Towards Open-World Grasping with Large Vision-Language Models
2406.18722
0
0

Abstract
The ability to grasp objects in-the-wild from open-ended language instructions constitutes a fundamental challenge in robotics. An open-world grasping system should be able to combine high-level contextual with low-level physical-geometric reasoning in order to be applicable in arbitrary scenarios. Recent works exploit the web-scale knowledge inherent in large language models (LLMs) to plan and reason in robotic context, but rely on external vision and action models to ground such knowledge into the environment and parameterize actuation. This setup suffers from two major bottlenecks: a) the LLM's reasoning capacity is constrained by the quality of visual grounding, and b) LLMs do not contain low-level spatial understanding of the world, which is essential for grasping in contact-rich scenarios. In this work we demonstrate that modern vision-language models (VLMs) are capable of tackling such limitations, as they are implicitly grounded and can jointly reason about semantics and geometry. We propose OWG, an open-world grasping pipeline that combines VLMs with segmentation and grasp synthesis models to unlock grounded world understanding in three stages: open-ended referring segmentation, grounded grasp planning and grasp ranking via contact reasoning, all of which can be applied zero-shot via suitable visual prompting mechanisms. We conduct extensive evaluation in cluttered indoor scene datasets to showcase OWG's robustness in grounding from open-ended language, as well as open-world robotic grasping experiments in both simulation and hardware that demonstrate superior performance compared to previous supervised and zero-shot LLM-based methods.
Create account to get full access
Overview
- This paper explores the potential of using large vision-language models (LVLMs) for open-world grasping, which involves picking up objects in complex, real-world environments without prior knowledge of the objects.
- The authors propose a framework that leverages the capabilities of LVLMs to enable robots to reason about and interact with objects in an open-world setting.
- The research builds on previous work on reasoning-grasping via multimodal large language model, vision-language model-based physical reasoning for robots, and leveraging large-scale vision models.
Plain English Explanation
The paper explores ways to use powerful language and vision models to enable robots to pick up and manipulate objects in the real world, even if they've never seen those specific objects before. The key idea is to leverage the broad knowledge and reasoning capabilities of these large models to help robots understand the physical properties and affordances of objects, and then use that understanding to figure out how to grasp and manipulate them.
This builds on previous research that has shown the potential of using language models for reasoning about physical interactions and vision-language models for physical reasoning in robotics. The authors want to take this a step further and see if these models can enable robots to handle "open-world" scenarios, where they encounter novel objects and have to figure out how to interact with them on the fly.
Technical Explanation
The paper proposes a framework that combines a large vision-language model (LVLM) with a robotic grasping system. The LVLM is trained on a vast amount of image and text data, giving it a broad understanding of the visual world and how language is used to describe it.
When the robot encounters an object, it uses the LVLM to analyze the visual input and reason about the object's physical properties and potential grasping affordances. This allows the robot to plan an appropriate grasping strategy, even for unfamiliar objects, by leveraging the model's general knowledge about object properties and interactions.
The authors evaluate their approach on a range of real-world objects, including novel objects that the model has never seen before. The results show that the LVLM-based framework can enable effective grasping in open-world settings, outperforming traditional grasping methods that rely on pre-defined object models or features.
Critical Analysis
The paper presents a promising approach for enabling robots to handle open-world grasping tasks using large vision-language models. However, the authors acknowledge several limitations and areas for future research:
- The current framework is limited to single-object grasping scenarios, and would need to be extended to handle more complex, cluttered environments with multiple objects. Further research on language-grounded dynamic scene graphs for interactive object manipulation could help address this.
- The performance of the system is still dependent on the quality and coverage of the training data for the LVLM. Improving the model's ability to reason about unseen objects and situations remains an active area of research.
- Integrating the LVLM-based grasping system with other robotic skills, such as navigation and manipulation, would be an important next step towards natural language-driven assembly.
Overall, the research represents an important step towards more flexible and capable robotic systems that can operate effectively in open-world environments by leveraging the powerful reasoning abilities of large-scale vision-language models.
