The Reversal Curse: LLMs trained on A is B fail to learn B is A
2309.12288
0
71
👁️
Abstract
We expose a surprising failure of generalization in auto-regressive large language models (LLMs). If a model is trained on a sentence of the form A is B, it will not automatically generalize to the reverse direction B is A. This is the Reversal Curse. For instance, if a model is trained on Valentina Tereshkova was the first woman to travel to space, it will not automatically be able to answer the question, Who was the first woman to travel to space?. Moreover, the likelihood of the correct answer (Valentina Tershkova) will not be higher than for a random name. Thus, models do not generalize a prevalent pattern in their training set: if A is B occurs, B is A is more likely to occur. It is worth noting, however, that if A is B appears in-context, models can deduce the reverse relationship. We provide evidence for the Reversal Curse by finetuning GPT-3 and Llama-1 on fictitious statements such as Uriah Hawthorne is the composer of Abyssal Melodies and showing that they fail to correctly answer Who composed Abyssal Melodies?. The Reversal Curse is robust across model sizes and model families and is not alleviated by data augmentation. We also evaluate ChatGPT (GPT-3.5 and GPT-4) on questions about real-world celebrities, such as Who is Tom Cruise's mother? [A: Mary Lee Pfeiffer] and the reverse Who is Mary Lee Pfeiffer's son?. GPT-4 correctly answers questions like the former 79% of the time, compared to 33% for the latter. Code available at: https://github.com/lukasberglund/reversal_curse.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- Surprising failure of auto-regressive large language models (LLMs) to generalize from "A is B" to "B is A"
- This "Reversal Curse" means models trained on sentences like "Valentina Tereshkova was the first woman in space" cannot automatically answer "Who was the first woman in space?"
- Evidence for the Reversal Curse found across model sizes and families, not alleviated by data augmentation
- ChatGPT (GPT-3.5 and GPT-4) also exhibits this limitation, performing much better on "A is B" than "B is A" questions
Plain English Explanation
Large language models, which are powerful AI systems trained on vast amounts of text data, can sometimes fail to generalize in surprising ways. One such failure is the "Reversal Curse," where a model trained on sentences like "Valentina Tereshkova was the first woman to travel to space" may not automatically be able to answer the question "Who was the first woman to travel to space?"
The researchers found that even if a model has learned the relationship "A is B," it does not necessarily mean the model will understand the reverse relationship "B is A." This is the case even though this reverse relationship is a very common pattern in language. For example, if a model is trained on the sentence "Uriah Hawthorne is the composer of Abyssal Melodies," it may not be able to correctly answer the question "Who composed Abyssal Melodies?"
This "Reversal Curse" seems to be a robust phenomenon, occurring across different large language models and model sizes. It is not easily fixed by simply providing more training data or using data augmentation techniques.
The researchers also evaluated the popular ChatGPT model, which is based on GPT-3.5 and the more recent GPT-4. They found that ChatGPT exhibits this same limitation, performing much better at answering questions in the "A is B" format compared to the reverse "B is A" format. For example, ChatGPT could correctly answer "Who is Tom Cruise's mother?" but struggled with the reverse question "Who is Mary Lee Pfeiffer's son?"
This unexpected failure of large language models to generalize in this way is an important finding, as it highlights the limitations of even the most advanced AI systems and the need for continued research to improve their reasoning capabilities. Understanding and overcoming the "Reversal Curse" could lead to better-reasoning large language models that are more reliable and trustworthy.
Technical Explanation
The researchers exposed a surprising failure of generalization in auto-regressive large language models (LLMs). They found that if a model is trained on a sentence of the form "A is B," it will not automatically generalize to the reverse direction "B is A." This phenomenon, which they term the "Reversal Curse," means that a model trained on "Valentina Tereshkova was the first woman to travel to space" may not be able to correctly answer the question "Who was the first woman to travel to space?"
To demonstrate the Reversal Curse, the researchers finetuned GPT-3 and Llama-1 on fictitious statements like "Uriah Hawthorne is the composer of Abyssal Melodies" and then evaluated the models' ability to answer the reverse question "Who composed Abyssal Melodies?" They found that the models failed to correctly identify the composer, with the likelihood of the correct answer being no higher than for a random name.
