Towards Enhancing Coherence in Extractive Summarization: Dataset and Experiments with LLMs

0

Sign in to get full access
Overview
This paper introduces a new dataset and experiments to enhance the coherence of extractive summarization using large language models (LLMs). Extractive summarization is the process of selecting and combining the most important sentences from a document to create a concise summary. The authors argue that current extractive summarization models often produce incoherent summaries, and they aim to address this issue.
Plain English Explanation
The researchers created a new dataset to train and evaluate extractive summarization models that produce more coherent summaries. Coherence refers to how well the sentences in a summary flow together and make sense as a whole.
The key innovations in this work are:
-
They developed a new dataset called LAMSUM that contains human-written summaries annotated for coherence. This allows them to train and evaluate models on coherence.
-
They conducted experiments using different LLM-based approaches to enhance the coherence of extractive summaries, including fine-tuning models on the LAMSUM dataset.
The goal is to create extractive summarization systems that generate summaries that are not just informative, but also flow logically and read naturally. This could make the summaries more useful for tasks like academic research, news reporting, and other applications where coherence is important.
Technical Explanation
The authors first constructed the LAMSUM dataset, which consists of article passages and corresponding human-written summaries. The summaries were annotated for coherence using crowdsourcing. This allows the researchers to train and evaluate models on their ability to produce coherent extractive summaries.
They then experimented with different LLM-based approaches to improve coherence in extractive summarization:
-
Fine-tuning large language models like BERT, RoBERTa, and GPT-2 on the LAMSUM dataset to directly optimize for coherence.
-
Using LLMs to rerank candidate extractive summaries based on coherence scores.
-
Incorporating coherence scoring as an additional objective when training extractive summarization models.
The results show that the LLM-based approaches can indeed enhance the coherence of extractive summaries compared to previous methods. The authors provide detailed analysis and ablation studies to understand the key factors driving these improvements.
Critical Analysis
The paper makes a valuable contribution by introducing the LAMSUM dataset and demonstrating effective ways to leverage LLMs to improve coherence in extractive summarization. However, the authors acknowledge some limitations:
-
The LAMSUM dataset is relatively small compared to other summarization benchmarks, so the models may not generalize as well to larger-scale real-world applications.
-
The coherence annotations in LAMSUM are subjective and may not fully capture all aspects of summary quality.
-
The proposed methods still have room for improvement, as even the best-performing models do not achieve human-level coherence scores on the dataset.
It would also be interesting to see how these coherence-enhanced extractive summaries compare to abstractive summarization approaches in terms of both coherence and overall quality. Further research could explore using the LAMSUM dataset for training more advanced summarization models or combining extractive and abstractive techniques.
Conclusion
This paper presents an important step towards improving the coherence of extractive summarization using large language models. The new LAMSUM dataset and LLM-based methods offer a promising direction for developing more natural and useful text summarization systems. While there are still some limitations to address, this work demonstrates the value of focusing on summary coherence and provides a strong foundation for future research in this area.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Towards Enhancing Coherence in Extractive Summarization: Dataset and Experiments with LLMs
Mihir Parmar, Hanieh Deilamsalehy, Franck Dernoncourt, Seunghyun Yoon, Ryan A. Rossi, Trung Bui
Extractive summarization plays a pivotal role in natural language processing due to its wide-range applications in summarizing diverse content efficiently, while also being faithful to the original content. Despite significant advancement achieved in extractive summarization by Large Language Models (LLMs), these summaries frequently exhibit incoherence. An important aspect of the coherent summary is its readability for intended users. Although there have been many datasets and benchmarks proposed for creating coherent extractive summaries, none of them currently incorporate user intent to improve coherence in extractive summarization. Motivated by this, we propose a systematically created human-annotated dataset consisting of coherent summaries for five publicly available datasets and natural language user feedback, offering valuable insights into how to improve coherence in extractive summaries. We utilize this dataset for aligning LLMs through supervised fine-tuning with natural language human feedback to enhance the coherence of their generated summaries. Preliminary experiments with Falcon-40B and Llama-2-13B show significant performance improvements (~10% Rouge-L) in terms of producing coherent summaries. We further utilize human feedback to benchmark results over instruction-tuned models such as FLAN-T5 which resulted in several interesting findings. Data and source code are available at https://github.com/Mihir3009/Extract-AI.
Read more7/9/2024
0
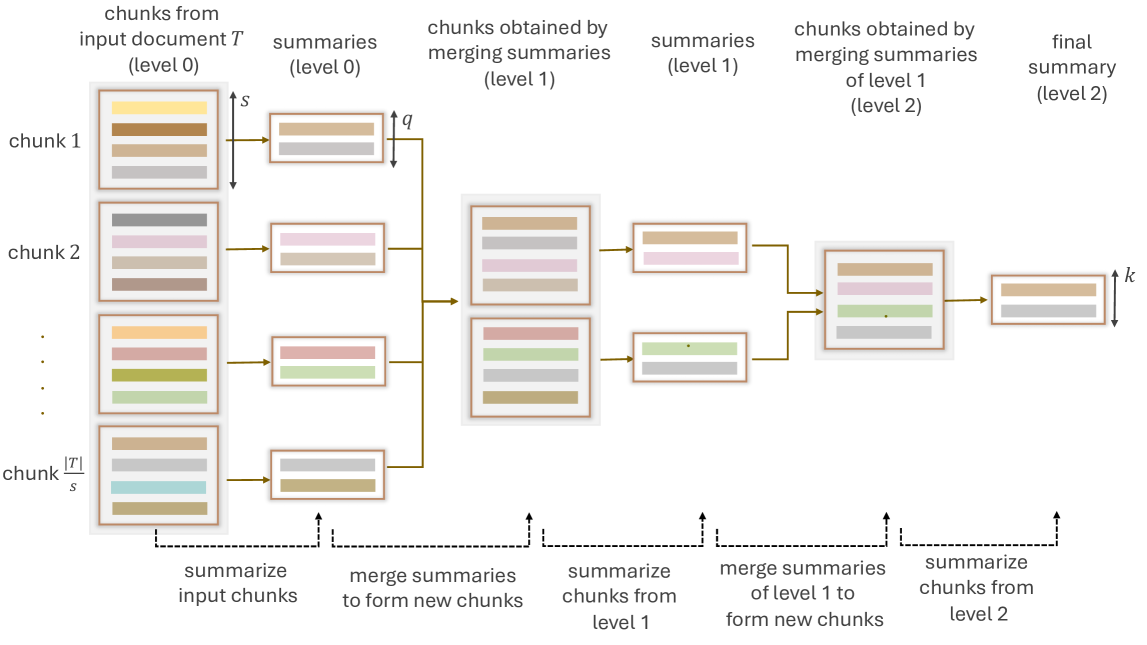
LaMSUM: A Novel Framework for Extractive Summarization of User Generated Content using LLMs
Garima Chhikara, Anurag Sharma, V. Gurucharan, Kripabandhu Ghosh, Abhijnan Chakraborty
Large Language Models (LLMs) have demonstrated impressive performance across a wide range of NLP tasks, including summarization. LLMs inherently produce abstractive summaries by paraphrasing the original text, while the generation of extractive summaries - selecting specific subsets from the original text - remains largely unexplored. LLMs have a limited context window size, restricting the amount of data that can be processed at once. We tackle this challenge by introducing LaMSUM, a novel multi-level framework designed to generate extractive summaries from large collections of user-generated text using LLMs. LaMSUM integrates summarization with different voting methods to achieve robust summaries. Extensive evaluation using four popular LLMs (Llama 3, Mixtral, Gemini, GPT-4o) demonstrates that LaMSUM outperforms state-of-the-art extractive summarization methods. Overall, this work represents one of the first attempts to achieve extractive summarization by leveraging the power of LLMs, and is likely to spark further interest within the research community.
Read more8/26/2024