Conclusion
This paper explores a novel approach to open-world grasping, where robots can pick up and manipulate unfamiliar objects by leveraging the broad knowledge and reasoning capabilities of large vision-language models. The proposed framework shows promising results, and the authors outline several directions for future research to further improve the system's performance and generalization abilities.
The work builds on and advances previous research on using language models for physical reasoning, vision-language models for robotics, and leveraging large-scale vision models. If successful, this line of research could lead to more versatile and capable robotic systems that can navigate and interact with the real world in a more natural, human-like way, with potential applications in areas like natural language-driven assembly.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
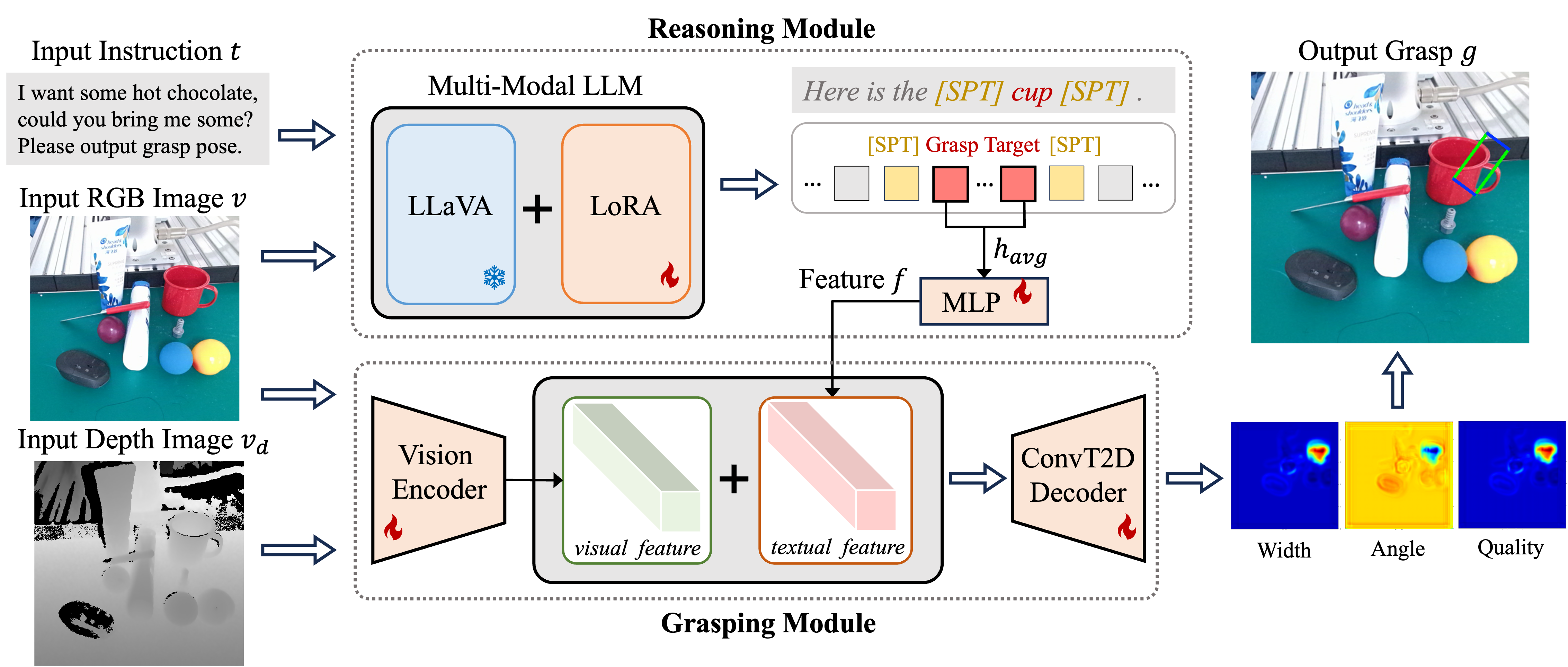
Reasoning Grasping via Multimodal Large Language Model
Shiyu Jin, Jinxuan Xu, Yutian Lei, Liangjun Zhang
0
0
Despite significant progress in robotic systems for operation within human-centric environments, existing models still heavily rely on explicit human commands to identify and manipulate specific objects. This limits their effectiveness in environments where understanding and acting on implicit human intentions are crucial. In this study, we introduce a novel task: reasoning grasping, where robots need to generate grasp poses based on indirect verbal instructions or intentions. To accomplish this, we propose an end-to-end reasoning grasping model that integrates a multi-modal Large Language Model (LLM) with a vision-based robotic grasping framework. In addition, we present the first reasoning grasping benchmark dataset generated from the GraspNet-1 billion, incorporating implicit instructions for object-level and part-level grasping, and this dataset will soon be available for public access. Our results show that directly integrating CLIP or LLaVA with the grasp detection model performs poorly on the challenging reasoning grasping tasks, while our proposed model demonstrates significantly enhanced performance both in the reasoning grasping benchmark and real-world experiments.
