Towards a Theoretical Understanding of the 'Reversal Curse' via Training Dynamics
2405.04669
0
0
Abstract
Auto-regressive large language models (LLMs) show impressive capacities to solve many complex reasoning tasks while struggling with some simple logical reasoning tasks such as inverse search: when trained on ''A is B'', LLM fails to directly conclude ''B is A'' during inference, which is known as the ''reversal curse'' (Berglund et al., 2023). In this paper, we theoretically analyze the reversal curse via the training dynamics of (stochastic) gradient descent for two auto-regressive models: (1) a bilinear model that can be viewed as a simplification of a one-layer transformer; (2) one-layer transformers using the framework of Tian et al. (2023a). Our analysis reveals a core reason why the reversal curse happens: the (effective) weights of both auto-regressive models show asymmetry, i.e., the increase of weights from a token $A$ to token $B$ during training does not necessarily cause the increase of the weights from $B$ to $A$. Moreover, our analysis can be naturally applied to other logical reasoning tasks such as chain-of-thought (COT) (Wei et al., 2022b). We show the necessity of COT, i.e., a model trained on ''$A to B$'' and ''$B to C$'' fails to directly conclude ''$A to C$'' without COT (also empirically observed by Allen-Zhu and Li (2023)), for one-layer transformers via training dynamics, which provides a new perspective different from previous work (Feng et al., 2024) that focuses on expressivity. Finally, we also conduct experiments to validate our theory on multi-layer transformers under different settings.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- This paper investigates the "reversal curse" phenomenon in large language models (LLMs) trained on internet data, where the models can exhibit biases, factual errors, and other undesirable behaviors.
- The researchers aim to develop a theoretical understanding of the reversal curse by analyzing the dynamics of the training process.
- They explore how recursive, iterative training on generated data can lead to the amplification of initial biases and errors, ultimately causing the model to "reverse" and learn the wrong information.
Plain English Explanation
The paper examines a curious problem that can occur when training large language models on huge amounts of online data. These powerful AI systems can sometimes end up learning the wrong information or developing biases, a phenomenon known as the "reversal curse" [internal link: https://aimodels.fyi/papers/arxiv/reversal-curse-llms-trained-is-b-fail].
The researchers wanted to better understand why this happens. They looked at the training process itself, and how the models learn by repeatedly generating and refining their own text. This recursive training, where the models learn from their own output, can cause initial biases or mistakes to get amplified over time [internal link: https://aimodels.fyi/papers/arxiv/curse-recursion-training-generated-data-makes-models].
Imagine a language model that starts off with a small bias, maybe it thinks the word "dog" is more common than it really is. As the model generates more text and learns from its own output, that bias gets reinforced and grows stronger, until the model fully believes "dog" is a very common word, even though that's not actually true [internal link: https://aimodels.fyi/papers/arxiv/reverse-training-to-nurse-reversal-curse]. This is the reversal curse in action - the model ends up learning the wrong information.
The researchers hope that by better understanding this training dynamic, they can find ways to prevent or mitigate the reversal curse, so these powerful AI systems can learn accurate information instead of reinforcing biases and mistakes [internal link: https://aimodels.fyi/papers/arxiv/large-language-models-can-learn-temporal-reasoning].
Technical Explanation
The paper presents a theoretical analysis of the "reversal curse" phenomenon observed in large language models (LLMs) trained on internet data [internal link: https://aimodels.fyi/papers/arxiv/reversal-curse-llms-trained-is-b-fail].
The researchers developed a simplified model of the iterative training process, where the LLM generates text and then learns from its own output. They showed how this recursive training can lead to the amplification of initial biases or errors, causing the model to "reverse" and learn the wrong information over time [internal link: https://aimodels.fyi/papers/arxiv/curse-recursion-training-generated-data-makes-models].
Through mathematical analysis and simulations, the team explored how factors like the initial bias, the strength of the model's learning, and the degree of recursion in the training process can influence the likelihood and severity of the reversal curse. They found that more complex models with stronger learning capabilities are particularly susceptible to this issue [internal link: https://aimodels.fyi/papers/arxiv/regressive-side-effects-training-language-models-to].
The researchers also discussed potential mitigation strategies, such as periodically injecting ground truth data or constraining the model's learning to prevent excessive reinforcement of biases. Their theoretical framework provides a foundation for further investigating and addressing the reversal curse in large language models.
