multilingual instruction fine-tuning datasets, MMed-IFT and MMed-IFT-MC, containing over 200k high-quality medical samples in six languages. We propose a two-stage training paradigm: the first stage injects general medical knowledge using MMed-IFT, while the second stage fine-tunes task-specific multiple-choice questions with MMed-IFT-MC. Our method achieves competitive results on both English and multilingual benchmarks, striking a balance between computational efficiency and performance. We plan to make our dataset and model weights public at url{https://github.com/SpassMed/Med-Llama3} in the future.
Read more9/10/2024
💬
0
Instruction-tuned Large Language Models for Machine Translation in the Medical Domain
Miguel Rios
Large Language Models (LLMs) have shown promising results on machine translation for high resource language pairs and domains. However, in specialised domains (e.g. medical) LLMs have shown lower performance compared to standard neural machine translation models. The consistency in the machine translation of terminology is crucial for users, researchers, and translators in specialised domains. In this study, we compare the performance between baseline LLMs and instruction-tuned LLMs in the medical domain. In addition, we introduce terminology from specialised medical dictionaries into the instruction formatted datasets for fine-tuning LLMs. The instruction-tuned LLMs significantly outperform the baseline models with automatic metrics.
Read more8/30/2024
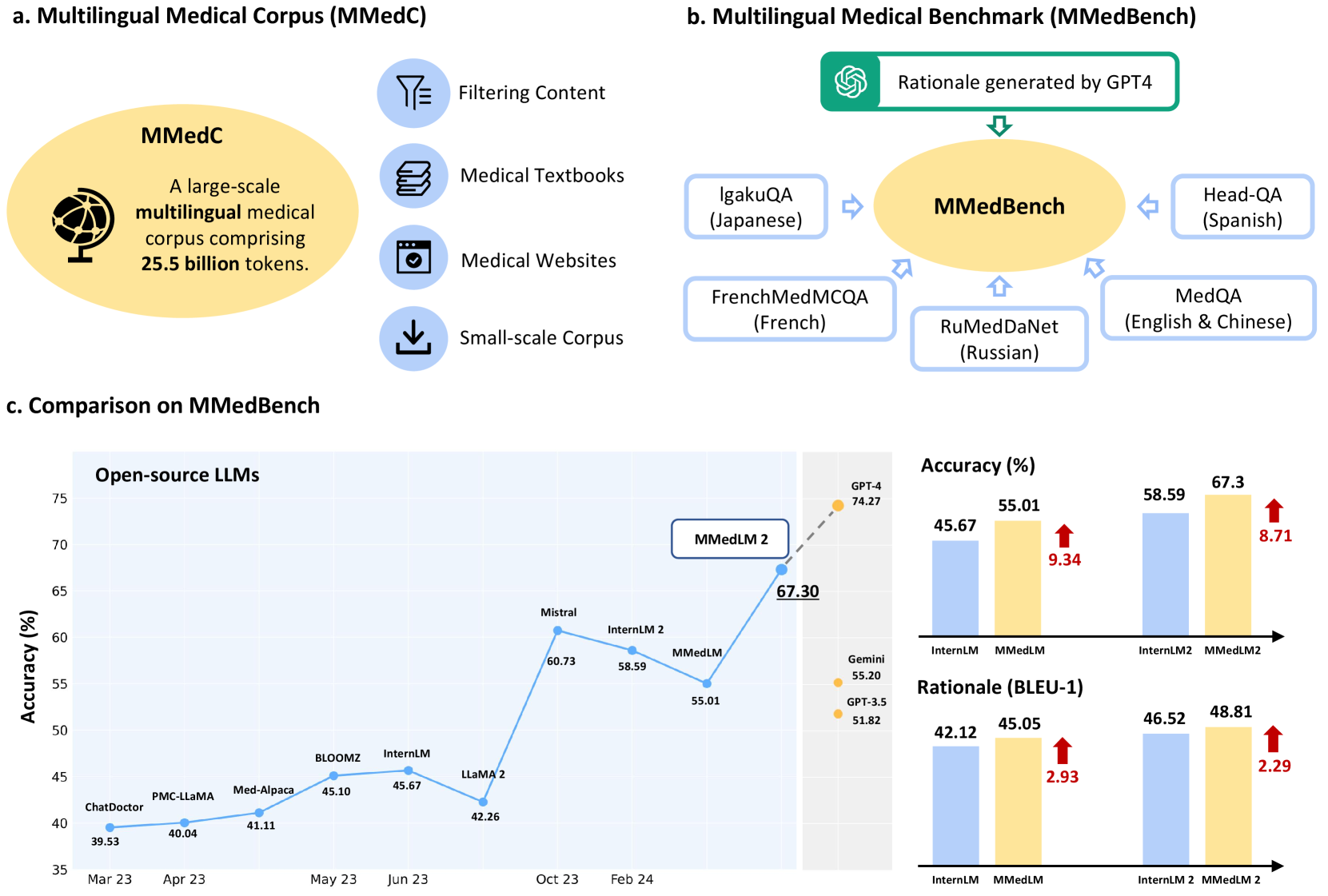
0
Towards Building Multilingual Language Model for Medicine
Pengcheng Qiu, Chaoyi Wu, Xiaoman Zhang, Weixiong Lin, Haicheng Wang, Ya Zhang, Yanfeng Wang, Weidi Xie
The development of open-source, multilingual medical language models can benefit a wide, linguistically diverse audience from different regions. To promote this domain, we present contributions from the following: First, we construct a multilingual medical corpus, containing approximately 25.5B tokens encompassing 6 main languages, termed as MMedC, enabling auto-regressive domain adaptation for general LLMs; Second, to monitor the development of multilingual medical LLMs, we propose a multilingual medical multi-choice question-answering benchmark with rationale, termed as MMedBench; Third, we have assessed a number of open-source large language models (LLMs) on our benchmark, along with those further auto-regressive trained on MMedC. Our final model, MMed-Llama 3, with only 8B parameters, achieves superior performance compared to all other open-source models on both MMedBench and English benchmarks, even rivaling GPT-4. In conclusion, in this work, we present a large-scale corpus, a benchmark and a series of models to support the development of multilingual medical LLMs.
Read more6/4/2024

0
Can LLMs' Tuning Methods Work in Medical Multimodal Domain?
Jiawei Chen, Yue Jiang, Dingkang Yang, Mingcheng Li, Jinjie Wei, Ziyun Qian, Lihua Zhang
While Large Language Models (LLMs) excel in world knowledge understanding, adapting them to specific subfields requires precise adjustments. Due to the model's vast scale, traditional global fine-tuning methods for large models can be computationally expensive and impact generalization. To address this challenge, a range of innovative Parameters-Efficient Fine-Tuning (PEFT) methods have emerged and achieved remarkable success in both LLMs and Large Vision-Language Models (LVLMs). In the medical domain, fine-tuning a medical Vision-Language Pretrained (VLP) model is essential for adapting it to specific tasks. Can the fine-tuning methods for large models be transferred to the medical field to enhance transfer learning efficiency? In this paper, we delve into the fine-tuning methods of LLMs and conduct extensive experiments to investigate the impact of fine-tuning methods for large models on the existing multimodal model in the medical domain from the training data level and the model structure level. We show the different impacts of fine-tuning methods for large models on medical VLMs and develop the most efficient ways to fine-tune medical VLP models. We hope this research can guide medical domain researchers in optimizing VLMs' training costs, fostering the broader application of VLMs in healthcare fields. The code and dataset have been released at https://github.com/TIMMY-CHAN/MILE.
Read more7/9/2024