4/29/2024
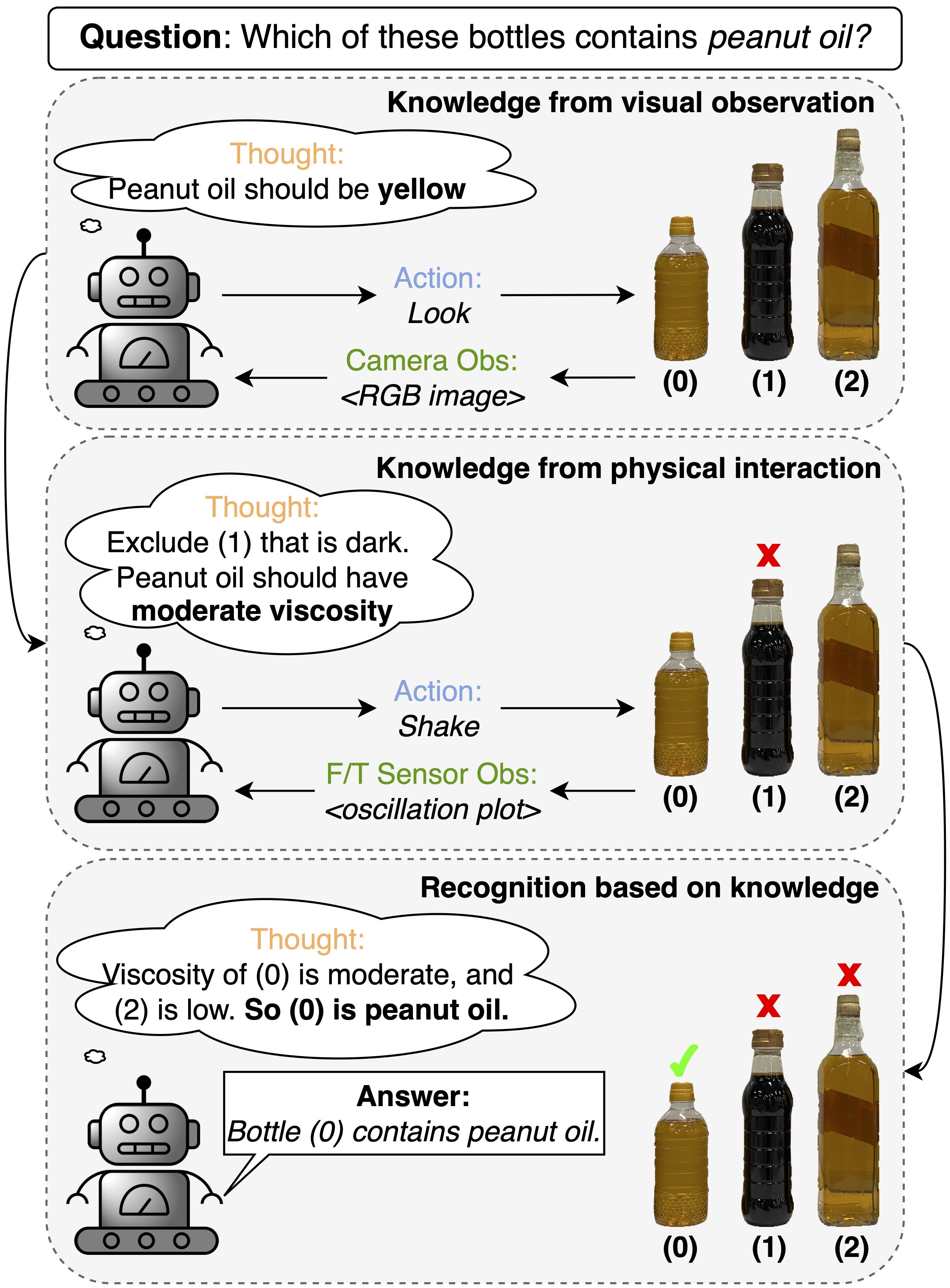
Vision-Language Model-based Physical Reasoning for Robot Liquid Perception
Wenqiang Lai, Yuan Gao, Tin Lun Lam
0
0
There is a growing interest in applying large language models (LLMs) in robotic tasks, due to their remarkable reasoning ability and extensive knowledge learned from vast training corpora. Grounding LLMs in the physical world remains an open challenge as they can only process textual input. Recent advancements in large vision-language models (LVLMs) have enabled a more comprehensive understanding of the physical world by incorporating visual input, which provides richer contextual information than language alone. In this work, we proposed a novel paradigm that leveraged GPT-4V(ision), the state-of-the-art LVLM by OpenAI, to enable embodied agents to perceive liquid objects via image-based environmental feedback. Specifically, we exploited the physical understanding of GPT-4V to interpret the visual representation (e.g., time-series plot) of non-visual feedback (e.g., F/T sensor data), indirectly enabling multimodal perception beyond vision and language using images as proxies. We evaluated our method using 10 common household liquids with containers of various geometry and material. Without any training or fine-tuning, we demonstrated that our method can enable the robot to indirectly perceive the physical response of liquids and estimate their viscosity. We also showed that by jointly reasoning over the visual and physical attributes learned through interactions, our method could recognize liquid objects in the absence of strong visual cues (e.g., container labels with legible text or symbols), increasing the accuracy from 69.0% -- achieved by the best-performing vision-only variant -- to 86.0%.
4/11/2024

A Brief Survey on Leveraging Large Scale Vision Models for Enhanced Robot Grasping
Abhi Kamboj, Katherine Driggs-Campbell
0
0
Robotic grasping presents a difficult motor task in real-world scenarios, constituting a major hurdle to the deployment of capable robots across various industries. Notably, the scarcity of data makes grasping particularly challenging for learned models. Recent advancements in computer vision have witnessed a growth of successful unsupervised training mechanisms predicated on massive amounts of data sourced from the Internet, and now nearly all prominent models leverage pretrained backbone networks. Against this backdrop, we begin to investigate the potential benefits of large-scale visual pretraining in enhancing robot grasping performance. This preliminary literature review sheds light on critical challenges and delineates prospective directions for future research in visual pretraining for robotic manipulation.