This failure to generalize the reverse relationship persisted across model sizes and model families, and was not alleviated by data augmentation techniques. The researchers also evaluated ChatGPT, which is based on GPT-3.5 and the more recent GPT-4, and found a similar limitation. ChatGPT could correctly answer questions like "Who is Tom Cruise's mother?" 79% of the time, but struggled with the reverse question "Who is Mary Lee Pfeiffer's son?" at only 33% accuracy.
Critical Analysis
The researchers provided compelling evidence for the existence of the "Reversal Curse" in large language models, but there are a few potential limitations and areas for further exploration:
-
The study primarily focused on fictitious statements and celebrity relationships, which may not fully capture the complexity of real-world knowledge. It would be valuable to extend the analysis to a wider range of topics and domains to understand the breadth and generalizability of this phenomenon.
-
The researchers did not delve into the underlying reasons for the Reversal Curse. Understanding the specific architectural or training-related factors that contribute to this limitation could guide future efforts to overcome it.
-
While the Reversal Curse was observed across different model sizes and families, the researchers did not explore potential variations in the severity of the issue or possible mitigating strategies that could be employed by specific model architectures or training approaches.
-
The paper does not address whether the Reversal Curse is unique to auto-regressive language models or if it may also manifest in other types of large language models. Investigating the presence of this limitation in other model paradigms could provide valuable insights.
Overall, the researchers have uncovered an important and unexpected shortcoming in the generalization capabilities of large language models, which warrants further investigation and could lead to significant advancements in the field of natural language processing.
Conclusion
The research paper exposed a surprising failure of generalization in auto-regressive large language models, known as the "Reversal Curse." This phenomenon indicates that even if a model is trained on sentences of the form "A is B," it may not automatically be able to answer the reverse question "B is A." The researchers provided evidence for this limitation across different model sizes and families, and even found it present in the popular ChatGPT model.
