Towards Pareto Optimal Throughput in Small Language Model Serving
2404.03353
0
0
Abstract
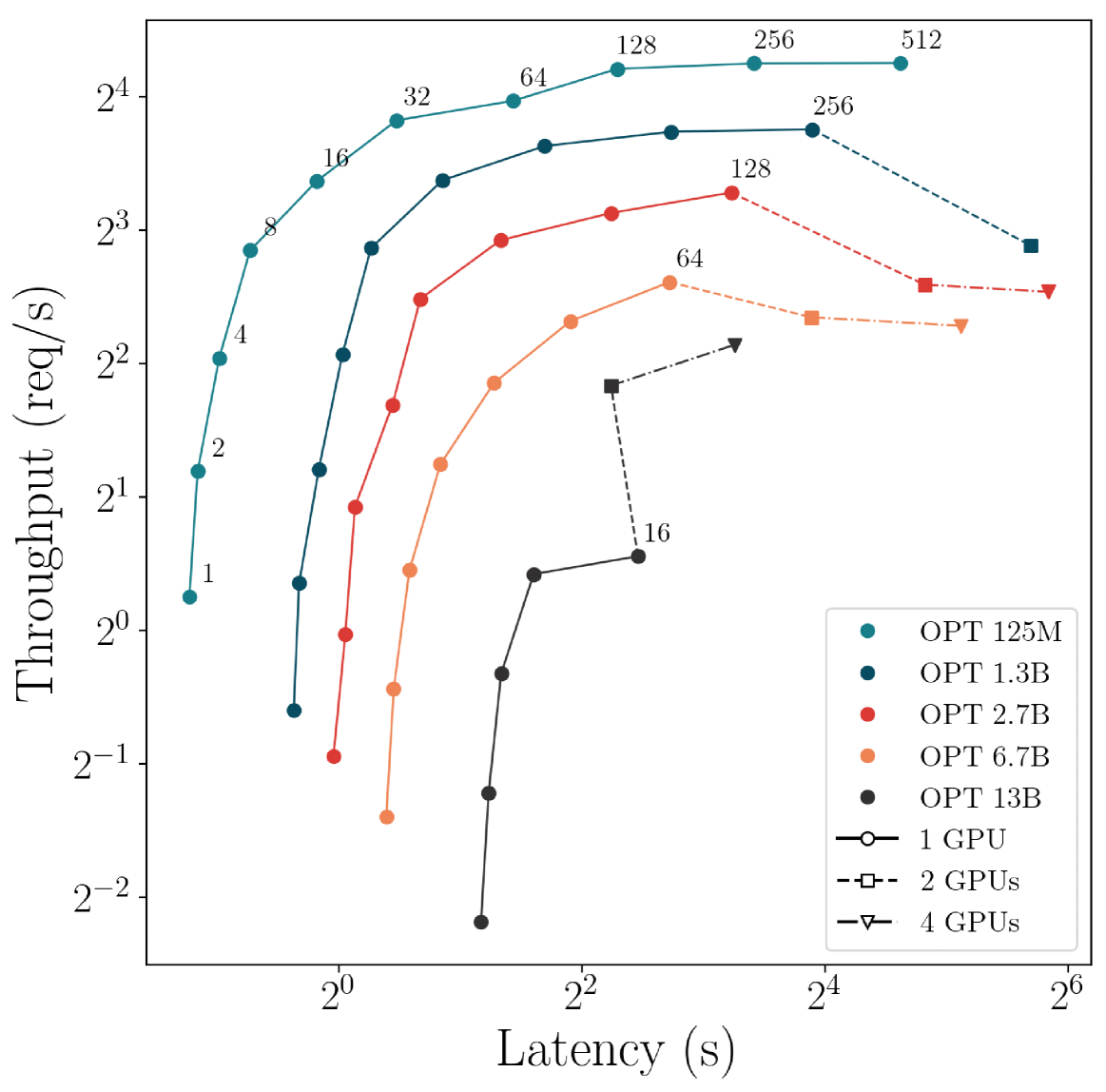
Large language models (LLMs) have revolutionized the state-of-the-art of many different natural language processing tasks. Although serving LLMs is computationally and memory demanding, the rise of Small Language Models (SLMs) offers new opportunities for resource-constrained users, who now are able to serve small models with cutting-edge performance. In this paper, we present a set of experiments designed to benchmark SLM inference at performance and energy levels. Our analysis provides a new perspective in serving, highlighting that the small memory footprint of SLMs allows for reaching the Pareto-optimal throughput within the resource capacity of a single accelerator. In this regard, we present an initial set of findings demonstrating how model replication can effectively improve resource utilization for serving SLMs.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- This paper presents a novel approach to improving the throughput of small language models in serving scenarios, which is critical for real-time applications.
