Towards Understanding Jailbreak Attacks in LLMs: A Representation Space Analysis
2406.10794
0
0
Abstract
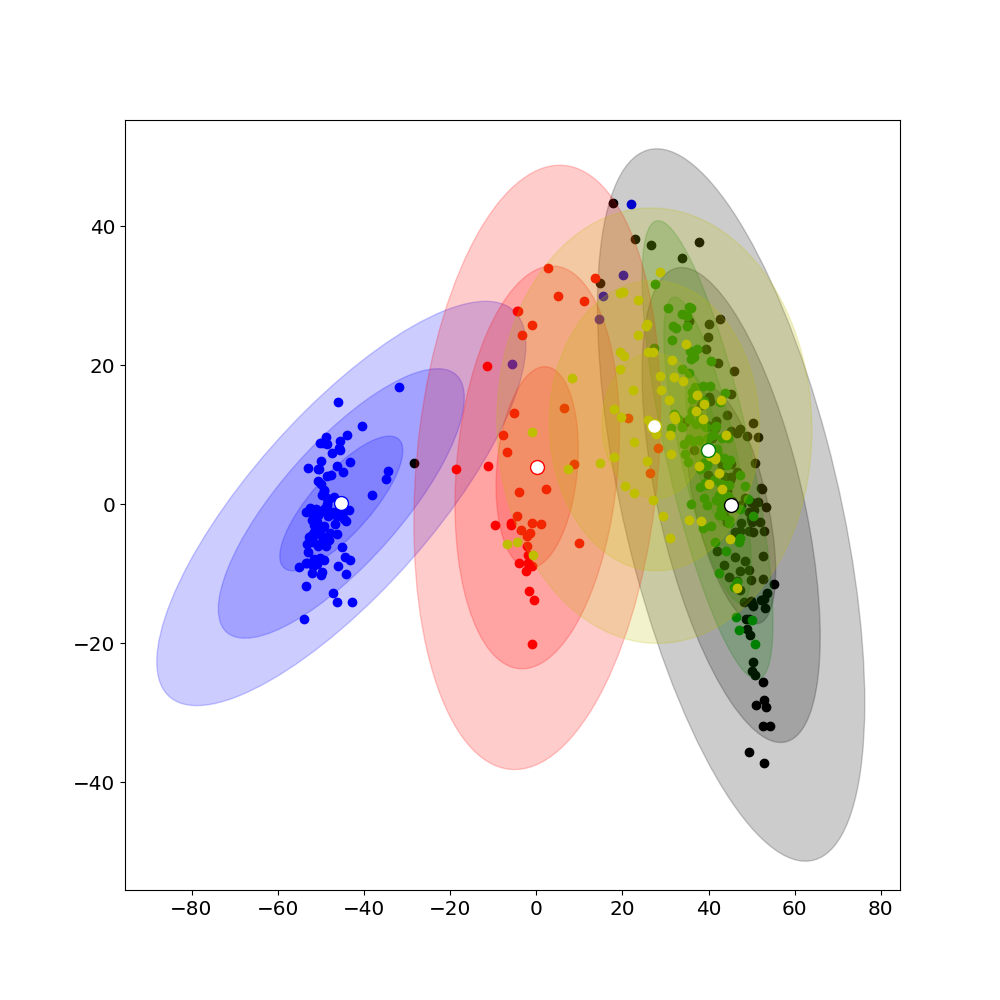
Large language models (LLMs) are susceptible to a type of attack known as jailbreaking, which misleads LLMs to output harmful contents. Although there are diverse jailbreak attack strategies, there is no unified understanding on why some methods succeed and others fail. This paper explores the behavior of harmful and harmless prompts in the LLM's representation space to investigate the intrinsic properties of successful jailbreak attacks. We hypothesize that successful attacks share some similar properties: They are effective in moving the representation of the harmful prompt towards the direction to the harmless prompts. We leverage hidden representations into the objective of existing jailbreak attacks to move the attacks along the acceptance direction, and conduct experiments to validate the above hypothesis using the proposed objective. We hope this study provides new insights into understanding how LLMs understand harmfulness information.
