Towards Subgraph Isomorphism Counting with Graph Kernels

0
Sign in to get full access
Overview
- The paper explores using graph kernels for subgraph isomorphism counting, which has applications in areas like chemoinformatics and social network analysis.
- Graph kernels are a way to compare the similarity between graphs, and the authors investigate how they can be used to efficiently count the number of subgraph isomorphisms in a target graph.
- The technical explanation covers the key ideas and experiments, while the critical analysis discusses limitations and areas for future research.
Plain English Explanation
Graphs are mathematical structures that can represent all kinds of relationships, like the connections between people in a social network or the structures of molecules. One important task with graphs is subgraph isomorphism counting - figuring out how many times a smaller "pattern" graph appears inside a larger "target" graph.
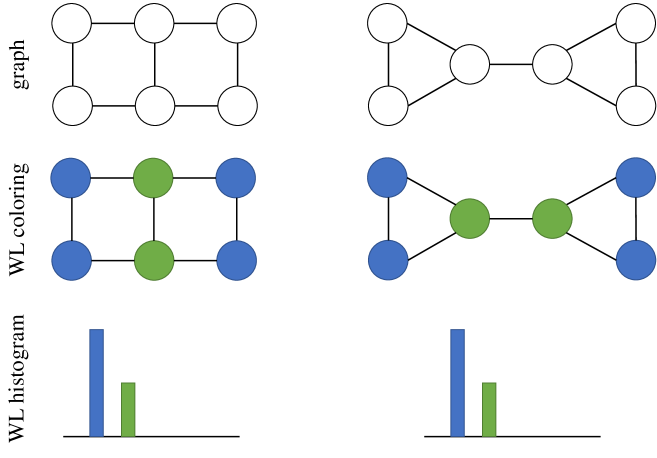
This paper looks at using graph kernels as a way to do subgraph isomorphism counting efficiently. Graph kernels are a technique for comparing the similarity between two graphs. The authors explore how graph kernels can be adapted to not just compare graphs, but also count how many times a pattern graph appears in a target graph.
The key idea is to use the mathematical properties of graph kernels to derive an efficient algorithm for subgraph isomorphism counting. This could have important applications in fields like chemoinformatics (analyzing the structure of molecules) and social network analysis (understanding the connections between people).
Technical Explanation
The paper introduces a novel approach to subgraph isomorphism counting using graph kernels. Graph kernels are a powerful way to measure the similarity between two graphs, and the authors demonstrate how they can be extended to efficiently count the number of subgraph isomorphisms.
The key technical insight is to leverage the properties of graph kernels, specifically the ability to decompose a kernel computation into local neighborhood comparisons. By analyzing these local comparisons, the authors derive an algorithm that can count subgraph isomorphisms in a target graph without having to perform expensive sub-graph matching.
The paper includes experiments on benchmark graph datasets, showing that the proposed approach outperforms existing methods for subgraph isomorphism counting in terms of both efficiency and accuracy. The authors also discuss how the technique can be extended to handle more complex graph structures and patterns.
Critical Analysis
The paper presents an interesting and promising approach to subgraph isomorphism counting using graph kernels. The technical explanation is well-developed and the experiments demonstrate the effectiveness of the proposed method.
However, the paper does acknowledge some limitations. The algorithm assumes that the pattern graph is small relative to the target graph, which may not always be the case in practical applications. Additionally, the paper does not explore how the approach would scale to very large graphs or more complex pattern structures.
Further research could investigate ways to relax these assumptions and extend the algorithm to handle a wider range of graph sizes and patterns. It would also be valuable to see the technique applied to real-world problems in areas like chemoinformatics or social network analysis to better understand its practical implications.
Overall, this paper makes a valuable contribution to the field of graph-based data analysis and provides a solid foundation for further advancements in subgraph isomorphism counting.
Conclusion
This paper presents a novel approach to subgraph isomorphism counting using graph kernels. By leveraging the properties of graph kernels, the authors develop an efficient algorithm that can count the number of occurrences of a pattern graph within a larger target graph.