- The key ideas involve using a key-value (KV) cache to store and quickly retrieve commonly used model outputs, and optimizing the cache management to achieve Pareto-optimal throughput.
- The paper includes detailed experiments and technical explanations of the proposed architecture and algorithms, along with a critical analysis of the approach and potential areas for future research.
Plain English Explanation
Imagine you have a small language model, like a virtual assistant, that needs to respond quickly to user queries. The challenge is that running the model for each query can be slow and resource-intensive. The researchers in this paper found a clever way to address this problem.
The core idea is to use a special type of memory called a "key-value cache" to store common responses the model generates. When a new query comes in, the system first checks the cache to see if it has the answer ready to go, instead of having to run the full model. This can dramatically improve the speed and efficiency of the system.
The researchers also developed advanced algorithms to manage this cache in an optimal way, ensuring that the most important and useful information is always available. This allows the system to provide high-throughput responses while still maintaining the quality and accuracy of the language model.
By combining the power of the language model with the speed of the cache, the researchers were able to create a system that is "Pareto optimal" - meaning it achieves the best possible balance between throughput (speed) and other important factors like latency and resource usage.
This work has important implications for real-world applications of language models, such as chatbots, virtual assistants, and other interactive AI systems that need to respond quickly and efficiently. The techniques developed in this paper could help make these systems more practical and usable in a wide range of settings.
Technical Explanation
The key technical contributions of this paper are:
-
KV Cache in Autoregressive Models: The authors propose using a key-value (KV) cache to store and quickly retrieve commonly used outputs from the language model. This allows the system to avoid expensive model inference for these queries, dramatically improving throughput.
-
Optimal Cache Management: The researchers develop advanced cache management algorithms to ensure the cache contains the most valuable information. This involves techniques like prioritizing high-frequency outputs, and dynamically adjusting the cache size based on workload.
-
Pareto Optimal Throughput: By carefully optimizing the cache management, the authors are able to achieve Pareto optimal throughput - meaning they maximize throughput while maintaining other important metrics like latency and resource usage within acceptable bounds.
-
Extensive Experimentation: The paper includes a thorough experimental evaluation, testing the proposed techniques on a range of language model sizes and workloads. The results demonstrate significant throughput improvements over baseline approaches.
Critical Analysis
The paper presents a well-designed and comprehensive solution to the challenge of efficiently serving small language models. However, there are a few potential areas for further consideration:
-
Generalization to Larger Models: While the techniques are shown to be effective for small models, it's unclear how well they would scale to larger, more complex language models. The cache management algorithms may need to be adapted to handle the increased diversity and scale of outputs.
-
Impact of Model Fine-tuning: The paper assumes a fixed pre-trained language model, but in practice, these models are often fine-tuned on specific domains or tasks. This could impact the distribution of cached outputs and require further optimization of the cache management.
-
Robustness to Workload Shifts: The proposed algorithms dynamically adjust the cache size, but they may need to be extended to handle more dramatic shifts in the input workload, such as sudden spikes in traffic or changes in the types of queries.
-
Potential Application to Other AI Tasks: While the paper focuses on language model serving, the core ideas around caching and Pareto-optimal throughput optimization could potentially be applied to other AI domains, such as vision or multimodal models, as well as specialized language tasks.
Overall, this paper presents a significant contribution to the challenge of efficiently serving small language models, with a strong technical foundation and valuable insights. The techniques developed could have broad applicability in the field of real-time AI systems.
Conclusion
This paper introduces a novel approach to improving the throughput of small language models in serving scenarios, a critical challenge for real-time AI applications. By leveraging a key-value cache and optimizing the cache management, the researchers were able to achieve Pareto-optimal throughput, balancing speed, latency, and resource usage.
The technical details and extensive experimentation demonstrate the effectiveness of the proposed techniques, which could have wide-ranging implications for the deployment of language models in practical settings, such as virtual assistants, chatbots, and other interactive AI systems. While there are some potential areas for further exploration, this work represents a significant advancement in the efficient serving of small-scale language models.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🤯
Efficient LLM Inference with Kcache
Qiaozhi He, Zhihua Wu
0
0
Large Language Models(LLMs) have had a profound impact on AI applications, particularly in the domains of long-text comprehension and generation. KV Cache technology is one of the most widely used techniques in the industry. It ensures efficient sequence generation by caching previously computed KV states. However, it also introduces significant memory overhead. We discovered that KV Cache is not necessary and proposed a novel KCache technique to alleviate the memory bottleneck issue during the LLMs inference process. KCache can be used directly for inference without any training process, Our evaluations show that KCache improves the throughput of popular LLMs by 40% with the baseline, while keeping accuracy.