Critical Analysis
The paper provides a compelling theoretical explanation for the reversal curse phenomenon, but it acknowledges several limitations and areas for further research.
For example, the simplified model used in the analysis may not fully capture the complexities of real-world LLM training, which involves much larger datasets, diverse learning objectives, and more sophisticated architectural choices. Empirical validation of the theory's predictions on actual LLM systems would be an important next step [internal link: https://aimodels.fyi/papers/arxiv/reversal-curse-llms-trained-is-b-fail].
Additionally, the paper focuses on the amplification of initial biases, but it does not address the potential introduction of new biases or errors during the iterative training process. The researchers note that understanding the sources and evolution of these biases could lead to more effective mitigation strategies [internal link: https://aimodels.fyi/papers/arxiv/reverse-training-to-nurse-reversal-curse].
Finally, while the proposed mitigation techniques, such as data injections and learning constraints, seem promising, their practical implementation and effectiveness in real-world LLM training would require further investigation [internal link: https://aimodels.fyi/papers/arxiv/large-language-models-can-learn-temporal-reasoning].
Overall, this paper provides a valuable theoretical foundation for understanding the reversal curse, but more research is needed to fully address the challenges posed by this phenomenon in the development of robust and reliable large language models.
Conclusion
This paper presents a theoretical analysis of the "reversal curse" observed in large language models (LLMs) trained on internet data, where the models can learn and amplify biases and factual errors over the course of the training process.
The researchers developed a simplified model of the iterative training process, showing how recursive learning from the model's own generated text can lead to the amplification of initial biases, causing the model to "reverse" and learn incorrect information [internal link: https://aimodels.fyi/papers/arxiv/curse-recursion-training-generated-data-makes-models].
While the theoretical framework provides valuable insights, the paper also acknowledges the need for further research to validate the model's predictions on real-world LLM systems and explore more comprehensive mitigation strategies [internal link: https://aimodels.fyi/papers/arxiv/regressive-side-effects-training-language-models-to].
Addressing the reversal curse is crucial for developing large language models that can reliably learn accurate information and avoid the reinforcement of biases and errors. The insights from this paper lay the groundwork for continued efforts to understand and overcome this challenge in the field of AI.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
👁️
The Reversal Curse: LLMs trained on A is B fail to learn B is A
Lukas Berglund, Meg Tong, Max Kaufmann, Mikita Balesni, Asa Cooper Stickland, Tomasz Korbak, Owain Evans
0
0
We expose a surprising failure of generalization in auto-regressive large language models (LLMs). If a model is trained on a sentence of the form A is B, it will not automatically generalize to the reverse direction B is A. This is the Reversal Curse. For instance, if a model is trained on Valentina Tereshkova was the first woman to travel to space, it will not automatically be able to answer the question, Who was the first woman to travel to space?. Moreover, the likelihood of the correct answer (Valentina Tershkova) will not be higher than for a random name. Thus, models do not generalize a prevalent pattern in their training set: if A is B occurs, B is A is more likely to occur. It is worth noting, however, that if A is B appears in-context, models can deduce the reverse relationship. We provide evidence for the Reversal Curse by finetuning GPT-3 and Llama-1 on fictitious statements such as Uriah Hawthorne is the composer of Abyssal Melodies and showing that they fail to correctly answer Who composed Abyssal Melodies?. The Reversal Curse is robust across model sizes and model families and is not alleviated by data augmentation. We also evaluate ChatGPT (GPT-3.5 and GPT-4) on questions about real-world celebrities, such as Who is Tom Cruise's mother? [A: Mary Lee Pfeiffer] and the reverse Who is Mary Lee Pfeiffer's son?. GPT-4 correctly answers questions like the former 79% of the time, compared to 33% for the latter. Code available at: https://github.com/lukasberglund/reversal_curse.
