TP-DRSeg: Improving Diabetic Retinopathy Lesion Segmentation with Explicit Text-Prompts Assisted SAM

0

Sign in to get full access
Overview
- This paper proposes TP-DRSeg, a method for improving diabetic retinopathy lesion segmentation by using explicit text-prompts assisted Segment Anything Model (SAM).
- The researchers explore the use of text prompts to guide the SAM model, which was originally designed for general-purpose image segmentation, to better segment diabetic retinopathy lesions.
- The paper presents experiments on several diabetic retinopathy datasets, showing that TP-DRSeg outperforms previous state-of-the-art methods for this task.
Plain English Explanation
Diabetic retinopathy is a serious eye condition that can occur in people with diabetes. It's caused by damage to the small blood vessels in the back of the eye (the retina). This damage can lead to vision problems and even blindness if not treated early.
To help diagnose and monitor diabetic retinopathy, doctors often use medical imaging techniques like fundus photography to take pictures of the retina. Analyzing these images to identify and segment the different lesions (damaged areas) is an important task, but it can be challenging.
The researchers in this paper developed a new method called TP-DRSeg that aims to improve the segmentation of diabetic retinopathy lesions in these medical images. The key idea is to use explicit text prompts to guide a machine learning model called the Segment Anything Model (SAM) [1] to better segment the relevant lesions.
By providing the model with textual descriptions of the different types of lesions, the researchers found that TP-DRSeg could segment the lesions more accurately than previous state-of-the-art methods. This could potentially help doctors better diagnose and monitor diabetic retinopathy, leading to earlier treatment and better patient outcomes.
Technical Explanation
The researchers propose TP-DRSeg, which stands for "Text-Prompts assisted Diabetic Retinopathy Lesion Segmentation". The key idea is to leverage the Segment Anything Model (SAM) [1], a powerful general-purpose image segmentation model, and guide it using explicit text prompts to improve its performance on the specific task of segmenting diabetic retinopathy lesions.
The researchers first fine-tune the SAM model on a diabetic retinopathy dataset using parameter-efficient fine-tuning techniques. They then introduce a text-prompt module that generates relevant prompts based on the input image and the target lesion type (e.g., "segment the microaneurysms in this image"). These prompts are then used to guide the SAM model to segment the lesions more accurately.
The researchers evaluate TP-DRSeg on several diabetic retinopathy datasets, including DRIVE, CHASE_DB1, and IDRiD. They show that TP-DRSeg outperforms previous state-of-the-art methods for diabetic retinopathy lesion segmentation, demonstrating the effectiveness of their approach.
Critical Analysis
The researchers have presented a novel and promising approach to improving diabetic retinopathy lesion segmentation by leveraging the power of text-prompts and the Segment Anything Model. However, there are a few potential limitations and areas for further research:
-
Applicability to other medical imaging tasks: While the researchers have demonstrated the effectiveness of TP-DRSeg on diabetic retinopathy, it would be valuable to investigate its performance on other medical imaging tasks, such as segmentation of lesions in different organs or modalities.
-
Interpretability and explainability: As with many deep learning-based methods, the inner workings of TP-DRSeg may be difficult to interpret. It would be useful to explore techniques that can provide more insights into how the text-prompts are influencing the segmentation process.
-
Robustness and generalization: The researchers should further investigate the robustness of TP-DRSeg to variations in image quality, noise, or other factors that may be encountered in real-world clinical settings.
-
Clinical validation: Ultimately, the true test of TP-DRSeg's utility will be its performance in clinical trials and its impact on patient outcomes. Close collaboration with medical professionals will be crucial to ensure the method's practical relevance and adoption.
Overall, the TP-DRSeg approach represents an exciting step forward in leveraging advanced language models and segmentation techniques to improve medical image analysis. By continuing to build on this work and addressing the potential limitations, the researchers may unlock even more powerful tools for early detection and monitoring of diabetic retinopathy and other medical conditions.
Conclusion
The TP-DRSeg method proposed in this paper demonstrates the potential of using explicit text-prompts to guide the Segment Anything Model for improved diabetic retinopathy lesion segmentation. The researchers have shown that this approach outperforms previous state-of-the-art methods, suggesting that it could be a valuable tool for early detection and monitoring of this serious eye condition.