0
MixSumm: Topic-based Data Augmentation using LLMs for Low-resource Extractive Text Summarization
Gaurav Sahu, Issam H. Laradji
Low-resource extractive text summarization is a vital but heavily underexplored area of research. Prior literature either focuses on abstractive text summarization or prompts a large language model (LLM) like GPT-3 directly to generate summaries. In this work, we propose MixSumm for low-resource extractive text summarization. Specifically, MixSumm prompts an open-source LLM, LLaMA-3-70b, to generate documents that mix information from multiple topics as opposed to generating documents without mixup, and then trains a summarization model on the generated dataset. We use ROUGE scores and L-Eval, a reference-free LLaMA-3-based evaluation method to measure the quality of generated summaries. We conduct extensive experiments on a challenging text summarization benchmark comprising the TweetSumm, WikiHow, and ArXiv/PubMed datasets and show that our LLM-based data augmentation framework outperforms recent prompt-based approaches for low-resource extractive summarization. Additionally, our results also demonstrate effective knowledge distillation from LLaMA-3-70b to a small BERT-based extractive summarizer.
Read more7/11/2024
💬
0
On Learning to Summarize with Large Language Models as References
Yixin Liu, Kejian Shi, Katherine S He, Longtian Ye, Alexander R. Fabbri, Pengfei Liu, Dragomir Radev, Arman Cohan
Recent studies have found that summaries generated by large language models (LLMs) are favored by human annotators over the original reference summaries in commonly used summarization datasets. Therefore, we study an LLM-as-reference learning setting for smaller text summarization models to investigate whether their performance can be substantially improved. To this end, we use LLMs as both oracle summary generators for standard supervised fine-tuning and oracle summary evaluators for efficient contrastive learning that leverages the LLMs' supervision signals. We conduct comprehensive experiments with source news articles and find that (1) summarization models trained under the LLM-as-reference setting achieve significant performance improvement in both LLM and human evaluations; (2) contrastive learning outperforms standard supervised fine-tuning under both low and high resource settings. Our experimental results also enable a meta-analysis of LLMs' summary evaluation capacities under a challenging setting, showing that LLMs are not well-aligned with human evaluators. Particularly, our expert human evaluation reveals remaining nuanced performance gaps between LLMs and our fine-tuned models, which LLMs fail to capture. Thus, we call for further studies into both the potential and challenges of using LLMs in summarization model development.
Read more7/19/2024