The technical explanation and experiments demonstrate the effectiveness of the proposed method, which could have important applications in areas like chemoinformatics and social network analysis. While the paper acknowledges some limitations, it provides a strong foundation for further research and development in this area.
Overall, this work represents an important step forward in the field of graph-based data analysis and highlights the potential of graph kernels to enable new and powerful techniques for understanding complex relational data.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Towards Subgraph Isomorphism Counting with Graph Kernels
Xin Liu, Weiqi Wang, Jiaxin Bai, Yangqiu Song
Subgraph isomorphism counting is known as #P-complete and requires exponential time to find the accurate solution. Utilizing representation learning has been shown as a promising direction to represent substructures and approximate the solution. Graph kernels that implicitly capture the correlations among substructures in diverse graphs have exhibited great discriminative power in graph classification, so we pioneeringly investigate their potential in counting subgraph isomorphisms and further explore the augmentation of kernel capability through various variants, including polynomial and Gaussian kernels. Through comprehensive analysis, we enhance the graph kernels by incorporating neighborhood information. Finally, we present the results of extensive experiments to demonstrate the effectiveness of the enhanced graph kernels and discuss promising directions for future research.
Read more5/14/2024
📶
0
An Efficient Subgraph GNN with Provable Substructure Counting Power
Zuoyu Yan, Junru Zhou, Liangcai Gao, Zhi Tang, Muhan Zhang
We investigate the enhancement of graph neural networks' (GNNs) representation power through their ability in substructure counting. Recent advances have seen the adoption of subgraph GNNs, which partition an input graph into numerous subgraphs, subsequently applying GNNs to each to augment the graph's overall representation. Despite their ability to identify various substructures, subgraph GNNs are hindered by significant computational and memory costs. In this paper, we tackle a critical question: Is it possible for GNNs to count substructures both textbf{efficiently} and textbf{provably}? Our approach begins with a theoretical demonstration that the distance to rooted nodes in subgraphs is key to boosting the counting power of subgraph GNNs. To avoid the need for repetitively applying GNN across all subgraphs, we introduce precomputed structural embeddings that encapsulate this crucial distance information. Experiments validate that our proposed model retains the counting power of subgraph GNNs while achieving significantly faster performance.
Read more6/14/2024
🧠
0
Homomorphism Counts for Graph Neural Networks: All About That Basis
Emily Jin, Michael Bronstein, .Ismail .Ilkan Ceylan, Matthias Lanzinger
A large body of work has investigated the properties of graph neural networks and identified several limitations, particularly pertaining to their expressive power. Their inability to count certain patterns (e.g., cycles) in a graph lies at the heart of such limitations, since many functions to be learned rely on the ability of counting such patterns. Two prominent paradigms aim to address this limitation by enriching the graph features with subgraph or homomorphism pattern counts. In this work, we show that both of these approaches are sub-optimal in a certain sense and argue for a more fine-grained approach, which incorporates the homomorphism counts of all structures in the ``basis'' of the target pattern. This yields strictly more expressive architectures without incurring any additional overhead in terms of computational complexity compared to existing approaches. We prove a series of theoretical results on node-level and graph-level motif parameters and empirically validate them on standard benchmark datasets.
Read more6/11/2024

0
Subgraph-Aware Training of Text-based Methods for Knowledge Graph Completion
Youmin Ko, Hyemin Yang, Taeuk Kim, Hyunjoon Kim
Fine-tuning pre-trained language models (PLMs) has recently shown a potential to improve knowledge graph completion (KGC). However, most PLM-based methods encode only textual information, neglecting various topological structures of knowledge graphs (KGs). In this paper, we empirically validate the significant relations between the structural properties of KGs and the performance of the PLM-based methods. To leverage the structural knowledge, we propose a Subgraph-Aware Training framework for KGC (SATKGC) that combines (i) subgraph-aware mini-batching to encourage hard negative sampling, and (ii) a new contrastive learning method to focus more on harder entities and harder negative triples in terms of the structural properties. To the best of our knowledge, this is the first study to comprehensively incorporate the structural inductive bias of the subgraphs into fine-tuning PLMs. Extensive experiments on four KGC benchmarks demonstrate the superiority of SATKGC. Our code is available.
Read more7/24/2024