5/28/2024
Reverse Training to Nurse the Reversal Curse
Olga Golovneva, Zeyuan Allen-Zhu, Jason Weston, Sainbayar Sukhbaatar
0
0
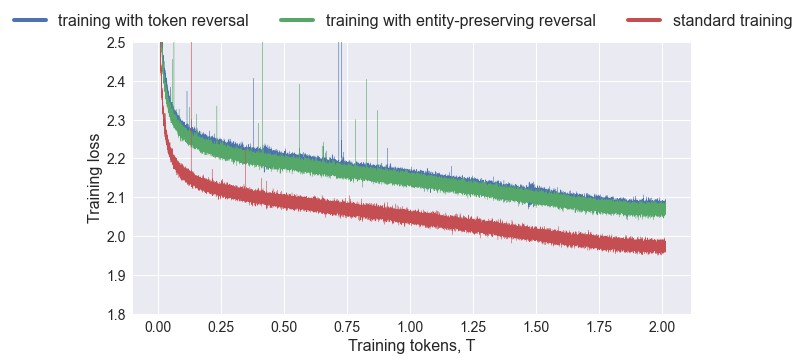
Large language models (LLMs) have a surprising failure: when trained on A has a feature B, they do not generalize to B is a feature of A, which is termed the Reversal Curse. Even when training with trillions of tokens this issue still appears due to Zipf's law - hence even if we train on the entire internet. This work proposes an alternative training scheme, called reverse training, whereby all words are used twice, doubling the amount of available tokens. The LLM is trained in both forward and reverse directions by reversing the training strings while preserving (i.e., not reversing) chosen substrings, such as entities. We show that data-matched reverse-trained models provide superior performance to standard models on standard tasks, and compute-matched reverse-trained models provide far superior performance on reversal tasks, helping resolve the reversal curse issue.
5/9/2024
📊
On Mesa-Optimization in Autoregressively Trained Transformers: Emergence and Capability
Chenyu Zheng, Wei Huang, Rongzhen Wang, Guoqiang Wu, Jun Zhu, Chongxuan Li
0
0
Autoregressively trained transformers have brought a profound revolution to the world, especially with their in-context learning (ICL) ability to address downstream tasks. Recently, several studies suggest that transformers learn a mesa-optimizer during autoregressive (AR) pretraining to implement ICL. Namely, the forward pass of the trained transformer is equivalent to optimizing an inner objective function in-context. However, whether the practical non-convex training dynamics will converge to the ideal mesa-optimizer is still unclear. Towards filling this gap, we investigate the non-convex dynamics of a one-layer linear causal self-attention model autoregressively trained by gradient flow, where the sequences are generated by an AR process $x_{t+1} = W x_t$. First, under a certain condition of data distribution, we prove that an autoregressively trained transformer learns $W$ by implementing one step of gradient descent to minimize an ordinary least squares (OLS) problem in-context. It then applies the learned $widehat{W}$ for next-token prediction, thereby verifying the mesa-optimization hypothesis. Next, under the same data conditions, we explore the capability limitations of the obtained mesa-optimizer. We show that a stronger assumption related to the moments of data is the sufficient and necessary condition that the learned mesa-optimizer recovers the distribution. Besides, we conduct exploratory analyses beyond the first data condition and prove that generally, the trained transformer will not perform vanilla gradient descent for the OLS problem. Finally, our simulation results verify the theoretical results.
5/28/2024
🏋️
The Curse of Recursion: Training on Generated Data Makes Models Forget
Ilia Shumailov, Zakhar Shumaylov, Yiren Zhao, Yarin Gal, Nicolas Papernot, Ross Anderson
0
0
Stable Diffusion revolutionised image creation from descriptive text. GPT-2, GPT-3(.5) and GPT-4 demonstrated astonishing performance across a variety of language tasks. ChatGPT introduced such language models to the general public. It is now clear that large language models (LLMs) are here to stay, and will bring about drastic change in the whole ecosystem of online text and images. In this paper we consider what the future might hold. What will happen to GPT-{n} once LLMs contribute much of the language found online? We find that use of model-generated content in training causes irreversible defects in the resulting models, where tails of the original content distribution disappear. We refer to this effect as Model Collapse and show that it can occur in Variational Autoencoders, Gaussian Mixture Models and LLMs. We build theoretical intuition behind the phenomenon and portray its ubiquity amongst all learned generative models. We demonstrate that it has to be taken seriously if we are to sustain the benefits of training from large-scale data scraped from the web. Indeed, the value of data collected about genuine human interactions with systems will be increasingly valuable in the presence of content generated by LLMs in data crawled from the Internet.
4/16/2024