While further research is needed to assess the broader applicability, robustness, and clinical relevance of TP-DRSeg, this work represents an important step forward in the field of medical image analysis. By combining the strengths of language models and segmentation techniques, the researchers have opened up new avenues for enhancing the diagnosis and management of diabetic retinopathy and other medical conditions.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
TP-DRSeg: Improving Diabetic Retinopathy Lesion Segmentation with Explicit Text-Prompts Assisted SAM
Wenxue Li, Xinyu Xiong, Peng Xia, Lie Ju, Zongyuan Ge
Recent advances in large foundation models, such as the Segment Anything Model (SAM), have demonstrated considerable promise across various tasks. Despite their progress, these models still encounter challenges in specialized medical image analysis, especially in recognizing subtle inter-class differences in Diabetic Retinopathy (DR) lesion segmentation. In this paper, we propose a novel framework that customizes SAM for text-prompted DR lesion segmentation, termed TP-DRSeg. Our core idea involves exploiting language cues to inject medical prior knowledge into the vision-only segmentation network, thereby combining the advantages of different foundation models and enhancing the credibility of segmentation. Specifically, to unleash the potential of vision-language models in the recognition of medical concepts, we propose an explicit prior encoder that transfers implicit medical concepts into explicit prior knowledge, providing explainable clues to excavate low-level features associated with lesions. Furthermore, we design a prior-aligned injector to inject explicit priors into the segmentation process, which can facilitate knowledge sharing across multi-modality features and allow our framework to be trained in a parameter-efficient fashion. Experimental results demonstrate the superiority of our framework over other traditional models and foundation model variants.
Read more6/26/2024
📉
0
One-Prompt to Segment All Medical Images
Junde Wu, Jiayuan Zhu, Yuanpei Liu, Yueming Jin, Min Xu
Large foundation models, known for their strong zero-shot generalization, have excelled in visual and language applications. However, applying them to medical image segmentation, a domain with diverse imaging types and target labels, remains an open challenge. Current approaches, such as adapting interactive segmentation models like Segment Anything Model (SAM), require user prompts for each sample during inference. Alternatively, transfer learning methods like few/one-shot models demand labeled samples, leading to high costs. This paper introduces a new paradigm toward the universal medical image segmentation, termed 'One-Prompt Segmentation.' One-Prompt Segmentation combines the strengths of one-shot and interactive methods. In the inference stage, with just textbf{one prompted sample}, it can adeptly handle the unseen task in a single forward pass. We train One-Prompt Model on 64 open-source medical datasets, accompanied by the collection of over 3,000 clinician-labeled prompts. Tested on 14 previously unseen datasets, the One-Prompt Model showcases superior zero-shot segmentation capabilities, outperforming a wide range of related methods. The code and data is released as url{https://github.com/KidsWithTokens/one-prompt}.
Read more4/12/2024
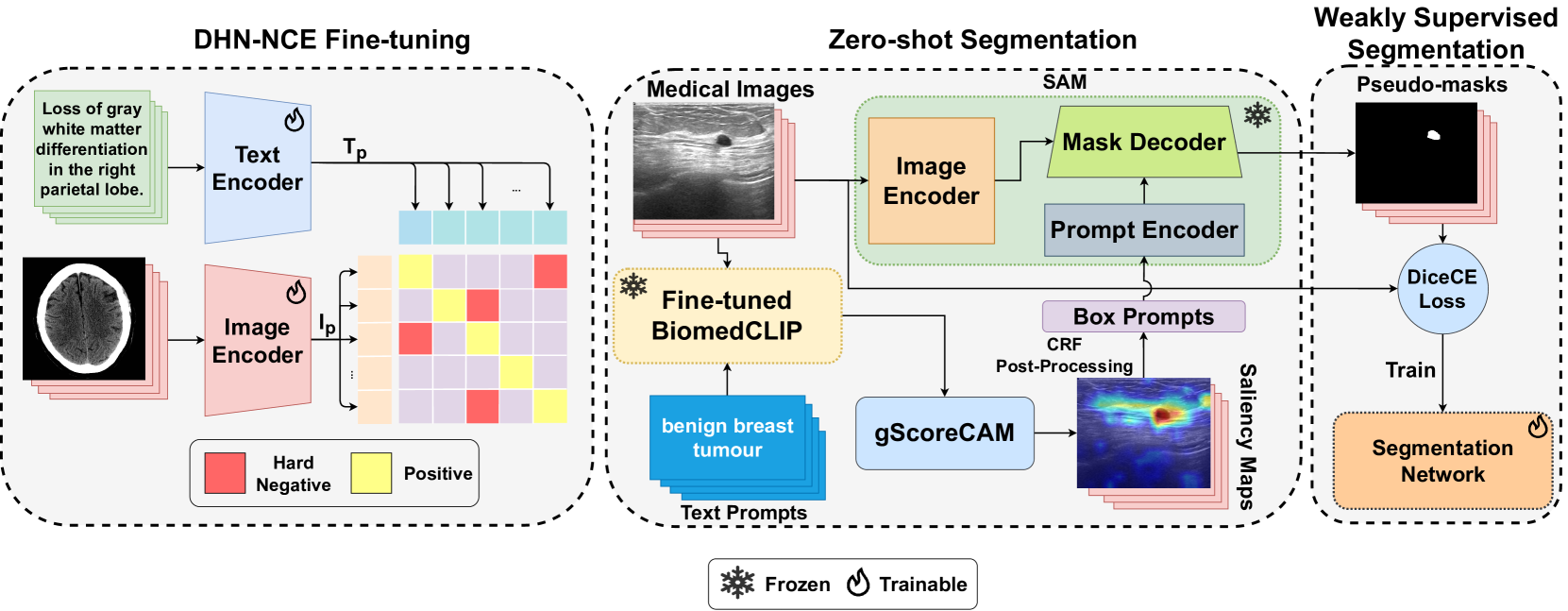
0
MedCLIP-SAM: Bridging Text and Image Towards Universal Medical Image Segmentation