This finding highlights the need for continued research to improve the reasoning capabilities of large language models, as the Reversal Curse represents a significant limitation in their ability to truly understand and generalize language patterns. Overcoming this challenge could lead to more robust and trustworthy AI systems that can better assist humans in a wide range of applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
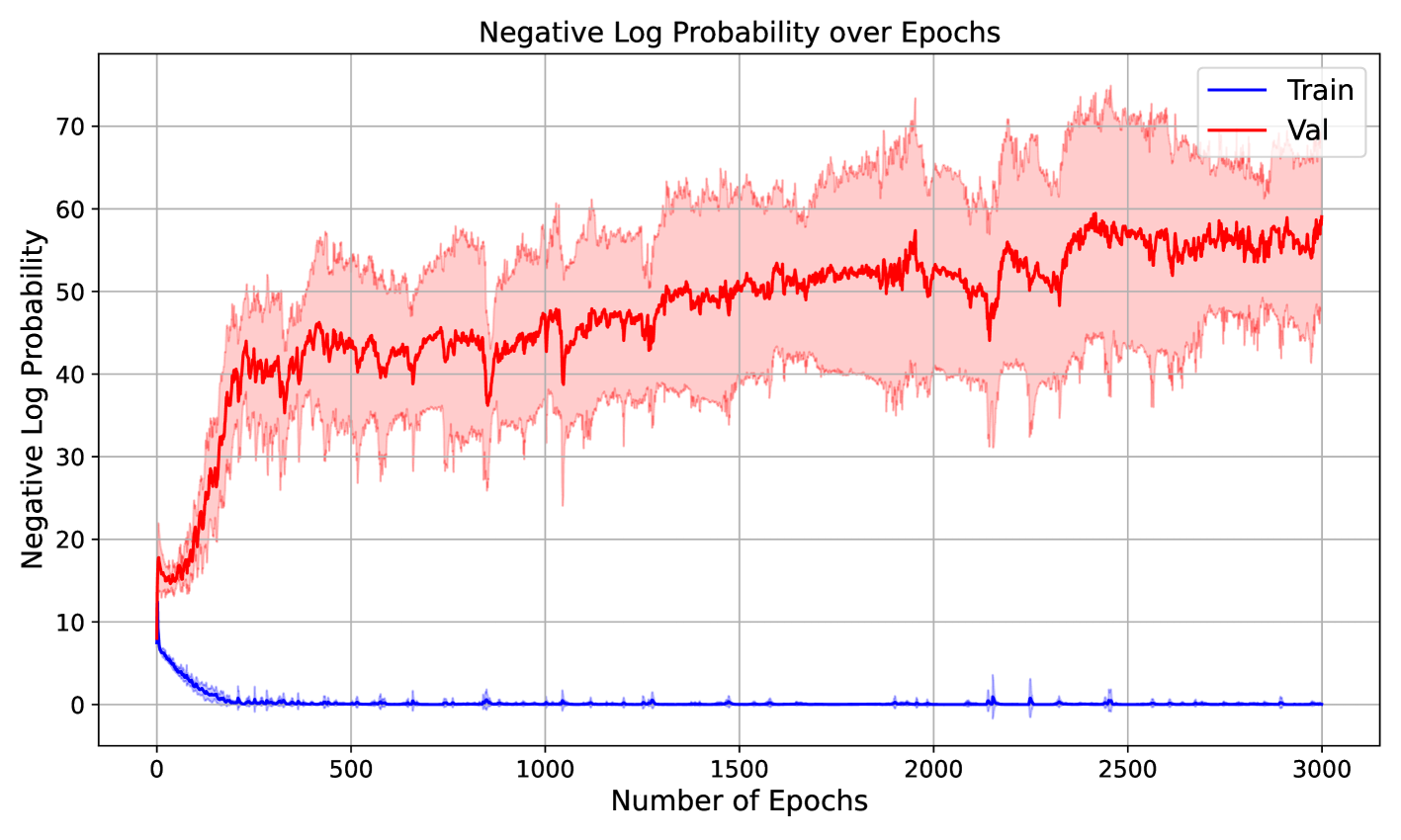
Towards a Theoretical Understanding of the 'Reversal Curse' via Training Dynamics
Hanlin Zhu, Baihe Huang, Shaolun Zhang, Michael Jordan, Jiantao Jiao, Yuandong Tian, Stuart Russell
0
0
Auto-regressive large language models (LLMs) show impressive capacities to solve many complex reasoning tasks while struggling with some simple logical reasoning tasks such as inverse search: when trained on ''A is B'', LLM fails to directly conclude ''B is A'' during inference, which is known as the ''reversal curse'' (Berglund et al., 2023). In this paper, we theoretically analyze the reversal curse via the training dynamics of (stochastic) gradient descent for two auto-regressive models: (1) a bilinear model that can be viewed as a simplification of a one-layer transformer; (2) one-layer transformers using the framework of Tian et al. (2023a). Our analysis reveals a core reason why the reversal curse happens: the (effective) weights of both auto-regressive models show asymmetry, i.e., the increase of weights from a token $A$ to token $B$ during training does not necessarily cause the increase of the weights from $B$ to $A$. Moreover, our analysis can be naturally applied to other logical reasoning tasks such as chain-of-thought (COT) (Wei et al., 2022b). We show the necessity of COT, i.e., a model trained on ''$A to B$'' and ''$B to C$'' fails to directly conclude ''$A to C$'' without COT (also empirically observed by Allen-Zhu and Li (2023)), for one-layer transformers via training dynamics, which provides a new perspective different from previous work (Feng et al., 2024) that focuses on expressivity. Finally, we also conduct experiments to validate our theory on multi-layer transformers under different settings.