4/30/2024
New!Layer-Condensed KV Cache for Efficient Inference of Large Language Models
Haoyi Wu, Kewei Tu
0
0
Huge memory consumption has been a major bottleneck for deploying high-throughput large language models in real-world applications. In addition to the large number of parameters, the key-value (KV) cache for the attention mechanism in the transformer architecture consumes a significant amount of memory, especially when the number of layers is large for deep language models. In this paper, we propose a novel method that only computes and caches the KVs of a small number of layers, thus significantly saving memory consumption and improving inference throughput. Our experiments on large language models show that our method achieves up to 26$times$ higher throughput than standard transformers and competitive performance in language modeling and downstream tasks. In addition, our method is orthogonal to existing transformer memory-saving techniques, so it is straightforward to integrate them with our model, achieving further improvement in inference efficiency. Our code is available at https://github.com/whyNLP/LCKV.
5/20/2024
🤯
KVQuant: Towards 10 Million Context Length LLM Inference with KV Cache Quantization
Coleman Hooper, Sehoon Kim, Hiva Mohammadzadeh, Michael W. Mahoney, Yakun Sophia Shao, Kurt Keutzer, Amir Gholami
0
0
LLMs are seeing growing use for applications such as document analysis and summarization which require large context windows, and with these large context windows KV cache activations surface as the dominant contributor to memory consumption during inference. Quantization is a promising approach for compressing KV cache activations; however, existing solutions fail to represent activations accurately in ultra-low precisions, such as sub-4-bit. In this work, we present KVQuant, which addresses this problem by incorporating novel methods for quantizing cached KV activations, including: (i) Per-Channel Key Quantization, where we adjust the dimension along which we quantize the Key activations to better match the distribution; (ii) Pre-RoPE Key Quantization, where we quantize Key activations before the rotary positional embedding to mitigate its impact on quantization; (iii) Non-Uniform KV Cache Quantization, where we derive per-layer sensitivity-weighted non-uniform datatypes that better represent the distributions; (iv) Per-Vector Dense-and-Sparse Quantization, where we isolate outliers separately for each vector to minimize skews in quantization ranges; and (v) Q-Norm, where we normalize quantization centroids in order to mitigate distribution shift, providing additional benefits for 2-bit quantization. By applying our method to the LLaMA, LLaMA-2, and Mistral models, we achieve $<0.1$ perplexity degradation with 3-bit quantization on both Wikitext-2 and C4, outperforming existing approaches. Our method enables serving the LLaMA-7B model with a context length of up to 1 million on a single A100-80GB GPU and up to 10 million on an 8-GPU system.
4/5/2024
💬
Efficient Streaming Language Models with Attention Sinks
Guangxuan Xiao, Yuandong Tian, Beidi Chen, Song Han, Mike Lewis
0
0
Deploying Large Language Models (LLMs) in streaming applications such as multi-round dialogue, where long interactions are expected, is urgently needed but poses two major challenges. Firstly, during the decoding stage, caching previous tokens' Key and Value states (KV) consumes extensive memory. Secondly, popular LLMs cannot generalize to longer texts than the training sequence length. Window attention, where only the most recent KVs are cached, is a natural approach -- but we show that it fails when the text length surpasses the cache size. We observe an interesting phenomenon, namely attention sink, that keeping the KV of initial tokens will largely recover the performance of window attention. In this paper, we first demonstrate that the emergence of attention sink is due to the strong attention scores towards initial tokens as a sink even if they are not semantically important. Based on the above analysis, we introduce StreamingLLM, an efficient framework that enables LLMs trained with a finite length attention window to generalize to infinite sequence lengths without any fine-tuning. We show that StreamingLLM can enable Llama-2, MPT, Falcon, and Pythia to perform stable and efficient language modeling with up to 4 million tokens and more. In addition, we discover that adding a placeholder token as a dedicated attention sink during pre-training can further improve streaming deployment. In streaming settings, StreamingLLM outperforms the sliding window recomputation baseline by up to 22.2x speedup. Code and datasets are provided at https://github.com/mit-han-lab/streaming-llm.
4/9/2024