6/18/2024
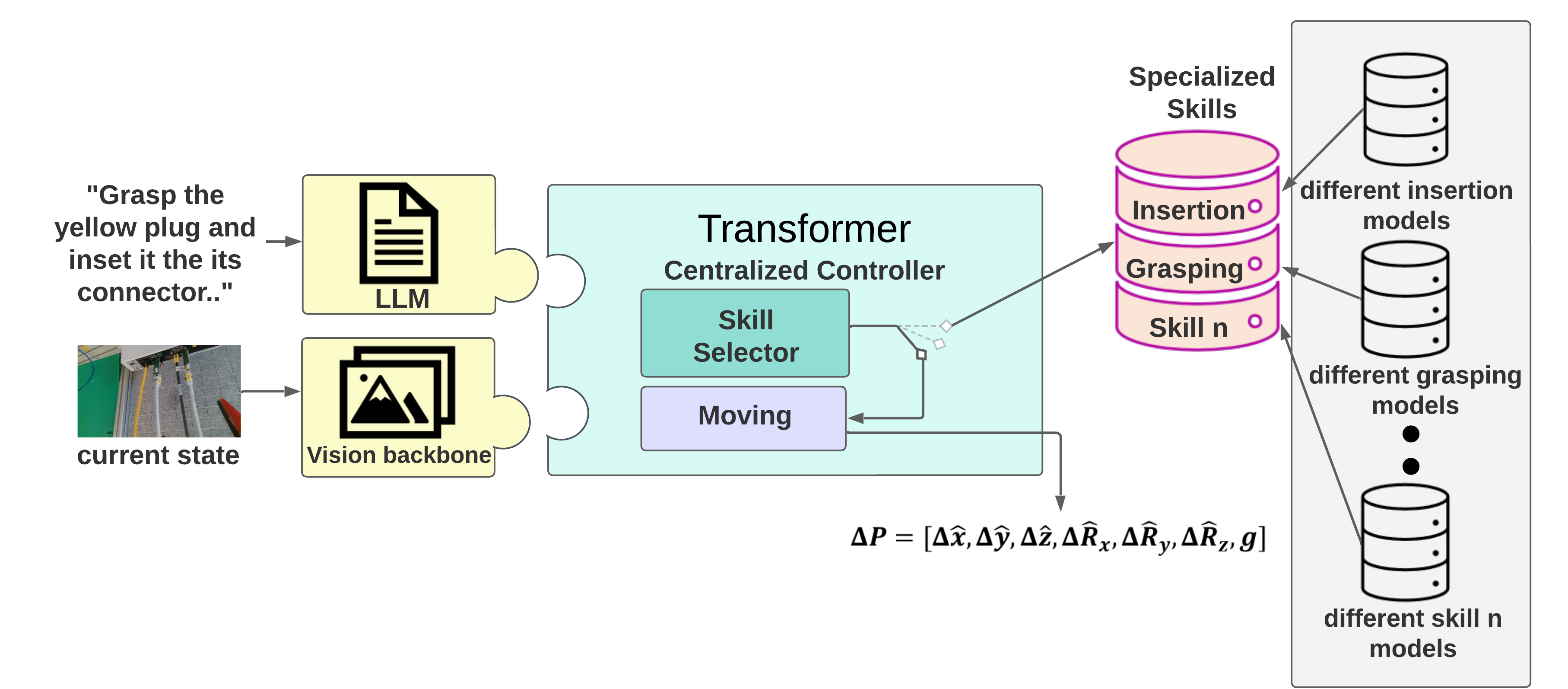
Towards Natural Language-Driven Assembly Using Foundation Models
Omkar Joglekar, Tal Lancewicki, Shir Kozlovsky, Vladimir Tchuiev, Zohar Feldman, Dotan Di Castro
0
0
Large Language Models (LLMs) and strong vision models have enabled rapid research and development in the field of Vision-Language-Action models that enable robotic control. The main objective of these methods is to develop a generalist policy that can control robots with various embodiments. However, in industrial robotic applications such as automated assembly and disassembly, some tasks, such as insertion, demand greater accuracy and involve intricate factors like contact engagement, friction handling, and refined motor skills. Implementing these skills using a generalist policy is challenging because these policies might integrate further sensory data, including force or torque measurements, for enhanced precision. In our method, we present a global control policy based on LLMs that can transfer the control policy to a finite set of skills that are specifically trained to perform high-precision tasks through dynamic context switching. The integration of LLMs into this framework underscores their significance in not only interpreting and processing language inputs but also in enriching the control mechanisms for diverse and intricate robotic operations.
6/26/2024