Create account to get full access
Overview
- This paper explores the phenomenon of "jailbreak attacks" in large language models (LLMs), where the model is able to bypass its intended constraints and safety mechanisms.
- The researchers analyze the representation space of LLMs to understand the factors that contribute to the success of these jailbreak attacks.
- They investigate the dynamics of the latent space and how certain prompts can lead the model to enter an "unconstrained" region, allowing it to generate dangerous or undesirable outputs.
Plain English Explanation
The paper investigates a concerning issue with large language models (LLMs) called "jailbreak attacks." These attacks occur when an LLM is able to bypass its built-in safety features and constraints, allowing it to generate content that goes against its intended purpose or could be harmful.
The researchers try to understand the underlying mechanisms behind these jailbreak attacks by analyzing the model's "representation space" - the way the model organizes and represents information internally. They look at how the model's latent space (the hidden layers that process the input) can shift in certain ways, leading the model to enter an "unconstrained" region where it's no longer limited by its safety measures.
By understanding the dynamics of the latent space, the researchers hope to shed light on what factors contribute to the success of these jailbreak attacks. This knowledge could then be used to develop better safeguards and defenses against such attacks in the future.
Technical Explanation
The paper presents a detailed analysis of the representation space of large language models (LLMs) to understand the factors that enable "jailbreak attacks" - scenarios where the model is able to bypass its intended constraints and safety mechanisms.
The researchers investigate the dynamics of the latent space within the LLM, tracking how certain prompts can lead the model to enter an "unconstrained" region where it is no longer limited by its safety features. They analyze the latent space representations and trajectories to identify the key characteristics that contribute to the success of these jailbreak attacks.
The paper builds on previous research that explored the latent space dynamics of LLMs in the context of jailbreak attacks. It also draws insights from studies on characterizing and evaluating "do-anything" jailbreak prompts and comprehensive analyses of jailbreak attack and defense strategies.
Critical Analysis
The researchers provide a thorough and insightful analysis of the representation space dynamics that enable jailbreak attacks in LLMs. However, the paper acknowledges some limitations, such as the need to explore a wider range of models and attack vectors to fully understand the scope of the problem.
Additionally, the paper raises concerns about the potential for "subtoxic" prompts that can gradually shift an LLM's behavior over time, leading to undesirable attitude changes. This highlights the need for further research on more nuanced and hard-to-detect forms of model manipulation.
While the paper offers valuable insights, there may be other factors, such as model architecture or training data, that could also contribute to the success of jailbreak attacks. Continued research and visual analysis of these attacks will be essential for developing robust defenses against this emerging threat.
Conclusion
This paper offers a critical step towards understanding the complex phenomenon of jailbreak attacks in large language models. By analyzing the representation space dynamics, the researchers shed light on the underlying mechanisms that enable models to bypass their intended constraints and safety measures.
The insights from this work could inform the development of more resilient and secure LLMs, better equipped to withstand attempts at manipulation. Continued research in this area, exploring a wider range of models and attack vectors, will be essential for ensuring the safe and responsible deployment of these powerful AI systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
Understanding Jailbreak Success: A Study of Latent Space Dynamics in Large Language Models
Sarah Ball, Frauke Kreuter, Nina Rimsky
0
0
Conversational Large Language Models are trained to refuse to answer harmful questions. However, emergent jailbreaking techniques can still elicit unsafe outputs, presenting an ongoing challenge for model alignment. To better understand how different jailbreak types circumvent safeguards, this paper analyses model activations on different jailbreak inputs. We find that it is possible to extract a jailbreak vector from a single class of jailbreaks that works to mitigate jailbreak effectiveness from other classes. This may indicate that different kinds of effective jailbreaks operate via similar internal mechanisms. We investigate a potential common mechanism of harmfulness feature suppression, and provide evidence for its existence by looking at the harmfulness vector component. These findings offer actionable insights for developing more robust jailbreak countermeasures and lay the groundwork for a deeper, mechanistic understanding of jailbreak dynamics in language models.