Taha Koleilat, Hojat Asgariandehkordi, Hassan Rivaz, Yiming Xiao
Medical image segmentation of anatomical structures and pathology is crucial in modern clinical diagnosis, disease study, and treatment planning. To date, great progress has been made in deep learning-based segmentation techniques, but most methods still lack data efficiency, generalizability, and interactability. Consequently, the development of new, precise segmentation methods that demand fewer labeled datasets is of utmost importance in medical image analysis. Recently, the emergence of foundation models, such as CLIP and Segment-Anything-Model (SAM), with comprehensive cross-domain representation opened the door for interactive and universal image segmentation. However, exploration of these models for data-efficient medical image segmentation is still limited, but is highly necessary. In this paper, we propose a novel framework, called MedCLIP-SAM that combines CLIP and SAM models to generate segmentation of clinical scans using text prompts in both zero-shot and weakly supervised settings. To achieve this, we employed a new Decoupled Hard Negative Noise Contrastive Estimation (DHN-NCE) loss to fine-tune the BiomedCLIP model and the recent gScoreCAM to generate prompts to obtain segmentation masks from SAM in a zero-shot setting. Additionally, we explored the use of zero-shot segmentation labels in a weakly supervised paradigm to improve the segmentation quality further. By extensively testing three diverse segmentation tasks and medical image modalities (breast tumor ultrasound, brain tumor MRI, and lung X-ray), our proposed framework has demonstrated excellent accuracy. Code is available at https://github.com/HealthX-Lab/MedCLIP-SAM.
Read more6/21/2024

0
ESP-MedSAM: Efficient Self-Prompting SAM for Universal Domain-Generalized Medical Image Segmentation
Qing Xu, Jiaxuan Li, Xiangjian He, Ziyu Liu, Zhen Chen, Wenting Duan, Chenxin Li, Maggie M. He, Fiseha B. Tesema, Wooi P. Cheah, Yi Wang, Rong Qu, Jonathan M. Garibaldi
The universality of deep neural networks across different modalities and their generalization capabilities to unseen domains play an essential role in medical image segmentation. The recent Segment Anything Model (SAM) has demonstrated its potential in both settings. However, the huge computational costs, demand for manual annotations as prompts and conflict-prone decoding process of SAM degrade its generalizability and applicability in clinical scenarios. To address these issues, we propose an efficient self-prompting SAM for universal domain-generalized medical image segmentation, named ESP-MedSAM. Specifically, we first devise the Multi-Modal Decoupled Knowledge Distillation (MMDKD) strategy to construct a lightweight semi-parameter sharing image encoder that produces discriminative visual features for diverse modalities. Further, we introduce the Self-Patch Prompt Generator (SPPG) to automatically generate high-quality dense prompt embeddings for guiding segmentation decoding. Finally, we design the Query-Decoupled Modality Decoder (QDMD) that leverages a one-to-one strategy to provide an independent decoding channel for every modality. Extensive experiments indicate that ESP-MedSAM outperforms state-of-the-arts in diverse medical imaging segmentation tasks, displaying superior modality universality and generalization capabilities. Especially, ESP-MedSAM uses only 4.5% parameters compared to SAM-H. The source code is available at https://github.com/xq141839/ESP-MedSAM.
Read more8/20/2024