5/9/2024
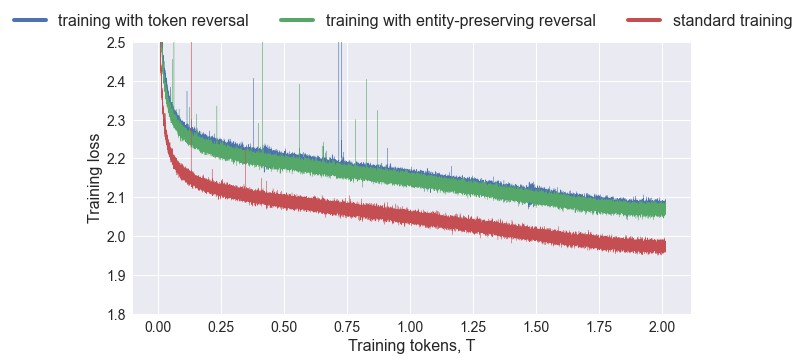
Reverse Training to Nurse the Reversal Curse
Olga Golovneva, Zeyuan Allen-Zhu, Jason Weston, Sainbayar Sukhbaatar
0
0
Large language models (LLMs) have a surprising failure: when trained on A has a feature B, they do not generalize to B is a feature of A, which is termed the Reversal Curse. Even when training with trillions of tokens this issue still appears due to Zipf's law - hence even if we train on the entire internet. This work proposes an alternative training scheme, called reverse training, whereby all words are used twice, doubling the amount of available tokens. The LLM is trained in both forward and reverse directions by reversing the training strings while preserving (i.e., not reversing) chosen substrings, such as entities. We show that data-matched reverse-trained models provide superior performance to standard models on standard tasks, and compute-matched reverse-trained models provide far superior performance on reversal tasks, helping resolve the reversal curse issue.
5/9/2024
🏋️
The Curse of Recursion: Training on Generated Data Makes Models Forget
Ilia Shumailov, Zakhar Shumaylov, Yiren Zhao, Yarin Gal, Nicolas Papernot, Ross Anderson
0
0
Stable Diffusion revolutionised image creation from descriptive text. GPT-2, GPT-3(.5) and GPT-4 demonstrated astonishing performance across a variety of language tasks. ChatGPT introduced such language models to the general public. It is now clear that large language models (LLMs) are here to stay, and will bring about drastic change in the whole ecosystem of online text and images. In this paper we consider what the future might hold. What will happen to GPT-{n} once LLMs contribute much of the language found online? We find that use of model-generated content in training causes irreversible defects in the resulting models, where tails of the original content distribution disappear. We refer to this effect as Model Collapse and show that it can occur in Variational Autoencoders, Gaussian Mixture Models and LLMs. We build theoretical intuition behind the phenomenon and portray its ubiquity amongst all learned generative models. We demonstrate that it has to be taken seriously if we are to sustain the benefits of training from large-scale data scraped from the web. Indeed, the value of data collected about genuine human interactions with systems will be increasingly valuable in the presence of content generated by LLMs in data crawled from the Internet.
4/16/2024
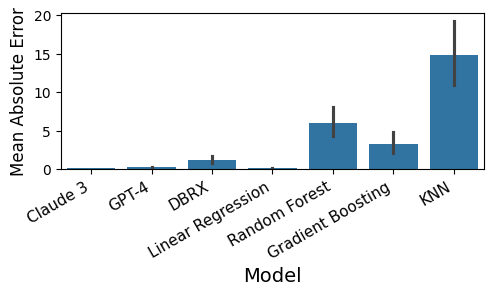
From Words to Numbers: Your Large Language Model Is Secretly A Capable Regressor When Given In-Context Examples
Robert Vacareanu, Vlad-Andrei Negru, Vasile Suciu, Mihai Surdeanu
0
0
We analyze how well pre-trained large language models (e.g., Llama2, GPT-4, Claude 3, etc) can do linear and non-linear regression when given in-context examples, without any additional training or gradient updates. Our findings reveal that several large language models (e.g., GPT-4, Claude 3) are able to perform regression tasks with a performance rivaling (or even outperforming) that of traditional supervised methods such as Random Forest, Bagging, or Gradient Boosting. For example, on the challenging Friedman #2 regression dataset, Claude 3 outperforms many supervised methods such as AdaBoost, SVM, Random Forest, KNN, or Gradient Boosting. We then investigate how well the performance of large language models scales with the number of in-context exemplars. We borrow from the notion of regret from online learning and empirically show that LLMs are capable of obtaining a sub-linear regret.
5/1/2024