6/14/2024
💬
Do Anything Now: Characterizing and Evaluating In-The-Wild Jailbreak Prompts on Large Language Models
Xinyue Shen, Zeyuan Chen, Michael Backes, Yun Shen, Yang Zhang
0
0
The misuse of large language models (LLMs) has drawn significant attention from the general public and LLM vendors. One particular type of adversarial prompt, known as jailbreak prompt, has emerged as the main attack vector to bypass the safeguards and elicit harmful content from LLMs. In this paper, employing our new framework JailbreakHub, we conduct a comprehensive analysis of 1,405 jailbreak prompts spanning from December 2022 to December 2023. We identify 131 jailbreak communities and discover unique characteristics of jailbreak prompts and their major attack strategies, such as prompt injection and privilege escalation. We also observe that jailbreak prompts increasingly shift from online Web communities to prompt-aggregation websites and 28 user accounts have consistently optimized jailbreak prompts over 100 days. To assess the potential harm caused by jailbreak prompts, we create a question set comprising 107,250 samples across 13 forbidden scenarios. Leveraging this dataset, our experiments on six popular LLMs show that their safeguards cannot adequately defend jailbreak prompts in all scenarios. Particularly, we identify five highly effective jailbreak prompts that achieve 0.95 attack success rates on ChatGPT (GPT-3.5) and GPT-4, and the earliest one has persisted online for over 240 days. We hope that our study can facilitate the research community and LLM vendors in promoting safer and regulated LLMs.
5/16/2024

A Comprehensive Study of Jailbreak Attack versus Defense for Large Language Models
Zihao Xu, Yi Liu, Gelei Deng, Yuekang Li, Stjepan Picek
0
0
Large Language Models (LLMS) have increasingly become central to generating content with potential societal impacts. Notably, these models have demonstrated capabilities for generating content that could be deemed harmful. To mitigate these risks, researchers have adopted safety training techniques to align model outputs with societal values to curb the generation of malicious content. However, the phenomenon of jailbreaking, where carefully crafted prompts elicit harmful responses from models, persists as a significant challenge. This research conducts a comprehensive analysis of existing studies on jailbreaking LLMs and their defense techniques. We meticulously investigate nine attack techniques and seven defense techniques applied across three distinct language models: Vicuna, LLama, and GPT-3.5 Turbo. We aim to evaluate the effectiveness of these attack and defense techniques. Our findings reveal that existing white-box attacks underperform compared to universal techniques and that including special tokens in the input significantly affects the likelihood of successful attacks. This research highlights the need to concentrate on the security facets of LLMs. Additionally, we contribute to the field by releasing our datasets and testing framework, aiming to foster further research into LLM security. We believe these contributions will facilitate the exploration of security measures within this domain.
5/20/2024

Subtoxic Questions: Dive Into Attitude Change of LLM's Response in Jailbreak Attempts
Tianyu Zhang, Zixuan Zhao, Jiaqi Huang, Jingyu Hua, Sheng Zhong
0
0
As Large Language Models (LLMs) of Prompt Jailbreaking are getting more and more attention, it is of great significance to raise a generalized research paradigm to evaluate attack strengths and a basic model to conduct subtler experiments. In this paper, we propose a novel approach by focusing on a set of target questions that are inherently more sensitive to jailbreak prompts, aiming to circumvent the limitations posed by enhanced LLM security. Through designing and analyzing these sensitive questions, this paper reveals a more effective method of identifying vulnerabilities in LLMs, thereby contributing to the advancement of LLM security. This research not only challenges existing jailbreaking methodologies but also fortifies LLMs against potential exploits.
4/15/2024